(4)正则表达式——Python
Python:
Python中正则表达式的一些匹配规则: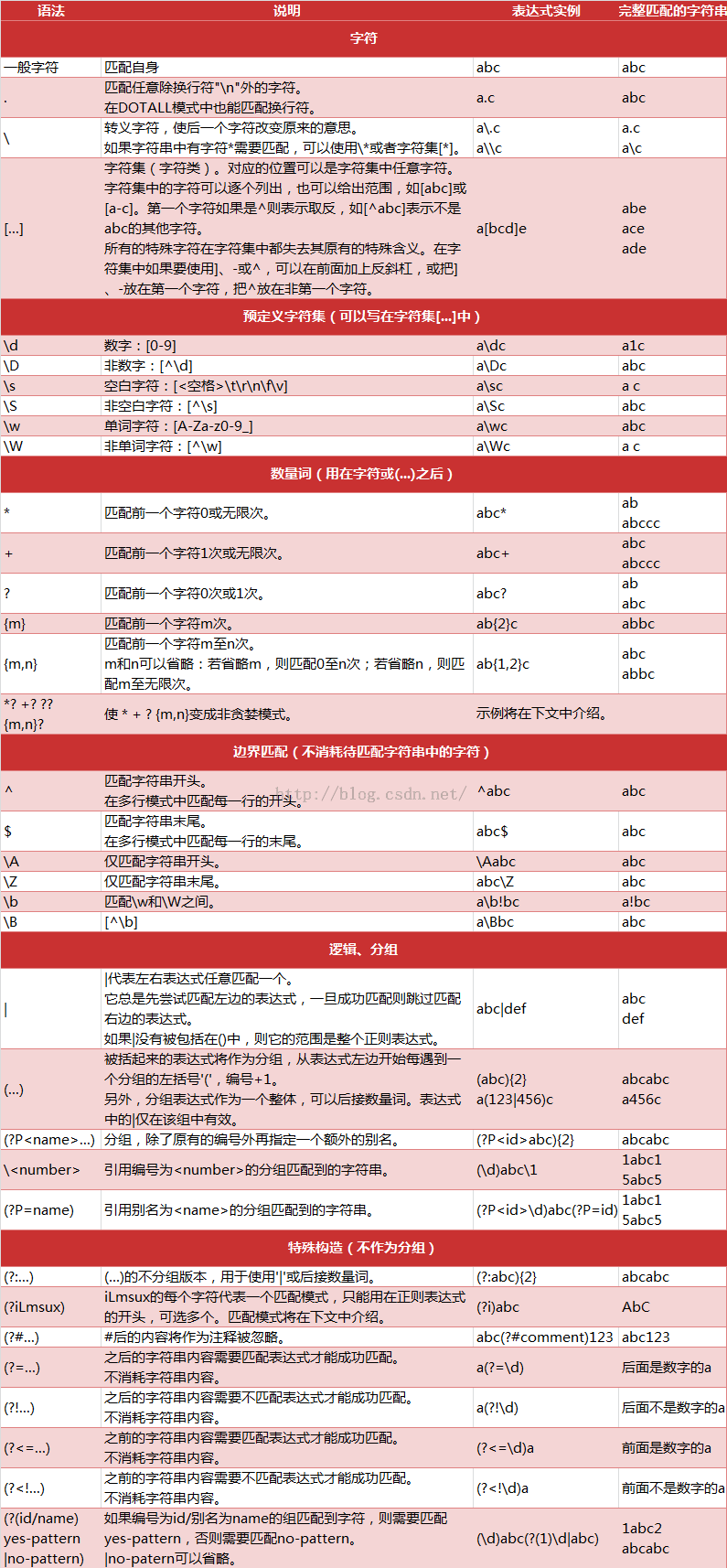
正则表达式相关注解
(1)数量词的贪婪模式与非贪婪模式
正则表达式通常用于在文本中查找匹配的字符串。Python里数量词默认是贪婪的,总是尝试匹配尽可能多的字符;非贪婪的则相反,总是尝试匹配尽可能少的字符。例如:正则表达式”ab*”如果用于查找”abbbc”,将找到”abbb”。而如果使用非贪婪的数量词”ab*?”,将找到”a”。
注:我们一般使用非贪婪模式来提取。
(2)反斜杠问题
与大多数编程语言相同,正则表达式里使用”\”作为转义字符,这就可能造成反斜杠困扰。假如你需要匹配文本中的字符”\”,那么使用编程语言表示的正则表达式里将需要4个反斜杠”\\\\”:前两个和后两个分别用于在编程语言里转义成反斜杠,转换成两个反斜杠后再在正则表达式里转义成一个反斜杠。
Python里的原生字符串很好地解决了这个问题,这个例子中的正则表达式可以使用r”\\”表示。同样,匹配一个数字的”\\d”可以写成r”\d”。
Python的 Re模块
Python 自带了re模块,它提供了对正则表达式的支持。主要用到的方法列举如下:
#返回pattern对象
re.compile(string[,flag])
#以下为匹配所用函数
re.match(pattern, string[, flags])
re.search(pattern, string[, flags])
re.split(pattern, string[, maxsplit])
re.findall(pattern, string[, flags])
re.finditer(pattern, string[, flags])
re.sub(pattern, repl, string[, count])
re.subn(pattern, repl, string[, count])
示例代码如下:
#!/usr/bin/python
# -*- coding: utf-8 -*-
#导入re模块
import re
#1、match()方法
#将正则表达式编译成Pattern对象,注意hello前面的r的意思是“原生字符串”
pattern = re.compile(r'hello')
# 使用re.match匹配文本,获得匹配结果,无法匹配时将返回None
match= re.match(pattern,'hello')
#如果匹配成功
if match:
# 使用Match获得分组信息
print match.group()
else:
print '匹配失败!'
### 输出: hello ###
#2、search()方法
pattern = re.compile(r'world')
#使用search()查找匹配的子串,不存在能匹配的子串时将返回None
#这个例子使用match()无法成功匹配
match = re.search(pattern,'hello world!')
if match:
# 使用Match获得分组信息
print match.group()
### 输出: world ###
#3、split()方法
pattern = re.compile(r'\d+')
print re.split(pattern,'one1two2three3four4')
### 输出:['one', 'two', 'three', 'four', ''] ###
#4、findall()方法
pattern = re.compile(r'\d+')
print re.findall(pattern,'one1two2three3four4')
### 输出:['1', '2', '3', '4'] ###
#5、finditer()方法
#搜索string,返回一个顺序访问每一个匹配结果(Match对象)的迭代器
pattern = re.compile(r'\d+')
for m in re.finditer(pattern,'one1two2three3four4'):
print m.group()
### 输出:1 2 3 4 ###
#6、sub()方法
pattern = re.compile(r'(\w+) (\w+)')
s = 'i say, hello world!'
#把匹配的字符串的第一个字符与第二个字符互换
print re.sub(pattern,r'\2 \1', s)
### output :say i, world hello! ###
#7、subn()方法
pattern = re.compile(r'(\w+) (\w+)')
s = 'i say, hello world!'
#返回 (sub(repl, string[, count]), 替换次数)。
print re.subn(pattern,r'\2 \1', s)
### output: ('say i, world hello!', 2) ###