连续可变斜率增量调制(CVSD)浅析
本文首先简单介绍了CVSD,然后简单说明了CVSD示例代码,最后给出了一个CVSD应用的实例。
1. CVSD简介
我们看到,所有的有线的或无线的语音通信都已经或者即将数字化。语音通过数字化进行传输或存储比传统的模拟方法有明显的优势。在数字通信或存储系统里,信息以二进制数的形式传送——接收方只需要确定接收信号是0是1即可完全恢复出原信息。在数字语音系统中,信息就是语音。衡量数字语音编码算法性能的参数是精确量化语音信号、并在传送后解码器还原语音的能力。换句话说,原始模拟语音信号必须能够在接收端被精确还原。然而,没有压缩量化的语音所占用带宽比原始模拟信号大许多。在无线或有线电信应用中,语音占用300—3300Hz的带宽。如果带内模拟信号经过抽样速率为奈奎斯特速率的线性模数转换,例如8kHz,进行8bit的256阶量化,得到的数据比特率是64kbps。没有引入编解码,得到的数字信号的带宽接近原始信号的20倍。
语音编码领域的工程师已经研究出许多减少编码后语音信号带宽的编解码方法。早期的算法试图利用人耳的动态适应性来进行编码。人耳对语音信号有或多或少的敏感性—人耳可以听到声压0dB到120dB的声音,人耳听觉动态范围约40dB。换句话说,我们很难听到摇滚音乐会上人们的细语。有一些语音编码算法利用了这种现象,使用较长码字对出现几率小的幅度范围的信号进行编码,而用较短码字对常见幅度范围的信号编码。这就是常用的非均匀量化。非均匀量化被用在PSTN网络中时,被称为律脉冲编码调制。一个更加复杂的方法是利用临近采样值之间的强相关性,只对样值的差值做编码。在相同的信号质量要求下,这种差值信号所需要的量化电平少了许多,因此降低了对带宽的要求。利用这种技术的算法都属于差分编码(DPCM)这一类。进一步的带宽节省可以通过更加复杂的算法实现。例如,结合自适应量化的DPCM是最常用的编码算法——ADPCM。
DeltaM(DM)和连续可变斜率增量调制(CVSD)都是差分波形量化技术。它们都采用了两级量化(1bit)。CVSD是带有自适应量化器的基本DM。对DM量化器使用自适应技术可以连续调整量化步长。通过调整量化步长,编码器可以高准确度地展现出小幅度信号,而不用牺牲大信号性能。
CVSD适用于同时对语音质量和安全性有要求的场合。MIL-STD-188-113 和Federal Standard 1023都是使用CVSD的例子。
1.1 差分量化
差分量化是一种当前样值与当前预测值之差作为下一时刻量化输入的编码方式。这种量化优势在于信号差量的动态范围要比不经过处理的输入信号动态范围小。因此,在相同SNR输出情况下需要较少的量化等级。或者,在相同的量化等级内,差量信号充分使用可用带宽编码可以得到更好的信号质量。

图5框图表示了一个差分量化系统。用时域上的离散信号 x(n) 表示原信号 x(t) 。注意到解码器在编码器的反馈回路里。因此,解码器是编码器的逆过程。标记为 Q 的模块把差分信号 d(n) 转换成二进制形式,以适合传输。模块 Q−1 并没有进行逆过程。事实上,从 d(n) 到 c(n) 的转化再到 dpd(n) 是差分编码非理想的一个很重要的因素。尽管如此,这个系统的基础研究可以假设不存在 Q 和 Q−1 而被简化。有了这个假设,编码器传导函数的 z 域表示为:
解码器传导函数为:
如果 DQD(z)≅D(z) ,则 XQD(z)≅X(z) ,整个系统的传导函数可以写成:
尽管公式(18)是基于一些假设的,但它体现了一个图5所示的结构构成的差分量化系统方案可以大致的还原信号。这个接近程度的好坏就是区分不同差分量化方案的依据。一般的,高质量的接近是需要付出代价的。
差分量化的一个关键因素是预测器 P(z) 。 P(z) 的输出 xp(n) 是前面时刻输入信号样值的加权总和。一般表达式等效于一个FIR滤波器
其中,P=预测器阶数
ak =加权系数
xp(n) =预测器输出
xQ(n)=dQ(n)+xp(n) 预测器输入
z 域预测器的传导函数
公式(19)和(20)说明了预测器输出是过去输入的线性组合,因此得名“线性预测器”。非线性预测器也有人研究,但考虑到其复杂度和稳定性等问题,使用较少。
差分量化编码器存在这不稳定性。如前边提到的,公式(20)是一种FIR滤波器。FIR最重要的性质之一就是稳定(传导函数只有零点)。然而,当FIR被放在反馈回路里时,编码器就是这样,零点就变成极点了——如果有一个极点在单位圆外,差分量化器就不稳定了。
1.2 差分调制
DM是两阶量化的差分编码方案。每个采样值用1bit表示,采样率等于比特率。因此,采样率直接关系到信噪比SNR。同时,输入信号的带宽和限带输出都是决定信号质量的重要因素。
