Augmenting CRFs with Boltzmann Machine Shape Priors for Image Labeling学习笔记
文章主要是解决图像标注的问题,作者挑了一个比较偏的标注问题——对人脸进行标注。方法采用CRF(Conditional Random Fields)与RBM(Restricted Boltzmann Machine)混合的方法,前者用来解决图像局部的相互关系,后者用来解决图像的全局形状。一张图片来解释它到底要干什么
最左边是一张背景不是很干净的人脸图片,这张照片经过预处理,过分割之后(中间图片),套用作者的GLOC算法,得到最后的分割结果,分割结果主要是三个部分——毛发(包括胡子)、面部,背景,如果脖子可见的话也会有脖子(最右边图片)。
详细方法介绍如下,CRF的优势就在于结构化的输出预测比如语言理解、以及图像分割,传统的条件概率和能量函数定义如下: Y代表最终的label,X代表输入特征。要做的呢就是求条件概率的log最大似然
Y代表最终的label,X代表输入特征。要做的呢就是求条件概率的log最大似然
RBM呢可以用在降维、分类以及特征学习等,传统的联合分布定义如下: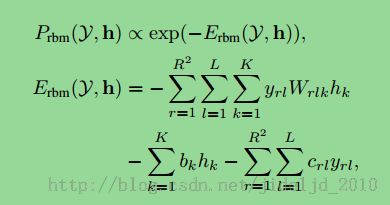 h为隐藏节点,Y为可见节点也是最终的label。与CRF类似求log最大似然
h为隐藏节点,Y为可见节点也是最终的label。与CRF类似求log最大似然
而作者的GLOC呢,初始想法比较简单,就是二者的组合,这样可以一定程度的利用RBM产生的形状先验,公式如下: 光这样是不行的,因为RBM要求节点的输入为RxR的规则的输入,而预处理分割后的图片不一定是规则的,因此作者引入了一个pooling的层,效果如下图
光这样是不行的,因为RBM要求节点的输入为RxR的规则的输入,而预处理分割后的图片不一定是规则的,因此作者引入了一个pooling的层,效果如下图 变化就是yrl不再是0或者1而是在0到1之间的小数代表某个区域有多少属于某个label。
变化就是yrl不再是0或者1而是在0到1之间的小数代表某个区域有多少属于某个label。
实验的数据库为LFW(Labeled Faces in the Wild)意思就是包含一定噪声的人脸图片,更接近于现实生活中的情况 最后来几张实验结果图
最后来几张实验结果图 每幅图的蓝色区域最右边为作者的实验效果,最右边为失败的情况。
每幅图的蓝色区域最右边为作者的实验效果,最右边为失败的情况。
总结:采用CRF与RBM结合,解决了CRF不能处理全局信息的缺点,表现非常不错。同时将这种label的方法用在人脸中,在一定程度上揭示了人脸的潜在信息特征,比如在如下图中 第一列蓝色表示没有头发的情况,第二列表示头向左转,第三列表示头向右转等等。
第一列蓝色表示没有头发的情况,第二列表示头向左转,第三列表示头向右转等等。
缺点就是输入并非原始图片而是经过过分割的图片,效果非常依赖过分割的好坏,同时作者也没有讲过分割采用的是什么算法。不能保证在除人脸之外的物体分割及标注上有好的结果,可以考虑加入domain adaptation。