元祖由不同元素组成,所有元素被包含在一个圆括号中。
tuple_name=(a1,a2,a3...)
像数组之类的
像数组之类的
颜色缓冲区(COLOR_BUFFER)就是帧缓冲区(FRAME_BUFFER),你需要渲染的场景最终每一个像素都要写入该缓冲区,然后由它在渲染到屏幕上显示.
深度缓冲区(DEPTH_BUFFER)与帧缓冲区对应,用于记录上面每个像素的深度值,通过深度缓冲区,我们可以进行深度测试,从而确定像素的遮挡关系,保证渲染正确.
模版缓冲(STENCIL_BUFFER)与深度缓冲大小相同,通过设置模版缓冲每个像素的值,我们可以指定在渲染的时候只渲染某些像素,从而可以达到一些特殊的效果.
光线照到一个物体,首先产生了反射,吸收和透射,所以BRDF的关键因素即为多少光被反射、吸收和透射(折射)了,是怎样变化的。这时的反射多为漫反射。而要知道这些光线反射透射的变化就需要清楚三样东西,物体的表面材质、光线的波长(即它是什么样的光,是可见太阳光,节能灯光还是紫外线)和观察者与物体之间的位置关系。三维世界角度可以类似是球体的,光线角度除了纵向180°的变化,还有横向360的不同发散方向。会有相应的入射光,反射光,入射角和反射角,它们在物体表面的法平面和切平面上的关系成为了BRDF的关键参数。由于人类眼睛对光的特殊敏感性,我们之所以能看到物体都是通过光线在物体上的发射和转移实现的。而双向反射分布这样的函数表示可以更好地描述光线在物体上的变化,反射光线同时发向分布在法线两边的观察者和光源两个方向,从而使人在计算机等模拟环境下,视觉上可以看到更好的物体模拟效果,仿佛真实的物体存在。
http://baike.baidu.com/view/2285120.htm?fr=aladdin
http://en.wikipedia.org/wiki/Bidirectional_reflectance_distribution_function
http://blog.csdn.net/candycat1992/article/details/39994049
struct SurfaceOutput {
half3 Albedo;
half3 Normal;
half3 Emission;
half Specular;
half Gloss;
half Alpha;
};
c.rgb += o.Emission;
高光反射中的指数部分的系数。影响一些高光反射的计算。按目前的理解,也就是在光照模型里会使用到(如果你没有在光照函数等函数——包括Unity内置的光照函数,中使用它,这个变量就算设置了也没用)。有时候,你只在surf函数里设置了它,但也会影响最后的结果。这是因为,你可能使用了Unity内置的光照模型,如BlinnPhong,它会使用如下语句计算高光反射的强度(在Lighting.cginc里):
float spec = pow (nh, s.Specular*128.0) * s.Gloss;
高光反射中的强度系数。和上面的Specular类似,一般在光照模型里使用。
通常理解的透明通道。在Fragment Shader中会直接使用下列方式赋值(如果开启了透明通道的话):
c.a = o.Alpha;
http://game.ceeger.com/Components/SL-SurfaceShaderLightingExamples.html
http://game.ceeger.com/Components/SL-SurfaceShaders.html
用来计算镜面反射(specular reflection)的中间方向矢量(halfway vector)![]() 为什么是:
为什么是:
这个问题可分为两个层次去答。首先,要计算两个非完全背向的单位矢量在几何上的中间方向矢量,可以对两个单位矢量作线性插值:
如果想得到单位矢量,就需要再归一化(normalization)。归一化时,上面的0.5就被消去。
另一个问题是,Phong Reflection Modle是使用而不是Blinn提出的![]() 去计算镜面反射,为什么?
去计算镜面反射,为什么?

其实这两种计算方法也只是一种 BRDF,问题是哪种模型比较接近现实中的某种材质。[1] 7.5.7 节有比较详细的论述,在这里暂不详细展开了。
[1] Akenine-Möller, Tomas, Eric Haines, and Natty Hoffman. "Real-time rendering" 3rd edition, AK, 2008.
