局部自适应多核聚类
Locally adaptive multiple kernel clustering (Lujiang Zhang , Xiaohui Hu)
传统的多核学习是在输入空间上构建多个核的线性组合。对于局部分布变化的数据集来说,局部多核学习方法更好。即不是使用一个统一的组合核在所有输入空间,而是对于每个类都有一个局部核。
方法:给每个类分配一个用于特征选择的权重向量,将每个权重向量和高斯核进行结合生成对应类的单独的核。然后优化权重向量和高斯核的宽度参数(width parameter ),每个核局部匹配对应类的数据分布。基于kernel k-means 的局部自适应策略被用来优化每个类的核。
对比实验:kernel k-means clustering, averaged multiple kernel clustering, self-tuning spectral clustering and Variable Bandwidth Mean Shift algorithm. (四个)
已存在的局部多核学习方法:输入空间不同区域的核设定不同的权重。
与本文相关的其他研究:
(1)Lewis et al.[19] proposed a method for combining multiple kernels in a nonstationary fashion which is derived with a large-margin latent variable generative method.
[19] D.P. Lewis, T. Jebara, W.S. Noble, Nonstationary kernel combination, in:Proceedings of the 23rd International Conference on Machine Learning,2006, pp. 553–560.
(2)Gönen and Alpaydin [20] developed a localized multiple kernel learning method using a gating model for selecting the appro-priate kernel locally.
[20] M. Gönen, E. Alpaydin, Localized multiple kernel learning, in: Proceedings of the 25th International Conference on Machine Learning, 2008, pp. 352–359.
(3)Christoudias et al. [21] proposed a Bayesian approach to multiple kernel learning where the weights can vary
locally that learns the kernel matrix of a Gaussian process using a product of a parametric and non-parametric covariance.
[21] M. Christoudias, R. Urtasun, T. Darrell Bayesian localized multiple kernel learning, Technical Report No. UCB/EECS-2009-96, University of California, USA, 2009.
……
本文算法Locally adaptive multiple kernel clustering (LAMKC),LAMKC 迭代一下两步直到收敛:
(1)优化每个类对应的核;(2)根据特征空间中不同类对应的核计算的欧氏距离,重新分配数据点到离它最近的类。
本文还将Kaufman Approach (KA) 和k-means进行结合,以提供好的初始化划分。
本文算法用于数据分布变化的数据集,当然也适用于均匀分布的数据集,这种情况下不同类的核趋于一致。
权重向量就是通过对每个点的特征加权,进行特征选择,即表示第i个特征的重要性。每个权重向量与高斯核结合生成独立的核。
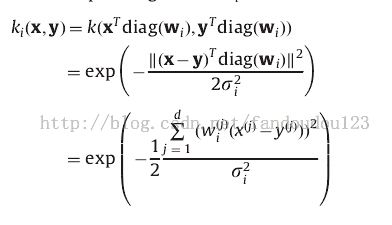
LAMKC 与kernel k-means 的区别在于欧式距离的计算不同,计算一个点与其他类的点的欧氏距离使用的是不同的核参数。
本文使用clustering accuracy (ACC)评价聚类方法的性能。使用了来源于machine learning repository 的七个数据集,和两个文本数据集20 Newsgroups和Reuters-21578,分别来源于http://people.csail.mit.edu/jrennie/20Newsgroups/和
http://www.daviddlewis.com/resources/testcollections/reuters21578/。
本文对数据集进行了 z-score transform,so that all dimensions have the same range of values.
实验结果:
本文算法的计算复杂度为![]() 。
。
对本文的质疑:在七个数据测试集上,LAMKC只有两个数据集比kernel k-means的聚类结果好,应该都好才对啊。