DM算法最初于1946年产生。在过去的50年里,两种算法:线性DM(LDM)和CVSD因其有效处理数字语音信号而备受关注。LDM是最基础的最小复杂度的一种DM。因此,这里把LDM当作理解较复杂的DM算法的基础来解释。CVSD算法被定为战术级标准,在点对点的无线应用中越来越多的被使用,这里也会介绍。
1.2.1 线性DM
LDM的线性预测器 P(z) 是一阶的,量化器是两电平的。图6是描述LDM编解码算法的框图。
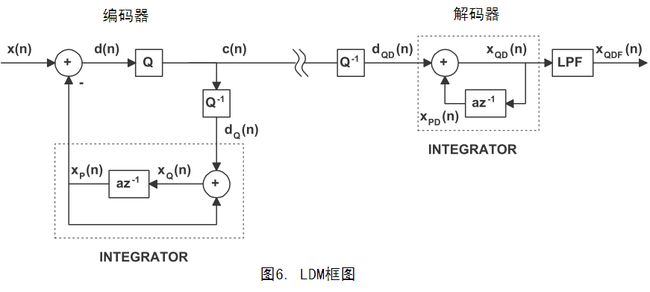
预测器是一个单抽头的FIR滤波器,传导特性为 P(z)=az−1 。编码器中, dQ(n) 到 xp(n) 的传导函数可以表示成 z 域形式:
解码器中,d_{QD}(n)到x_{QD}(n)的传导函数可以表示成 z 域形式:
公式(21)和(22)表示离散时间积分器(如果 a=1 )。如果 a<1 ,就变成阻尼积分器了。McDonald 和 Noll 都建议 a=1 为最适增益。一个纯积分器( a=1 )会使比特误码率比扩散更长,因此实际上还是推荐 a<1 。
图6中的量化器 Q 就像一个比较器。当输入d(n)超过0输出逻辑1,反之输出逻辑0。因此, Q 的输出是单比特的,表示了 d(n) 幅度的符号。反量化器 Q−1 把0、1逻辑翻译成增量 dQ(n) ,如下表所示

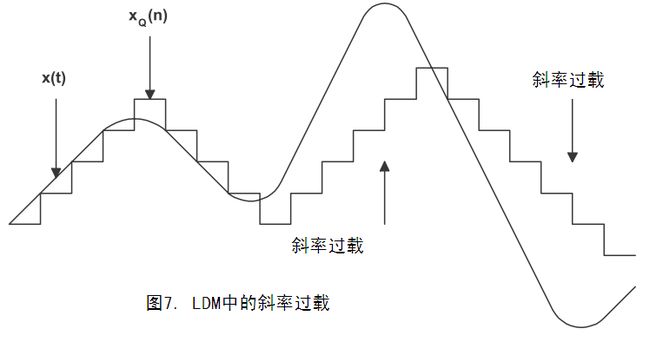
增量 Δ 的值对LDM的性能起了非常重要的作用。如果 Δ 比较小,可以跟踪细微变化,小信号可以很好的被还原出来,但对变化快的或是突发信号的捕捉能力很差。如果DM不能跟上输入信号变化,这种现象叫做斜率过载,如图7所示。
增大 Δ 可以减小斜率过载带来的影响,但同时也产生一个问题:粒状噪声(granular noise)。随着 Δ 变大,小信号量化的电平不够细致,从而还原出来像信道的噪声,如图8。理想信道方案只是一系列的0、1序列表示输入信号是否在变化。由于0、1交替的图样均值为0,因此解码器输出信号为0。

1.2.2 CVSD
通过对量化步长 Δ 做动态调整可以很大程度上减小粒状噪声和斜率过载。自适应DM(ADM)算法就是这样一种尝试,这种算法在信号变化缓慢时采用较小 Δ ,而在信号变化剧烈是采用较大 Δ 。使用最广泛的ADM算法是CVSD。它是1970年由Greefkes 和 Riemens提出的。他们的CVSD算法中, Δ 的自适应调整基于之前的3个或4个采样输出值(即, c(n),c(n−1),c(n−2),c(n−3) )。图9和图10分别表示了这种算法编码器和解码器的流程。注意这里只利用了过去的3个采样 c(n) 。

前面图6中出现过的模块 Q−1 被两个级联的延迟一个采样周期 z−1 的延迟器替代,用来确定是否出现了三个连0或连1。最小和最大步长分别用 Δmin 和 Δmax 表示。如果很长一段时间内没有连0或连1出现,积分器 I2 输出衰减到0附近,算法就等效于LDM了。 I2 和 I1 的时间常数典型值分别为4ms和1ms。在CVSD的文献中,积分器 I1 称为理论积分器, I2 称为音节积分器。所谓的音节积分器是因音节长度而得名。事实上,一个音节大概持续100ms,但是,音调变化却在10ms量级上。因此,4ms更适合CVSD音节时间常数。标号为L的模块作用是单电平转换(例如, c(n)=1 ,L输出1; c(n)=0 ,L输出-1) 。这种CVSD算法也被称为数字控制DM。
图11画出了积分器 I1 的输出(编码器的 xp(n) 和解码器的 xpd(n) )。与图7和图8相比,斜率过载和粒状噪声有所改善。
1.2.3 总结
CVSD的特性很适合语音数字编码。由于采用1bit量化,避免了复杂的帧结构。有很好的检测误码和纠错的性能。其他的语音编码方案则需要有数字信号处理器和外部模数数模转换器来对模拟信号进行数字转换。整个CVSD编解码算法,包括了输入输出滤波器,可以继承在单硅片里。尽管结构简单,CVSD却有足够的复杂度用来在安全应用领域进行数字加密。最后,CVSD可以在很宽的速率范围内工作——CVSD已经被成功的应用于9.6kbps—64kbps。在9.6kbps音频质量不是特别的好,但是不影响理解。在24kbps到48kbps,语音质量已经很容易接受。高于48kbps时,性能达到了Toll Quality的级别。
Toll Quality
MOS值达到4到4.5的认为是Toll Quality,还不错(等效于商用电信水平)。通信质量MOS值一般在3到4(仅仅是有可以忍受的失真,不影响理解)。图13比较了律PCM(标准Toll Quality)、CVSD和ADPCM算法的MOS值。注意到CVSD的性能在当前误比特率条件下等于或好于律PCM和ADPCM。特别是,当误比特率增加到1%时,CVSD仍然可以维持很好的MOS值,误比特率增加到10%时,MOS也可以达到3(通信质量)。恰是这种突发的比特误码使CVSD成为了许多无线语音通信应用的理想选择。
