Salient Object Detection via Structured Matrix Decomposition
标题是一篇关于显著对象检测的论文,内容是我关于这篇文章的一个翻译和总结。
在显著对象检测方面,低秩复原模型表现出很大的潜力。低秩表示模型,即把观测矩阵分解为一个低秩矩阵和一个稀疏矩阵,其中低秩矩阵代表图像的背景,稀疏矩阵表示图像上的显著性对象,但是低秩复原模型仍有两个主要的缺陷:1)先前的工作中总是假设稀疏矩阵中的元素是相互独立的,因此忽略了图像区域在空间和模式上的联系;2)当低秩矩阵和稀疏矩阵比较相似的时候(也就是说低秩的同时也较为稀疏,稀疏的同时也较为低秩),传统的低秩复原模型很难将低秩矩阵和稀疏矩阵区分开来。为了解决上面提到的问题,本文提出了带有两个结构化正则化项的结构化矩阵分解模型:1)树形结构诱导范数用来捕捉图像结构信息,同时使来自同一个物体(这里应该理解成显著性区域)的图像快有相似的显著性值;2)拉普拉斯正则化项用来增大显著对象(前景)和背景之间的距离。同时模型整合了高层次的先验知识来指导矩阵分解,提高前景检测水平。
传统的低秩复原模型为:(显著性、显著物体、显著性区域、前景这几个词在本文中意义等价,文中后面也将显著性区域称为foreground前景,与背景background相对应)
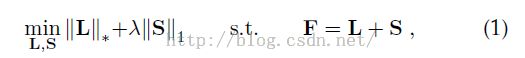
其中L代表低秩矩阵(对应着背景区域),S代表稀疏矩阵(对应着前景区域)。尽管这个模型在一些地方取得了不错的效果,但仍然存在着几个问题:
1)先前的研究并未考虑S中元素之间的关系,换句话说,先前的研究对前景矩阵中的元素默认为是相互独立的,互不影响的,因此忽略了图像像素或图像块之间空间上的连续性和模式上的相似性。这就导致了两方面的问题:i)由这个模型产生的前景是离散的,不连续的,支离破碎的;ii)属于同一个前景区域的显著性值不一致,导致对显著对象的检测不完整(其实和i中的问题差不多);
2)根据RPCA的思想,当潜在的低秩矩阵和稀疏矩阵有较大相似度的时候,分解的能力就下降的厉害。也就是说,当背景和前景外观较为相似的时候,先前的低秩分解模型很难从原始矩阵中分解出低秩矩阵和稀疏矩阵。
为了解决上述问题,本文提出了结构化矩阵分解的模型,将前景背景的分离问题转化为低秩矩阵和结构化稀疏矩阵分解问题。此模型对公式1代表的传统的低秩模型做了两方面的加强。1)提出了树形结构稀疏诱导范数来约束前景矩阵S,从而将显著图像块空间上的联系和特征上的相似性考虑进矩阵问题中。这个约束是定义在树形结构上的一种层次群组稀疏范数,用无穷范数来确保同一个显著对象图像块拥有相同的显著性值;2)引进拉普拉斯正则化项来降低低秩矩阵和结构化稀疏矩阵之间的相似性。这个正则化项考虑图像的几何结构,局部不变性的观点认为局部相似的图像块有相似的表示形式,从而尽可能地将前景和背景区分开来。这些性质使提出来的SMD模型在复杂场景甚至是前景和背景外观相似的情况下依然能实现很好的前景检测。另外,SMD模型也增强了前景的完整性,这在先前的研究中有时候很难做到。
这篇文章的主要贡献总结起来有两点:
1)提出了结构化矩阵分解的模型,不仅能捕捉矩阵潜在的结构,还能很好的解决前景和背景外观相似难以分离的问题,且基于ADM算法提出了很好的模型求解算法;
2)做了基于SMD的显著性对象检测的框架,在已有的数据集上表现很好。
相关工作部分我不做过多的介绍,简单说一下里面提到的“重点”内容。首先是manifold ranking,即流形排序,这个我也不懂,但文中提到提出的拉普拉斯正则化是流形排序的启发,有时间可以找来原文看一看。文中的拉普拉斯正则化用来平滑特征表示和增大前景和背景在特征空间上的距离。
模型详解
1.基本的形式化
给定一幅输入图像,首先分割为N个图像块(Patch),每个图像块抽取D维特征从而组成最初的特征矩阵F(D*N维),提出的结构化矩阵分解模型如下:
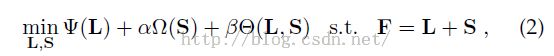
模型中的三项分别对应低秩约束,结构化稀疏约束和拉普拉斯正则化项。
2.图像背景的低秩约束
背景的低秩约束是很自然的,背景嘛,长得都一样,其对应的矩阵理所当然的是低秩的了。注意rank()函数是非凸的,直接求解是一个NP难问题,故将其松弛到核范数以方便模型求解。
3.前景的结构稀疏正则化(这是本文的亮点!!!)
