KNN算法对新上市汽车评估分析
应用IBM SPSS Statistic 的最近邻元素分析模型(NNA)对汽车厂商预研车型进行市场评估。分析新车型的技术指标是否达标,预测新车型投放市场后的预期销售额。
4.1 研究背景
某汽车制造厂商研发了一款新车型,为了提升影响力,提高收益产出比,在投入市场之前希望能够对市场进行考核,增加两项技术设计指标,通过对已有的相关数据和技术指标进行对比,从而通过验证来检验新车型的技术指标是否能够达到预期效果。
4.2 研究目的
某汽车制造厂商的研发部门制定出两款新预研车型的技术设计指标,厂商的决策层希望将其和已经投放到市场上的已有车型的相关数据进行比较,从而分析新车型的技术指标是否符合预期,并预测新车型投放到市场之后,预期的销售额是多少。
对于解决此类问题,软件提供了一种新的行之有效的模型分析方法:Nearest NeighborAnalysis(最近邻元素分析模型)。本案例将简单介绍最近邻元素分析模型的概念,并详细探讨本案例中该模型的分析方法。
4.3 研究方法与模型
4.3.1 SPSS 的最近邻元素分析模型简介
SPSS软件的最近邻元素分析是一种针对样本实例进行的分类算法,它根据某些样本实例与其他实例之间的相似性进行分类。特征相似的实例互相靠近,特征不相似的实例互相远离。因而,可以将两个实例间的距离作为他们的“不相似度”的一种度量标准。SPSS的最近邻元素分析模型可以支持两种方法计算实例间距离,他们分别是:Euclidean Distance( 欧氏距离法 ) 和 City-block Distance(城区距离法)。
相互临近的实例被称之为“Neighbors(邻居)”。当我们向模型中引入一条新的实例,它和模型当中已经存在的每一个实例之间的距离将会被计算出来。这样,与这条新实例最相近的邻居就被区分出来了。图4-1描述了一个目标变量是离散型变量的最近邻模型,红色五角星是新实例,白色和蓝色的点是模型当中已有实例。与他最近的邻居们都被用红线连接了起来。
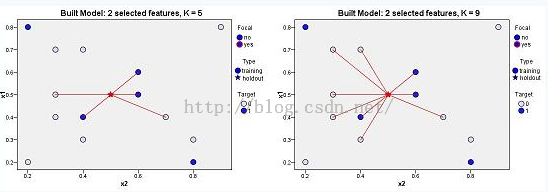
图4-1 最近邻元素模型
最近邻居数量K在最近邻元素分析模块建模中起到了很大的作用。K的取值不同,将会导致对新实例分类结果的不同。图4-1所示,每个实例根据其目标变量取值(0和1)的不同,被分入两个类别集合。当 K=5 时,与新实例连接的旧实例(邻居)当中,目标变量取值为1的实例数更多,所以新实例被分到类别1当中。然而,当 K=9 时,目标变量取值为0的邻居更多,因此新实例被分到类别0当中。Statistics的最近邻元素分析模型既允许用户指定固定的K值,也支持根据具体数据自动为用户选择K值。
Statistics的最近邻元素分析模型支持feature selection(预测变量选择)的功能,允许在用户输入的众多的预测变量当中,只选择一部分预测变量用作建模,使得建立的模型效果更好。Statistics的最近邻元素分析模型允许建立目标变量是连续型变量的模型,在这种情况下,目标变量的平均值或者中位数值将作为新的实例目标的预测值。
4.3.2 数据准备
该汽车制造厂商的研发部门所制定的两款预研车型的技术指标数据如表4-1所示:
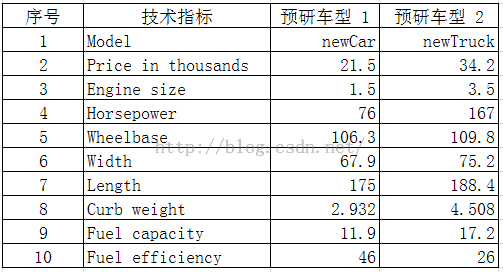
表4-1 两款新预研车型的技术指标数据
我们需要将这两款新车型的数据作为两条新的记录,写入原先的数据文件当中,然后再进行分析。这需要我们进行一些数据准备工作。
首先按照表4-1提供的数据,在原数据文件当中增加两条新的记录,如图4-2所示:
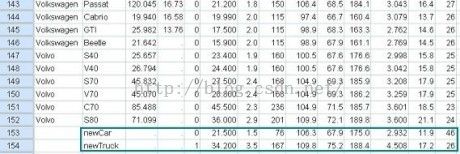
图4-2 原数据文件当中增加两条新记录