所有这些特点是CVSD吸引了无线通信系统(如数字无线电话,数字陆地移动无线广播)设计者。设防领域已经在有线或无线系统中使用CVSD许多年了。最近,美国联邦标准1023提出将25kHz的 CVSD用于工作在30MHz以上的无线广播信道。图14显示了CVSD编解码器在数字移动广播系统中的应用。
2. CVSD代码示例
2.1 初始化程序
#define MAX_CHAN 1 //编码的通道数
short min_step=10; //设定的最小量阶
short max_step=1280; //设定的最大量阶
double step_decay=0.9990234375; //I2的衰减因子
double accum_decay= 0.96875; //I1的衰减因子
int K=32;
int J=4; //出现连续4个1后调整量阶
short pos_accum_max=32767; //c(n)的最大正值
short neg_accum_max=-32767; //c(n)的最小负值
void cvsd_coder_init(void )
{
int i;
for(i = 0; i < MAX_CHAN ; i++)
{
encoder.d_min_step[i] = min_step;
encoder.d_max_step[i] = max_step;
encoder.d_step_decay[i] = step_decay;
encoder.d_accum_decay[i] = accum_decay;
encoder.d_K[i] = K;
encoder.d_J[i] = J;
encoder.d_pos_accum_max[i] = pos_accum_max;
encoder.d_neg_accum_max[i] = neg_accum_max;
encoder.d_accum[i] = 0;
encoder.d_loop_counter[i] = 1;
encoder.d_runner[i] = 0;
encoder.d_stepsize[i] = min_step;
decoder.d_min_step[i] = min_step;
decoder.d_max_step[i] = max_step;
decoder.d_step_decay[i] = step_decay;
decoder.d_accum_decay[i] = accum_decay;
decoder.d_K[i] = K;
decoder.d_J[i] = J;
decoder.d_pos_accum_max[i] = pos_accum_max;
decoder.d_neg_accum_max[i] = neg_accum_max;
decoder.d_accum[i] = 0;
decoder.d_loop_counter[i] = 1;
decoder.d_runner[i] = 0;
decoder.d_runner_mask[i] = 0;
decoder.d_stepsize[i] = min_step;
}
}2.2 编码程序
CVSD通过不断改变量阶 δ 大小来跟踪信号的变化,以减小颗粒噪声和斜率过载失真,量阶 δ 调整是基于过去的3个或4个样值输出。
int
cvsd_encoder (int ch,int noutput_items,
const short * input_items,
unsigned char * output_items)
{
const short *in = &input_items[0];
unsigned char *out = &output_items[0];
int i=0; // 2 bytes, 0 .. 65,535
unsigned char output_bit=0; // 1 byte, 0 .. 255
unsigned char output_byte=0; // 1 bytes 0.255
unsigned char bit_count=0; // 1 byte, 0 .. 255
unsigned int mask=0; // 4 bytes, 0 .. 4,294,967,295
// Loop through each input data point
for(i = 0; i < noutput_items*8; i++) {
// 当前值与计分器的输出作比较
if((int)in[i] >= encoder.d_accum[ch]) { // Note: sign((data(n)-accum))