http://www.zhihu.com/question/25266627
Shader Model顶点纹理取码(vertex texture fetch)是相当值得关注的一项技术。顶点纹理取码允许应用程序直接从显存中提取纹理信息来作顶点处理,这种技术可以用在包括实时位移贴图(displacement mapping)等方面使用,通过这个功能你可以在顶点着色器3.0中实现各顶点的位移工作。
Reyes 渲染架构,是三维计算机图形学的一个软件架构,用于渲染照片一样真实的图像。该架构是80年代中期由卢卡斯影业的计算机图形研究小组成员艾德文·卡特姆、洛伦·卡彭特和罗伯特·库克所开发的,那个研究小组最后发展成了今天的皮克斯。[1] 该架构最早使用于1982年的科幻片《星际迷航2:可汗之怒》中的创世片段。皮克斯的PRMan是Reyes算法的一个实现。
根据最初描述该算法的论文,Reyes渲染系统是一个用于复杂图像的快速高质量渲染的“架构”,论文中指出Reyes包括一系列算法和数据处理系统,不过本词条中的“算法”和“架构”是同义的。
Reyes是Renders Everything You Ever Saw(渲染你曾见到的任何物体)的首字母缩写,这个名字也是卢卡斯影业以前所在地——加州Reyes海角的名字,因此Reyes是双关语,它还暗指和光学影像系统有关的过程。根据罗伯特·库克的说法,Reyes的正确写法是首字母大写,其余小写,和1987年库克/卡彭特/卡特姆的SIGGRAPH论文中一样。
Reyes架构的设计遵从以下目标:
Reyes算法能很高效的渲染一些电影画面要求的必不可少的效果:光滑的曲面、表面纹理、运动模糊和景深。
Reyes渲染流程
Reyes算法通过把参数曲面分割成微多边形(micropolygon)——小于一个像素的四边形,来渲染光滑曲面。虽然要精确逼近曲面需要很多微多边形,不过他们可以简单并行的进行处理。Reyes渲染器对高级的几何图形进行细分时,会根据需要来进行,它只需要刚好细分到使图形在最终图像中看起来光滑的程度。
然后,一个着色系统给微多边形的每个顶点赋予一个颜色和透明度,许多Reyes渲染器允许用户使用着色语言编写任意的灯光和纹理函数。微多边形可以在一个大的网格里进行处理,因此可以进行并行向量处理。
经过着色的微多边形在屏幕空间进行采样,以生成输出图像。Reyes引入了一个开创性的隐面判别算法或者叫hider,算法对运动模糊和景深进行必要的整合,而无需比未加模糊的渲染使用更高的模型和着色采样数。hider通过一种称为随机采样的蒙特卡洛方法收集一定时间和镜头位置内每个像素里微多边形的颜色。
在这个设计中,渲染器必须把整个图像缓存在内存中,因为必须把所有的图形都处理完成以后才能输出最终图像。一般在dice步骤之前会进行一步叫bucketing的常见内存优化,这一步中,输出图像被分割成若干指定大小的小块,通常每一块是16x16像素大小,之后,场景中的物体沿着每小块的大致边缘按照位置分割到不同的块里,然后每个小块分别进行处理,处理下一小块之前会先丢弃上一个小块的数据。如此只有当前的小块区域里的图形被加载到内存里,通常的情况下,这种处理能比未修改的Reyes算法显著的减少内存的使用。
http://zh.wikipedia.org/wiki/Reyes%E6%B8%B2%E6%9F%93%E6%9E%B6%E6%9E%84
实时全局光照
image based lighting 基于图像的照明(cubemap)
Sparse Voxel Octree Global Illumination
分辨率
http://baike.baidu.com/link?url=3d7DBH8LZbYbrzvsnh4JPOfwyqQnnCej87WdrIEtYijU2xSdwIxwm-rB5xpUfOqXpUc3zRQIhU17qjIhwa4aQq