然后,我们要为这两条新记录加上特别关注的标记,这需要为所有记录增加新的变量。通过菜单转换->计算变量,打开计算变量对话框,如图4-3所示。键入focal作为目标变量,在NumericExpression文本框当中键入表达式:any(model, ‘ newCar ’ , ’newTruck ’ )。根据这个表达式,对于任意一条记录,其model变量的取值如果是newCar或newTruck,则它的focal 变量的取值被设置为 1,否则被设置为 0。

图4-3 增加 focal(焦点)变量
我们再增加一个新变量 partition,以区分训练数据子集和测试子集,我们将已有车型视为训练数据子集,而新车型为测试子集,如图4-4所示。注意在数字表达式文本框中填写1-any(model, ‘newCar’,‘newTruck’),使得变量partition的取值与变量focal 正好相反。之所以这样做是由于算法中规定:partition> 0 表示为训练数据,这两个新车型作为测试数据,将其 partition 设为0;而focal=1为重点关注对象。
图4-4 增加partition(分区)变量
4.3.3 寻找最近的邻居
现在,让我们来看看如何将这两款新车型的数据和已有车型的数据进行比较。通过菜单打开最近邻模型对话框,如图 4-5所示:
图 4-5 打开最近邻元素分析模型
在打开的最近邻模型对话框当中,我们选择 variables(变量)页面,并选择从price(价格)开始,到mpg(耗油率)为止的变量作为预测变量,选入Features(特征)文本框,共计9个特征。然后我们将focal 变量选入 Focal Case Identifier(optional)(焦点个案标识符(可选))文本框。而在Case Label(个案标签)中,我们选择了变量 model。如图4-6所示:
图4-6 变量设置
之后,切换到 Partition(分区)页面,保持默认选项不变。如图 4-7 所示:
图 4-7 使用默认设置选择训练数据
本次分析过程只寻找K个最近的邻居,而不做分类和预测,所以我们没有选择目标变量。为了图形显示更加清晰,本步骤选择含有少数个案的数据集进行示例。分析过程运行结束后,我们从“Output 输出视图”中打开模型视图浏览器,如图4-8所示:
图4-8 3个最近邻居(K=3)的输出视图
模型浏览器左边的子视图是预测变量空间视图。它是一个三维视图,图中的三条轴分布代表了马力、引擎尺寸、价格三个预测变量。该视图是可交互的,用户可以通过鼠标点击和拖拽,将视图旋转到更好的视角来观察个案样本点在空间中的分布。图中的每个点都代表训练分区数据集中的个案,用圆形表示。在图4-8当中,只有两个新车型个案属于focal(焦点)个案,其外形被红色包裹,其余已有车型都不是焦点个案。可以看到,每一个焦点个案都用红线连接着3个最近邻居。
模型浏览器右边的子视图是对等图,初始内容将显示每一个焦点个案的3个邻居们在每一个预测变量上的取值分布。系统默认将在前6个用户选择的预测变量上显示数值。
当我们在预测变量空间子视图当中用鼠标点击选择某个点,即选中某个个案时,该个案成为焦点个案。在右边的对等图中,将显示该个案及它的3个邻居们在每一个预测变量上的取值分布。每一个单独的图表显示了某个预测变量的一维空间。比如,newCar处于Enginesize(引擎尺寸)图表的最下端,说明它引擎尺寸比邻居们的都要小。
4.3.4 预估汽车类型
通过在运行设置时增加一个目标变量——Vehicle type(汽车类型),如图4-9所示,我们可以更好的了解新车型应该被匹配到哪个类型当中。要额外说明的是,增加了目标变量,最近邻元素分析过程将支持自动选择一个“最优”的邻居个数,并通过Variable Importance(变量重要性)来衡量个案之间的距离。
图4-9 添加目标变量