output_bit=1;
}
else {
output_bit=0;
}
// Update Accum (i.e. the reference value)
// 如果大于积分器输出,积分器输出增大,反之减小
if (output_bit) {
encoder.d_accum[ch]=encoder.d_accum[ch]+encoder.d_stepsize[ch];
}
else {
encoder.d_accum[ch]=encoder.d_accum[ch]-encoder.d_stepsize[ch];
}
// Multiply by Accum_Decay
// 乘上衰减因子
encoder.d_accum[ch]=(cvsd_round(encoder.d_accum[ch]*encoder.d_accum_decay[ch]));
// Check for overflow
if (encoder.d_accum[ch] >= ((int)encoder.d_pos_accum_max[ch])) {
encoder.d_accum[ch] = (int)encoder.d_pos_accum_max[ch];
}
else if(encoder.d_accum[ch] <= ((int) encoder.d_neg_accum_max[ch])) {
encoder.d_accum[ch] = (int) encoder.d_neg_accum_max[ch];
}
// Update runner with the last output bit
// Update Step Size
// 如果已经处理了超过4个bit,则开始检查是否有连续的1或0,有的话调整Step Size,调整过程中注意不要超过Step Size的值域
if (encoder.d_loop_counter[ch] >= encoder.d_J[ch]) {
// Run this only if you have >= J bits in your shift register
mask=(cvsd_pow(2, encoder.d_J[ch]) - 1);
if ((cvsd_bitwise_sum(encoder.d_runner[ch] & mask) >= encoder.d_J[ch])
|| (cvsd_bitwise_sum((~encoder.d_runner[ch]) & mask) >= encoder.d_J[ch]))
{
if(cvsd_bitwise_sum(encoder.d_runner[ch] & mask) >= encoder.d_J[ch])
encoder.d_stepsize[ch] = min( (short)(encoder.d_stepsize[ch]
+ encoder.d_min_step[ch]), encoder.d_max_step[ch]);
else
encoder.d_stepsize[ch] = max( (short)(encoder.d_stepsize[ch]
- encoder.d_min_step[ch]), encoder.d_min_step[ch]);
}
else {// No runs of 1s and 0s
encoder.d_stepsize[ch] = max( (short)cvsd_round((encoder.d_stepsize[ch]-encoder.d_min_step[ch])*encoder.d_step_decay[ch]), encoder.d_min_step[ch]);
}
}
// Runner is a shift-register; shift left, add on newest output bit
encoder.d_runner[ch] = (encoder.d_runner[ch]<<1) | ((unsigned int) output_bit);
// Update the ouput type; shift left, add on newest output bit
// If you have put in 8 bits, output it as a byte
output_byte = (output_byte<<1) | output_bit;
bit_count++;
if (encoder.d_loop_counter[ch] <= encoder.d_K[ch]) {
encoder.d_loop_counter[ch]++;
}
// If you have put 8 bits, output and clear.