在数学中,双曲函数类似于常见的(也叫圆函数的)三角函数。基本双曲函数是双曲正弦“sinh”,双曲余弦“cosh”,从它们导出双曲正切“tanh”等。也类似于三角函数的推导。反函数是反双曲正弦“arsinh”(也叫做“arcsinh”或“asinh”)依此类推。
http://baike.baidu.com/link?url=1fF-oIgIpoLfZdQIHg123EI61QbyvBBKbZPrwMSz8iIR80coEbvXGUwAQZjnrj6rSXBvJQgzlk3iXbuNqxNfdK#2_4
http://baike.baidu.com/link?url=lh9XTmb9RI2kVzkULIBzcM9CpWBZG2PfwEiNwThJVMWCefw9OjZfsLvxfre3if86AvB1uzRa33WBb7mlKUTRLx7vVeIIYGzXACYS4IhuqqZHoKztYecHKQPUWnvgIV2XvfcNM2mp4ajFby3tGsz55K
瑞利散射(Rayleigh scattering)由英国物理学家瑞利的名字命名。它是半径比光的波长小很多的微粒对入射光的散射。瑞利散射光的强度和入射光波长λ的4次方成反比:
其中是入射光的光强分布函数。
也就是说,波长较短的蓝光比波长较长的红光更易散射。
瑞利散射可以解释天空为什么是蓝色的。白天,太阳在我们的头顶,当日光经过大气层时,与空气分子(其半径远小于可见光的波长)发生瑞利散射,因为蓝光比红光波长短,瑞利散射发生的比较激烈,被散射的蓝光布满了整个天空,从而使天空呈现蓝色,但是太阳本身及其附近呈现白色或黄色,是因为此时你看到更多的是直射光而不是散射光,所以日光的颜色(白色)基本未改变——波长较长的红黄色光与蓝绿色光(少量被散射了)的混合。
当日落或日出时,太阳几乎在我们视线的正前方,此时太阳光在大气中要走相对很长的路程,你所看到的直射光中的蓝光大量都被散射了,只剩下红橙色的光,这就是为什么日落时太阳附近呈现红色,而天空的其它地方由于光线很弱,只能说是非常昏暗的蓝黑色。如果是在月球上,因为没有大气层,天空即使在白天也是黑的。
Depth Of Field (缩写啊。。= =;)
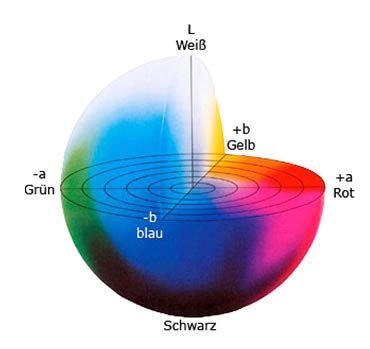
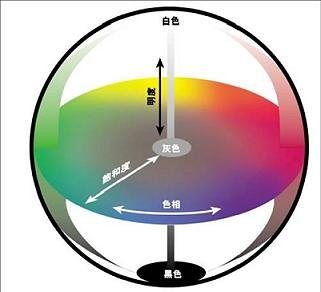
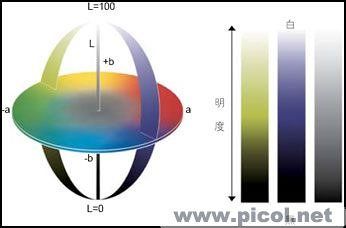
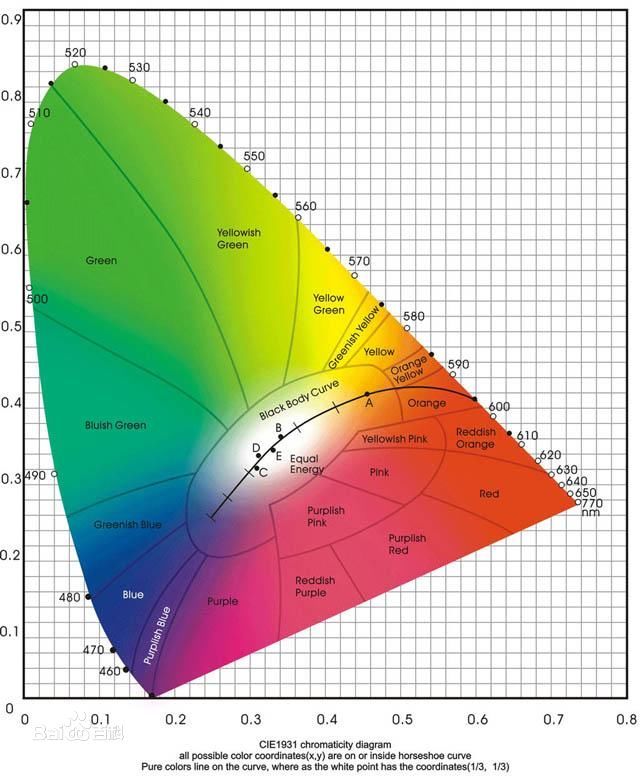
CIE 1976 (L*, a*, b*) 色彩空间 (CIELAB)
CIE L*a*b* (CIELAB) 是惯常用来描述人眼可见的所有颜色的最完备的色彩模型。它是为这个特殊目的而由国际照明委员会(Commission Internationale d'Eclairage 的首字母是CIE)提出的。L、a 和 b 后面的星号(*)是全名的一部分,因为它们表示 L*, a* 和 b*, 不同于 L, a 和 b。因为红/绿和黄/蓝对立通道被计算为(假定的)锥状细胞响应的类似孟塞尔值的变换的差异,CIELAB 是 Adams 色彩值(Chromatic Value)空间。
三个基本坐标表示颜色的亮度(L*, L* = 0 生成黑色而 L* = 100 指示白色),它在红色/品红色和绿色之间的位置(a* 负值指示绿色而正值指示品红)和它在黄色和蓝色之间的位置(b* 负值指示蓝色而正值指示黄色)。
航线 : 若干有路由性质(可能只有AB两点)的航点组合
航迹 : 行走轨迹,以一定的时间间隔连续记录下一串航点的记录
通俗的说法:
