[置顶] FDDL(Fisher discrimination dictionary learning)学习
本文是对张磊博士发表在2011年发表早ICCV会议上关于具有识别力字典论文的讲解。论文和附录论文的代码地址链接为:http://www4.comp.polyu.edu.hk/~cslzhang/papers.htm
一、概述
论文在提出自己的核心思想之前对字典学习的脉络进行了一个梳理,第一阶段是SRC(spares representation based classification)算法的提出,此算法将训练样本作为字典,存在的字典的噪声过大、字典过于完备导致运算量过大运算时间过长和字典的识别力无法体现出来等缺陷。第二阶段是DKSVD(discriminative KSVD)算法的提出,此算法虽然对字典的使用发生了改变,但是仍然无法体现出字典的识别力。第三阶段是学习出了一个具有识别力的字典,并且能够用重构误差进行分类,相对于FDDL算法来说效果逊色了点。FDDL在提出了字典的识别力的同时也对编码的识别力进行了研究。
二、补充知识
(1)Fisher discrimination criterion (费舍尔判别准则)
其思想是:投影,使多维问题转化为低维问题来进行处理。选择一个适当的投影轴,使所用的样本点都投影到这个轴上得到投影值,使得同一类样本所形成的投影值的距离尽量的小,而不同类之间的投影值距离尽可能大。如下图所示:
衡量上文基本参量:
(1)各类样本均值向量:

(2)样本类内离散度矩阵:
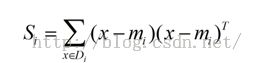
(3)样本类间离散度矩阵 :

(2)SRC(spares representation based classification)
稀疏编码模型:
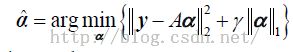
其中y为测试样本 ,A=[A
1
,A
2
......A
n
]为有不同训练样本组成一个字典。
分类模型:

三、FFDl模型的介绍
上文已经提到FDDL提出字典的识别力同时也对编码的识别力进行了研究。
整体的模型:

第一项为Discriminative fidelity term,主要通过它来体现字典的识别力。第二项为稀疏保证项,来体现编码的稀疏性。第三项为Discriminative coefficient term,主要通过它来保证编码的识别力。下面分别从第一、三项对以上模型进行讨论。
(1)字典的识别力
下图是整个模型的图解:
X
1
是A
1
在D下对应的编码,X
1-1
是A
1
在D
1
下对应的编码。
以A
1 可知其表达式: A1
=D
1
*X
1-1
+D
2
*X
1-2
+D
3
*X
1-3
=R
1
+R
2
+R
3.............................................(1)
从感性的角度来看:字典的识别力应该体现在X1-1、X1-2、X1-3的稀疏度上,由于X1-1是A1对应于D1的编码,所以可知X1-1的稀疏度应该相对于X1-2、X1-3的系数度应该小。
从理性的角度来看:公式(1)可知A1是由R1、R2、R3的向量组合成。而R1应该在组成A1是占用的比例应该比较大。首先要有能形成公式(1),必须保证重构误差即存在公式如下:
其所对应的向量组合图如下:
![[置顶] FDDL(Fisher discrimination dictionary learning)学习_第1张图片](http://img.e-com-net.com/image/info5/f254f732d3ce4cc3b606403f5cb30292.jpg)
由上图可知,虽然能保证对字典的重构可是R
i
的比例占比较少无法体现字典的识别力。
于是将A
i
对应的编码的比重加大,即将R
i
的长度增加,提出了下式:

将其与上式组合以后得:
其所对应的向量组合图如下:
可知与上图相比R
i
的比重明显变大,但是仍然存在的问题是,可能R
i
所占的比重还不是最大,于是添加如下公式:
将其与上式组合以后得:
其所对应的向量组合图如下
:![[置顶] FDDL(Fisher discrimination dictionary learning)学习_第2张图片](http://img.e-com-net.com/image/info5/5f3e70cd3e004d63a857390b941b8d02.jpg)
至此得到
解决了字典的识别力的问题。
(2)编码的识别力
编码的识别力主要体现在整体模型的第三项。
主要思想是:使得类内样本的编码离散度减小,而使得类间样本的编码离散度增大。
类内样本的编码离散度:
类间样本的编码离散度:
可知第三项的表达式为:
(三)整体模型求解过程
整体模型的表达式如下:
求解步骤:(1)固定字典D,更新编码X。所用的模型如下:
![[置顶] FDDL(Fisher discrimination dictionary learning)学习_第3张图片](http://img.e-com-net.com/image/info5/0e53149b144d49cda32d1745654bdc5c.jpg)
(2)固定编码X,更新字典D。所用的模型如下:
求解流程图如下:
![[置顶] FDDL(Fisher discrimination dictionary learning)学习_第4张图片](http://img.e-com-net.com/image/info5/a4fc1f37a8154e04a172a3c97797237f.jpg)
Appendix B中是对IMP(Iterative Projection Method)算法的介绍,这里只附录简单的介绍:
(IMP算法链接http://dspace.mit.edu/bitstream/handle/1721.1/30972/2/MIT-CSAIL-TR-2006-007.pdf)
整体模型优化的算法流程图中提及的文献【13】是对字典的更新方法,文献【13】的附录如下:(http://citeseerx.ist.psu.edu/viewdoc/download?doi=10.1.1.297.7226&rep=rep1&type=pdf)