DirectIO时的IO放大探究【io主文--逻辑块映射物理块,io请求合并分割】
DirectIO时的IO放大探究
(DirectIO时额外多出来的IO个数的原因之探究)
现象
前段时间在对我们自己开发的文件系统测试(程序)过程中发现一个有趣的现象:IO放大。测试现象描述如下:
- 现象1:iostat –x /dev/sdh1,观察发现每秒完成的读请求次数100+,而测试程序统计的实际IOPS为50,约为iostat统计数据的一半;
- 现象2:cat /sys/block/sdh1/stat发现测试程序运行过程中,该设备被读的数据量为77292KB,而测试程序实际读数据量为40000KB。
(对读取一个文件时进行io的测试:
现象1中,iostat测试的IOPS为100多,测试程序测试的IOPS为50,约为iostat统计数据的一半。iostat测试出来的IOPS减去测试程序测试的IOPS所得的io个数就是所谓的额外IO。为什么会这样?因为读取一个文件时,会读取文件的数据块和索引块,iostat对读取这两类块的io都会测试到,而测试程序只是会对读取数据块的io进行测试。
现象2中,cat测试的该设备(指的是磁盘)被读的数据量为77292KB,测试程序测试的读取的数据量为40000KB。cat测试的数据量减去测试程序测试的数据量所得的数据量差就是所谓的额外IO。为什么会这样?因为读取一个文件时,会读取文件的数据块和索引块,cat对读取这两类块的io都会测试到,而测试程序只是会对读取数据块的io进行测试。)
我们会在下面的两个测试以及原理分析中揭示这些额外IO来自何方。
测试1:不同offset读文件测试
测试目的
测试ext3文件系统元数据(索引块)对文件读性能影响
测试方法
顺序读数据目录(500个1GB大小文件)所有文件,每个文件读一次,每轮测试中读文件offset一致,一共执行五轮,offset分别为32KB,48KB,64KB,1GB-40KB,每轮测试之前清空缓存(echo 3 > /proc/sys/vm/drop_caches),使用O_DIRECT方式读,每次读4KB。
测试结果
图1 不同offset读IOPS
表1 不同offset读数据量对比
| 读offset | 测试前已读扇区 | 测试后已读扇区 | 测试读扇区数 | 实际读数据量(KB) | 预期读数据量(KB) |
| 32K | 210448943 | 210453455 | 4512 | 2256 | 2000 |
| 48K | 210453829 | 210462271 | 8442 | 4221 | 2000 |
| 64K | 210462423 | 210470887 | 8464 | 4232 | 2000 |
| 1G-40K | 201484183 | 210496655 | 12472 | 6236 | 2000 |
结论
上面的测试较为有力地解释了ext3文件系统元数据(主要指索引块)对杜性能影响。在元数据缓存未命中情况下,读文件offset越大,产生额外IO越多,IOPS越低。
测试2:元数据缓存性能测试
测试目的
测试ext3文件系统元数据(主要指索引块)缓存与否对文件读性能影响
测试方法
顺序读数据目录下所有文件(500个,每个大小为1GB),每个文件只读一次,offset为1GB-40KB(根据计算,ext3此时使用二级间接索引)。测试共执行两轮,第一轮测试之前清cache,第二轮测试之前不清理cache,使用O_DIRECT方式读,读大小4KB。
测试结果
表2 有无元数据缓存读写性能对比
| 测试场景 | IOPS | 实际读数据量(KB) |
| 测试1(无缓存) | 37 | 6228 |
| 测试2(有缓存) | 64 | 2008 |
结论
该测试对比了ext3文件系统元数据缓存与否对读性能影响,元数据未缓存情况下,产生的额外IO越多,IOPS越低。而且,因为每次读偏移位于二级索引,需要两次额外的元数据IO,每个索引块大小为4KB,所以实际读出数据量应该为期望读数据量的三倍,与测试结果较吻合。
原理分析
为了进一步弄清楚这个问题,我们本着打破砂锅问到底的精神,翻阅了Linux内核代码,看看文件系统direct方式读的实现,需要说明的是我们使用的内核代码版本为3.12。
在代码分析之前,先来普及一个概念:文件系统和底层块设备都有自己的块大小设置,而且,这两者可以不相同。块设备的默认块大小为512字节,有兴趣的可以自己查看下hd_init()这个函数。文件系统,如ext3,默认块大小是1024字节(可以自己挂载文件系统的时候设置,但最小1024字节,最大为PAGE_SIZE),有兴趣的同学可以自己查看下ext3_fill_super()这个函数。因此一般说来,文件系统块大小是块设备默认大小的整数倍,明白这个对理解后面的实现比较重要。
另外,我们看看direct方式读接口参数需要注意的几点,read接口形式为:
read(fd, buffer, size)
注意:
- buffer需要对齐,对齐的单位是块大小,按照文件块大小或者设备块大小对齐均可,可通过函数posix_memalign()来分配按照一定粒度对齐的缓冲区;
- 读偏移offset必须以文件或者设备块大小对齐;
- 读大小size必须以文件或者设备块大小对齐;
- 上述只要有一点不满足,调用失败,返回错误信息为”Invalid argument”。
同样,我们通过情境分析的方式来分析实现,要不显得实在是枯燥,假如我们读的调用形式为 read(fd, buffer, 4096)
其中,buffer以1024字节对齐,分配的buffer地址为0X804a400,offset从0开始。
跟着代码深入,文件系统的read最终会进入函数generic_file_aio_read()。因为本文只讨论direct IO方式的读,因此我们只关注以下部分代码(mm/filemap.c):
if (filp->f_flags & O_DIRECT) {
……
if (!retval) {