// 8bit作为单个数据输出
if (bit_count==8) {
// Read in short from the file
*(out++) = output_byte;
// Reset the bit_count
bit_count=0;
output_byte=0;
}
} // While
return noutput_items;
}2.3 解码程序
译码是对收到的数字编码进行判断,每收到一个“1”码就使积分器输出上升一个 δ 值,每收到一个“0”码就使积分器输出下降一个 δ 值,连续收到“1”码(或“0”码)就使输出一直上升(或下降),这样就可以近似地恢复输入信号。
int
cvsd_decoder(int ch ,int noutput_items,
unsigned char * input_items,
unsigned short * output_items)
{
const unsigned char *in = &input_items[0];
short *out = &output_items[0];
int i=0;
short output_short=0; // 2 bytes 0 .. 65,535
unsigned char bit_count=0; // 1 byte, 0 .. 255
unsigned int mask=0; // 4 bytes, 0 .. 4,294,967,295
unsigned char input_byte=0; // 1 bytes
unsigned char input_bit=0; // 1 byte, 0 .. 255
// Loop through each input data point
for(i = 0; i < noutput_items/8.0; i++) {
input_byte = in[i];
// Initiliaze bit counter
bit_count=0;
// 每次处理一个字节内的1bit
while(bit_count<8) {
// Compute the Appropriate Mask
mask=cvsd_pow(2,7-bit_count);
// Pull off the corresponding bit
input_bit = input_byte & mask;
// Update the bit counter
bit_count++;
// Update runner with the next input bit
// Runner is a shift-register; shift left, add on newest output bit
decoder.d_runner[ch] = (decoder.d_runner[ch]<<1) | ((unsigned int) input_bit);
// Run this only if you have >= J bits in your shift register
if (decoder.d_loop_counter[ch]>=decoder.d_J[ch]) {
// Update Step Size
// 如果已经处理了超过4个bit,则开始检查是否有连续的1或0,有的话调整Step Size,调整过程中注意不要超过Step Size的值域
decoder.d_runner_mask[ch]=(cvsd_pow(2,decoder.d_J[ch])-1);
if ((cvsd_bitwise_sum(decoder.d_runner[ch] & decoder.d_runner_mask[ch])>=decoder.d_J[ch])||(cvsd_bitwise_sum((~decoder.d_runner[ch]) & decoder.d_runner_mask[ch])>=decoder.d_J[ch]))
{
if (cvsd_bitwise_sum(decoder.d_runner[ch] & decoder.d_runner_mask[ch])>=decoder.d_J[ch])
decoder.d_stepsize[ch] = min( (short) (decoder.d_stepsize[ch] + decoder.d_min_step[ch]), decoder.d_max_step[ch]);
else
decoder.d_stepsize[ch] = max( (short) (decoder.d_stepsize[ch] - decoder.d_min_step[ch]), decoder.d_min_step[ch]);
}
else {
// No runs of 1s and 0s
decoder.d_stepsize[ch] = max( (short) cvsd_round(decoder.d_stepsize[ch]*decoder.d_step_decay[ch]), decoder.d_min_step[ch]);
}
}
// Update Accum (i.e. the reference value)
if (input_bit) {
decoder.d_accum[ch]=decoder.d_accum[ch]+decoder.d_stepsize[ch];
}
else {
decoder.d_accum[ch]=decoder.d_accum[ch]-decoder.d_stepsize[ch];
}
// Multiply by Accum_Decay
decoder.d_accum[ch]=(cvsd_round(decoder.d_accum[ch]*decoder.d_accum_decay[ch]));
// Check for overflow
if (decoder.d_accum[ch] >=((int) decoder.d_pos_accum_max[ch])) {
decoder.d_accum[ch]=(int)decoder.d_pos_accum_max[ch];
}
else if (decoder.d_accum[ch] <=((int) decoder.d_neg_accum_max[ch])) {
decoder.d_accum[ch]=(int)decoder.d_neg_accum_max[ch];
}
// Find the output short to write to the file
output_short=((short) decoder.d_accum[ch]);
if (decoder.d_loop_counter[ch] <= decoder.d_K[ch]) {
decoder.d_loop_counter[ch]++;
}
*(out++) = output_short;
} // while ()
} // for()
return noutput_items;
}3. CVSD应用实例
基于嵌入式系统的CVSD语音编解码器的实现
4. 参考文献
1. 译文-连续可变斜率增量调制
2. Continuously Variable Slope Delta Modulation (CVSD)
3. CVSD 的 算 法 、仿 真 及 实现
4. CVSD