在公式1传统的低秩模型中采用l1范数来约束S中的每一列(前景矩阵,Salient简写为S,方便记忆),忽略了空间结构信息,而空间结构信息正好可以用来提高显著对象检测水平(这对我也有启发,看别人论文的时候就努力去发现被人文中没考虑到的内容,别人没考虑到的内容很可能是自己可以用来改进的地方,虽然目前我也没有paper...)。首先给出索引树的定义,看图:
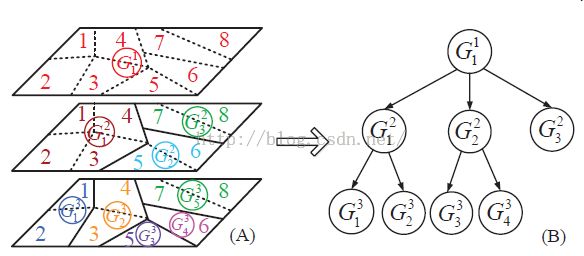
这里可以这样理解,根节点索引所有的图像块,如G11实际上对8个图像块都能索引,我理解的索引就是“包含着,指向着”。为什么是层次结构呢?看A图的中间部分,这里由上面的只有一个G11变成 了有3个分别是G21,G22,G23,其中G21索引1234这几个图像块,G22索引56图像块,依次类推。开始我比较迷惑的地方是这个索引或者说谁索引谁是怎么建立的呢?这是一个现成的算法,参照《Efficient graph-based image segmentation》一文可建立上面的树形结构,显然这也是层次结构一层一层的,同一层节点相交为空,同一层所有节点的并组成上一层的父节点。有了上述的索引树,从而定义了树形稀疏正则化项:
v是对应于节点Gij的权重,SGij是节点Gij对应于S的子矩阵,举个例子这样理解:G22在上面的索引树图中索引着图像块5和图像块6,在基本形式化部分讲到了首先将输入图像分割为N个图像块,每个图像块抽取D维特征从而组成了一个D*N的特征矩阵,这里的G22对应着两个图像块,也就是特征矩阵中的两列,所以SG22就是指的是特征矩阵中图像块5和6对应的两列。这里还有一个问题,权重v是如何定义的呢?在文章后面才提到,这也是文中的一个亮点,整合了先验知识定义了v,具体参照《A unified approach to salient object detection via low rank matrix recovery》一文。在后面的模型中p范数实际上是采用了p等于无穷(矩阵的无穷范数是指矩阵的每一行元素绝对值之和的最大值)也就是最大的“显著性值”来确定Gij索引的部分是否属于前景区域。要注意到公式5中i和j的求和范围,d表示数的深度或者说层次,比如说图中对应的d=3。它是对每一层每一个节点都进行了一个加权取范数求和,这样做的目的是什么呢?比如说公式5进行到了G21部分,这时候G21索引这4个图像块,可能这4个图像块并不都属于前景,这时候取范数部分的值不会特别大(意思是说G21不太可能是显著性部分,因为我前面假设它4个图像块不都属于前景),因为最终的模型是一个最小化问题,这时候我就给它一个大的权重来惩罚它;然后我持续这个过程到了G21的子节点G31和G32,假如G31全部是前景G32全部是背景然后加权取范求和,会发现实际上这个正则化项实现了一个更为“精准”的分割,它使S更“完整”地包含显著性区域,即前景部分。(这一块我描述的也不是特别清楚,可粗略理解为这样做的目的就是解决了传统的低秩模型很难分离分离出来的前景不完整、支离破碎的问题吧)
4.拉普拉斯正则化项
这一部分很好理解,就是为了解决前景背景较为相似的问题,通过一个交互正则化项增大稀疏矩阵和低秩矩阵之间的gap(可理解为距离,差别)。这里也有一个亮点,它是通过原始的特征矩阵F来增大了L和S之间的距离,就是这个式子,原文中紧接着一句话翻译过来是这样的“拉普拉斯正则化项根据特征矩阵(F)局部不变(邻居)来平滑S中的向量从而增大特征空间之间的距离,很拗口啊。。。
模型求解部分我就不说了,有些证明我也不太理解,ADM等算法参照林宙辰老师的一系列牛文!
最后在低层次前景检测部分step4 Saliency Assignment通过向量的1范数(各分量绝对值之和)定义了一个显著性估计函数,函数较大的返回值意味着si对应的最初的第i个图像块有较大的可能是前景,这里应该也设置了一个阈值,当认为大于阈值的时候就认为是前景了。这里应该要这样理解,并非S(稀疏结构化矩阵)直接对应着前景区域,应该是通过S这一个稀疏结构化矩阵映射到最初由图像块组成的矩阵,从而最终确定哪些是显著性区域哪些是背景区域!这和普通的稀疏矩阵直接对应前景是不同的!之前我竟然也没有注意到这一点!把原文中的图贴过来再看看这个过程!
这篇paper到这里基本就结束了,至于实验效果没什么可说的,反正作者说还不错!另外,我也要感激一下原文作者,对我提问的邮件做了很好的回答。不知道为什么作者回应我说代码并没有开源,但我千辛万苦的找到了对应的代码,可这里下载,注:我只是提供了链接,版权归原作者所有!
http://www.dabi.temple.edu/~hbling/SMD/SMDCode.html