切换到 Neighbors页面,如图4-10所示。我们选中Specify fixed K,并指定K=3,同时,选中 Weightfeatures by importance when computing distances选项。
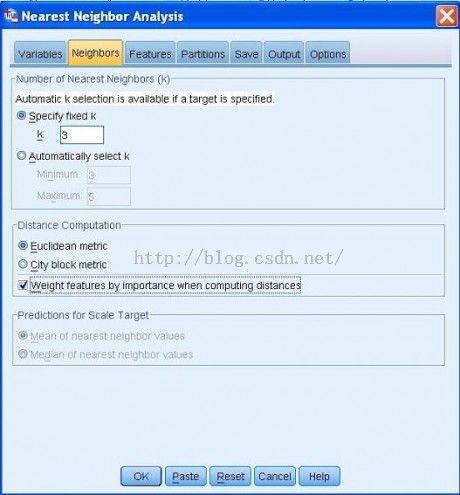
图4-10 设置固定的 K 值及计算距离时的选项
然后切换到 Features页面,如图4-11所示。选择Perform feature selection选项,在 StoppingCriterion(中止条件)区域,填写7作为Number to select(待选择数目)。
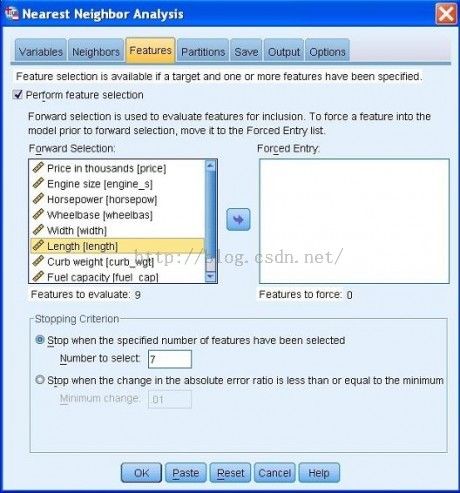
图4-11 执行预测变量选择
之后,我们转到 Partition页面,如图4-12所示。在Training and Holdout Partitions区域当中,我们选择Use variableto assign cases,并将前期数据准备阶段产生的新变量partition 选入Partitionvariable文本框中。
图4-12设置 Partition(分区)变量
最后一步,我们选择Save页面,如图4-13所示。在Variablesto Save区域中,选择 Predicted value or category,并用一个新的变量保存它,我们可以使用在Variableor Root Name中的默认的变量名称“KNN_PredictedValue”做为新变量的名称。
点击 OK 按钮执行最近邻元素分析。
图4-13选择新变量存储预测值
运行结束后,查看此时的原始数据的DataSet数据集,在其最右边,可以看到数据增加了一列,名为“KNN_PredictedValue”,我们称其为预测值,它是对原始数据每个个案,利用所产生的模型,根据预测变量的取值计算出的目标变量值。我们注意到,newCar的预测type是0,newTruck的预测type是1。下面我们来检查这些预测分类计算的是否合理。
打开Model Viewer,选择右边PeerChart视图下方的下拉菜单中的项Classification Table并打开,如图4-14,图4-15所示,它反映了对目标变量的观测值和预测值之间的交叉验证情况。对训练数据,从表中可以看到只有一个Automobile个案被错误地划分成为卡车,而对于Truck,只有7个卡车个案被错误地划分为小轿车,因此总体的准确率达到了94.7%;同样对测试数据,可以看到两个新车型的观测值和预测值都是一致的,这说明新轿车和新卡车的分类结果都是正确的。根据这个结果,说明我们建立的模型是很好的。
图4-14 Peer Chart 视图下方的下拉菜单
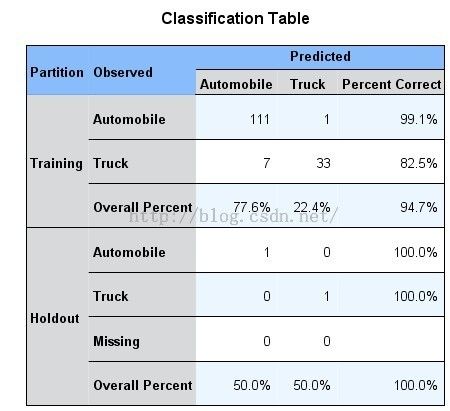
图4-15 Classification 分类表
通过选择Peer Chart下方的下拉框菜单中的PredictorImportance项,可以显示 Predictor Importance视图,该视图描述了每个预测变量在做出预测时的重要程度,其度量值是相对的,所有变量的重要程度值总和为1,从上至下,变量的重要程度依次递减。如图4-16所示:
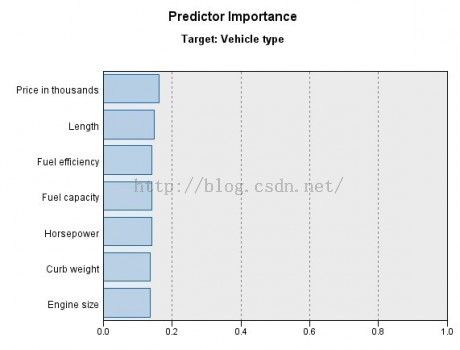
图4-16 预测变量重要性视图
4.3.5 预测销售额
现在我们设置目标变量为Sales in thousands(销售额(千元)),再进行一次分析,从而获得如果将两个新车型投放到市场后的预期销售额。
在图4-9所示的最近邻元素模型对话框的variables页面中,我们将目标变量换成销售额,切换到Neighbors页面,如图4-17所示。我们选择AutomaticallySelect K选项,选择3作为所允许的最少邻居数,选择9作为所允许的最多邻居数,其余保持不变。
