Hadoop中的DBInputFormat
一:背景
为了方便MapReduce直接访问关系型数据库(MYSQL、Oracle等),Hadoop提供了DBInputFormat和DBOutputFormat两个类,通过DBInputFormat类把数据库表的数据读入到HDFS中,根据DBOutputFormat类把MapReduce产生的结果集导入到数据库中。
二:实现
我们以MYSQL数据库为例,先建立数据库、表以及插入数据,如下,
(1):建立数据库
create database myDB;
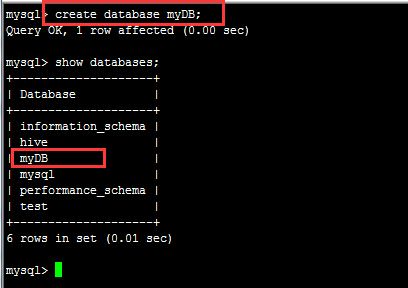
(2):建立数据库表
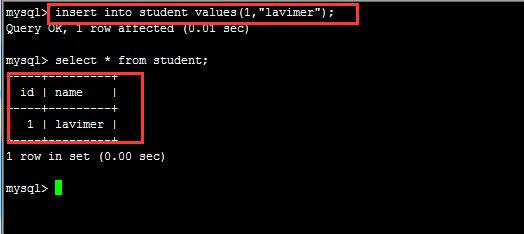
create table student(id INTEGER NOT NULL PRIMARY KEY,name VARCHAR(32) NOT NULL);

insert into student values(1,"lavimer");
(4)编写MapReduce程序,我这里使用的版本是hadoop1.2.1,相关知识点都写在注释中了,如下:
/**
* 使用DBInputFormat和DBOutputFormat
* 要把数据库的jdbc驱动放到各个TaskTracker节点的lib目录下
* 重启集群
* @author 廖钟民
* time : 2015年1月15日下午12:50:55
* @version
*/
public class MyDBInputFormat {
//定义输出路径
private static final String OUT_PATH = "hdfs://liaozhongmin:9000/out";
public static void main(String[] args) {
try {
//创建配置信息
Configuration conf = new Configuration();
/*//对Map端的输出进行压缩
conf.setBoolean("mapred.compress.map.output", true);
//设置map端输出使用的压缩类
conf.setClass("mapred.map.output.compression.codec", GzipCodec.class, CompressionCodec.class);
//对reduce端输出进行压缩
conf.setBoolean("mapred.output.compress", true);
//设置reduce端输出使用的压缩类
conf.setClass("mapred.output.compression.codec", GzipCodec.class, CompressionCodec.class);*/
// 添加配置文件(我们可以在编程的时候动态配置信息,而不需要手动去改变集群)
/*
* conf.addResource("classpath://hadoop/core-site.xml");
* conf.addResource("classpath://hadoop/hdfs-site.xml");
* conf.addResource("classpath://hadoop/hdfs-site.xml");
*/
//通过conf创建数据库配置信息
DBConfiguration.configureDB(conf, "com.mysql.jdbc.Driver", "jdbc:mysql://liaozhongmin:3306/myDB","root","134045");
//创建文件系统
FileSystem fileSystem = FileSystem.get(new URI(OUT_PATH), conf);
//如果输出目录存在就删除
if (fileSystem.exists(new Path(OUT_PATH))){
fileSystem.delete(new Path(OUT_PATH),true);
}
//创建任务
Job job = new Job(conf,MyDBInputFormat.class.getName());
//1.1 设置输入数据格式化的类和设置数据来源
job.setInputFormatClass(DBInputFormat.class);
DBInputFormat.setInput(job, Student.class, "student", null, null, new String[]{"id","name"});
//1.2 设置自定义的Mapper类和Mapper输出的key和value的类型
job.setMapperClass(MyDBInputFormatMapper.class);
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(Text.class);
//1.3 设置分区和reduce数量(reduce的数量和分区的数量对应,因为分区只有一个,所以reduce的个数也设置为一个)
job.setPartitionerClass(HashPartitioner.class);
job.setNumReduceTasks(1);
//1.4 排序、分组
//1.5 归约
//2.1 Shuffle把数据从Map端拷贝到Reduce端
//2.2 指定Reducer类和输出key和value的类型
job.setReducerClass(MyDBInputFormatReducer.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(Text.class);
//2.3 指定输出的路径和设置输出的格式化类
FileOutputFormat.setOutputPath(job, new Path(OUT_PATH));
job.setOutputFormatClass(TextOutputFormat.class);
//提交作业 然后关闭虚拟机正常退出
System.exit(job.waitForCompletion(true) ? 0 : 1);
} catch (Exception e) {
e.printStackTrace();
}
}
/**
* 自定义Mapper类
* @author 廖钟民
* time : 2015年1月15日下午1:22:57
* @version
*/
public static class MyDBInputFormatMapper extends Mapper<LongWritable, Student, Text, Text>{
//创建map输出时的key类型
private Text mapOutKey = new Text();
//创建map输出时的value类型
private Text mapOutValue = new Text();
@Override