retval = mapping->a_ops->direct_IO(READ, iocb, iov, pos, nr_segs);
}
……
}
看看代码,发现核心是调用了具体文件系统的directIO实现,对于ext3文件系统来说,是ext3_direct_IO()。接下来,以此为起点,我们一路向西,跟踪调用流程:
ext3_direct_IO—>blockdev_direct_IO—>__blockdev_direct_IO—>do_blockdev_direct_IO。我们从do_blockdev_direct_IO开始分析,忽略前面几者是因为他们只是对下一层的简单封装,不值得浪费笔墨。由于代码较长,我们不堆砌代码,只是列举若干注意事项:
- 检查参数对齐与否。offset、buffer_addr、size必须全部过一遍。首先会判断是否与文件系统块大小对齐,如果否,则判断是否和块设备的块大小对齐,如果均不满足,那可以直接报错了。另外,如果参数不以文件块大小对齐却以设备快大小对齐,代码中会记录差异因子是1(10 – 9);
- 计算总共需读出的页面数。这里需要注意一点:页面数必须以PAGE_SIZE对齐,并非简单的size/PAGE_SIZE(size为应用程序想要读出的总的字节数)。拿本例来说,虽然size为4096字节,但计算需要读出的页面数却是2,如下图所示:
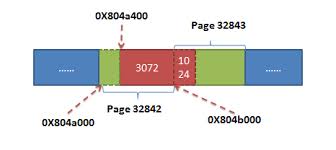
之所以这样是因为内核的文件IO均以PAGE_SIZE对齐。所以,如果应用程序分配的内存并非以PAGE_SIZE对齐(如我们分配的空间0X804a400就是以1024字节对齐),则IO可能会跨越多个PAGE。
- 在directIO实现中,有两个结构体扮演了非常重要的角色,struct dio和struct dio_submit。一些关键成员变量的含义如下:
- dio_submit.pages_in_io:本次IO共有多少PAGE,本情境中为2;
- dio_submit.first_block_in_page:IO操作的第一个块在页面中的偏移,本情境中为1;
- dio_submit.final_block_in_request:本次IO请求的最后一个块号,本情境中为4;
- dio_submit.total_pages:本次IO请求共有多少个PAGE,本情境中为2;
- 该函数实现上是一个循环:对应用程序传入的每个seg(应用程序一次课发多个IO segment),初始化dio_submit的某些参数,然后调用do_direct_IO()。
接下来让我们忘掉该死的do_blockdev_direct_IO(),进入更可恶的do_direct_IO()。来看看是如何执行directIO的。因为篇幅的关系我们同样不罗列代码,只是看看该函数的实现有哪些关键点。
- 上例中,应用程序提供的缓冲区跨越两个页面(page 32842的1024~4096以及page 32843的0~1024)。但再次请读者注意的是:我们底层的IO一般以page为单位组织,所以我们需要根据用户态的缓冲区地址找到page结构,这便是该函数第一个需要注意的地方page = dio_get_page(dio, sdio);将用户态缓冲区地址转化为page
- 接下来,我们的主要任务就是挽起袖子读数据了,不过等等,好像我们还忘记了一件事:我们这里读的全是逻辑块号,我们从底层读之前还需要将逻辑块号转化成物理块号,映射的方法因文件系统而异了,在这里很可能会产生额外的IO,在这里我们不关心具体文件系统的映射方法了,有兴趣的朋友可移步这里,有ext3映射方法实现的详细描述。需要的是:内核会尽可能多地进行映射,但底层返回的映射结果只能映射从起始逻辑块号连续的若干磁盘块,这很有可能会小于内核的需求。再拿本例来说,内核肯定是想一下把所有的想读的逻辑块地址全映射了,但实际上文件系统在实现的时候不一定能保证这些逻辑块在磁盘上完全连续,假如本例中的映射结果可能如下图所示:
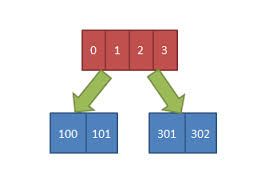
这部分对应了该函数中第二个关键点:get_more_blocks(),如果映射的结果真的如我们上面设想的那样,那第一次我们只映射了page1中的两个逻辑块,因此接下来我们只能读这两个block,第二次再映射的时候,又映射了两个block,第一个block位于page1,第二个block位于page2。
- 映射完成后(且每次映射完成均)开始进行IO,这里的IO操作也是比较有趣的,对应了代码第三个关键点:submit_page_section()。一般来说,文件系统要进行IO主要就是调用块设备层的submit_bio接口,我们只需设置好参数即可。submit_page_section()为了效率上的考虑,实现了deferIO,核心思想是:不立即发起IO操作,而是等等看,看看后面的IO请求是否连续(所谓的连续IO是指同一个页面内物理块号连续的IO)。如果有,我们将它合并进来;否则将本次IO先发下去(调用submit_bio)在我们的情境中,第一次的IO请求位于page1的block 0和block 1(物理块号为100和101),第二次IO请求其实是page0的block 2(物理块号300),第三次的IO请求其实是page1的block 3,因此会产生3次IO请求。
结论
至此,我们不仅进行了测试,更进一步从源头上分析了测试结果的原因,形成如下有效结论:
- ext3采用的文件索引方式在读偏移较大的时候会产生额外IO,而且偏移越大,额外IO次数越多;
- Linux采用了buffer cache缓存ext3的索引块,查找数据块位置会首先在缓存中查找索引块,缓存未命中需要从磁盘读取索引块;
- DirectIO时Linux内核发出的IO请求次数实际上与以下因素相关:a).逻辑块在物理磁盘上的连续性;b).应用程序缓冲区对齐粒度,编程中尽量做到以PAGE_SIZE对齐。
参考:
http://ju.outofmemory.cn/entry/87814