图4-17自动选择 K 个最近邻居数
然后切换到Features页面,在如图4-11所示的页面中,取消对Performfeature selection的选择,我们希望所有的预测变量都被用来建模。
再切换到Partitions页面,如下图4-18所示。可以看到,此时Cross-ValidationFolds区域已经处于激活状态,这是由于我们在图4-17中选择了自动选择K而不是指定K值。如图选择Randomlyassign cases to folds,并选择子集数为10。同时,选中Setseed for Mersense Twister(设置 MersenseTwister 种子)选项,并设置种子取值,可以选择某个日期。

图4-18 交叉验证子集设置
由于本次我们选择了从 K=3到K=9自动选择K,并且使用用户设置的所有预测变量,所以在执行过程当中,将使用所有的预测变量为范围内的每一个K计算错误率,哪个K值及其预测变量所确定的模型在预测目标值时的错误率最低,哪个K值就被自动选定了。
然后,同上一个分类预测的过程一样,选择Save页面,如上图4-13所示。在Variables to Save区域中,选择 Predicted value or category,使用默认的变量名。
运行结束后,原始数据集最右边同样会增加新的一列,保存的是目标变Sales inthousands(销售额)的预测值,列名为“KNN_PredictedValue_1”。从这一列中我们得到,newCar的预测销售额是94.375 (千元),newTruck的预测销售额是 108.537 (千元)。那么,这些预测值计算的是否合理,我们所建的模型如何?
由于本例中的目标变量是连续型变量,上例中预估分类模型(目标变量是离散型)的方法在此不再适合。我们可以通过判断该模型的统计量Rsquare的值,来评定所建模型的好坏。
Rsquare的计算公式:Rsquare=1-errorSummary/( Variance *( N -1) ),其中,errorSummary代表建模后得到的错误合计;Variance代表训练数据的方差值;N代表训练数据中有效的个案个数。根据分析的结果,通过公式计算,得到:Rsquare=0.76542
理论上,Rsquare 值应该在0和1之间,Rsquare值越接近1,则表示所创建的模型越好。本例中的值大于0.7,说明我们的模型还是不错的。那么,由该模型计算出来的预测值应该也是可信的。
现在来看最近邻居数目在建模过程中是如何确定的,在 Peer Chart 视图下方的下拉菜单中选择K Selection,得到最近邻居数目K的选择视图,如图4-19所示。可以看到,当K 值为3的时候,模型的预测错误率是最低的,因此最邻近元素分析自动地为我们选择了3作为最终的K值。
图4-19最近邻居数目K的选择
其他视图的分析过程和前面介绍的类似,这里不再过多阐述。
4.4 研究结果
最终,可以得到根据最近邻元素模型预估出这两块车型所属的类型,newCar的预测type是0,newTruck的预测type是1。预测出两款新车型在投入市场后可能得到的销售额,newCar的预测销售额是94.375 (千元),newTruck的预测销售额是 108.537 (千元)。从模型的详细信息当中可以了解到该预测结果的可信程度是比较高的。
通过对该商业实例进行实际的建模分析,我们了解到SPSS软件的NearestNeighbor(最近邻元素分析模型)是一种基于分类的数据挖掘算法,能够根据已有数据,迅速、准确地对个案进行分类和预测。所建立的模型也能够通过丰富、直观的图表来描述,方便了用户的使用,是一个有着广泛用途的分析工具。