protected void map(LongWritable key, Student value, Mapper<LongWritable, Student, Text, Text>.Context context) throws IOException, InterruptedException {
//创建输出的key:把id当做key
mapOutKey.set(String.valueOf(value.getId()));
//创建输出的value:把name当做value
mapOutValue.set(value.getName());
//通过context写出去
context.write(mapOutKey, mapOutValue);
}
}
/**
* 自定义Reducer类
* @author 廖钟民
* time : 2015年1月15日下午1:23:28
* @version
*/
public static class MyDBInputFormatReducer extends Reducer<Text, Text, Text, Text>{
@Override
protected void reduce(Text key, Iterable<Text> values, Reducer<Text, Text, Text, Text>.Context context) throws IOException, InterruptedException {
//遍历把结果写到HDFS中
for (Text t : values){
context.write(key, t);
}
}
}
}
/**
* 自定义实体类 用于对应数据库表中的字段
* @author 廖钟民
* time : 2015年1月15日下午12:52:58
* @version
*/
class Student implements Writable,DBWritable{
//学生id字段
private Integer id;
//学生姓名
private String name;
//无参构造方法
public Student() {
}
//有参构造方法
public Student(Integer id, String name) {
this.id = id;
this.name = name;
}
public Integer getId() {
return id;
}
public void setId(Integer id) {
this.id = id;
}
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
//实现DBWritable接口要实现的方法
public void readFields(ResultSet resultSet) throws SQLException {
this.id = resultSet.getInt(1);
this.name = resultSet.getString(2);
}
//实现DBWritable接口要实现的方法
public void write(PreparedStatement preparedStatement) throws SQLException {
preparedStatement.setInt(1, this.id);
preparedStatement.setString(2, this.name);
}
//实现Writable接口要实现的方法
public void readFields(DataInput dataInput) throws IOException {
this.id = dataInput.readInt();
this.name = Text.readString(dataInput);
}
//实现Writable接口要实现的方法
public void write(DataOutput dataOutput) throws IOException {
dataOutput.writeInt(this.id);
Text.writeString(dataOutput, this.name);
}
@Override
public int hashCode() {
final int prime = 31;
int result = 1;
result = prime * result + ((id == null) ? 0 : id.hashCode());
result = prime * result + ((name == null) ? 0 : name.hashCode());
return result;
}
@Override
public boolean equals(Object obj) {
if (this == obj)
return true;
if (obj == null)
return false;
if (getClass() != obj.getClass())
return false;
Student other = (Student) obj;
if (id == null) {
if (other.id != null)
return false;
} else if (!id.equals(other.id))
return false;
if (name == null) {
if (other.name != null)
return false;
} else if (!name.equals(other.name))
return false;
return true;
}
@Override
public String toString() {
return "Student [id=" + id + ", name=" + name + "]";
}
}
程序运行的结果是数据库中的数据成功导入到HDFS中,如下:
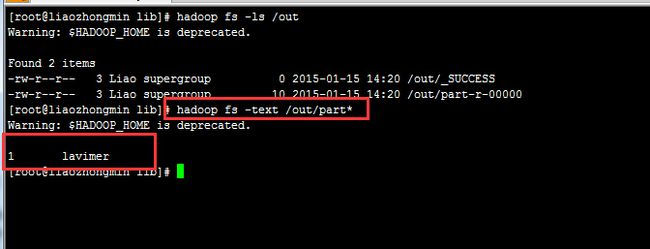
注:程序运行时,会碰到一个常见的数据库远程连接错误,大致如下:
Access denied for user 'root'@'%' to database ‘xxxx’
原因:创建完数据库后,需要进行授权(在本地访问一般不会出现这个问题)
解决方法就是进行授权:
grant all on xxxx.* to 'root'@'%' identified by 'password' with grant option;
xxxx代表创建的数据库;
password为用户密码,在此为root的密码
另外一个常见的错误就是MYSQL驱动没有导入到hadoop/lib目录下,解决方案有两种,传统的方式我就不多说了,这里说另外一种方式:
(1):把包上传到集群上
hadoop fs -put mysql-connector-java-5.1.0- bin.jar /lib(2):在MR程序提交job前,添加语句:
DistributedCache.addFileToClassPath(new Path("/lib/mysql- connector-java- 5.1.0-bin.jar"), conf);