航点:每个点的详细信息,也就是指的位置
航线:你所走的线路就叫做航线
航迹:由每个点组合在一起,就够成了航迹
http://baike.baidu.com/link?url=WCzIwfRqN-CkstM5Iv6yiXTZm2QzXw4cQLly-lR2-JqQ7ZyAfuNJefj6QUtFX2CKBNQCI89HVFsCTAWTf0UG3q
1、图形加速\图形加速器\显卡
(Graphics Force Express)
同意词Graphics Acceleration
2、GFX文件格式:GFX 是一套跨平台的图形生成包,底层模型大致参照了 SVG,展现层同时支持 SVG 和 VML,GFX 可以帮助用户生成基于网页的矢量图,能够做到动态生成以及和用户发生交互。能够支持的图形包括矩形(Rectangle),圆弧(Circle),椭圆(Ellipse),多边形(polygon),线(Line),路径(polygon),图片(Image),文本(Text),文本路径(TextPath)。是一种可用于交互的图形格式,目前常应用于DoJo,也运用于游戏星际争霸2上。
screen space rendering
是1868年奥地利物理学家 E. 马赫发现的一种明度对比的视觉效应。是一种主观的边缘对比效应。当观察两块亮度不同的区域时,边界处亮度对比加强,使轮廓表现得特别明显。
马赫带(Mach band)马赫发现的一种明度对比现象。它是一种主观的边缘对比效应。当观察两块亮度不同的区域时,边界处亮度对比加强,使轮廓表现得特别明显。例如,将一个星形白纸片贴在一个较大的黑色圆盘上,再将圆盘放在色轮上快速旋转。可看到一个全黑的外圈和一个全白的内圈,以及一个由星形各角所形成的不同明度灰色渐变的中间地段。而且还可看到,在圆盘黑圈的内边界上,有一个窄而特别黑的环。由于不同区域的亮度的相互作用而产生明暗边界处的对比,使我们更好地形成轮廓知觉。这种在图形轮廓部分发生的主观明度对比加强的现象,称为边缘对比效应。边缘对比效应总是发生在亮度变化最大的边界区域。
蒙特·卡罗方法(Monte Carlo method),也称统计模拟方法,是二十世纪四十年代中期由于科学技术的发展和电子计算机的发明,而被提出的一种以概率统计理论为指导的一类非常重要的数值计算方法。是指使用随机数(或更常见的伪随机数)来解决很多计算问题的方法。与它对应的是确定性算法。蒙特·卡罗方法在金融工程学,宏观经济学,计算物理学(如粒子输运计算、量子热力学计算、空气动力学计算)等领域应用广泛
简单的说,实时渲染就是每一帧都不假设任何条件,都是针对当时实际的光源,相机和材质参数进行光照计算——常见的D3D,OPENGL的光照计算。
预先渲染一般是固定光源,和物体的材质参数,通过其他的辅助工具,把光源对物体的光照参数输出成纹理贴图,在显示的时候不对物体进行光照处理,只进行贴图计算
预先渲染可以借助复杂的高效果的工具,对场景进行精细的长期的渲染,然后在浏览的时候直接利用这些以前渲染的数据来绘制,从而可以在保证渲染的速度的时候获得很好的渲染质量。
但是缺点是,不能很好的处理动态的光源和变化的材质,在交互性比较强的环境当中无法使用。
10.1.4 游戏中渲染与预渲染
镜头切换中一个为某些玩家所排斥而为另外一些玩家所推崇的方面(这种现象在过去尤为明显),就是玩家需要对游戏中过场动画和预渲染动画进行辨别。游戏中过场动画是使用游戏内置的美术资源和渲染引擎实时渲染的。预渲染过场动画则不同,它们通常是在3D应用程序中利用高分辨率美术资源创建并渲染的。最终制成的视频片段只是在游戏中回放一遍罢了。
随着Unreal Engine 3及其高质量的渲染系统的诞生,这两种渲染技术之间的界线已经变得模糊起来。使用游戏中美术资源制作的游戏中过场动画与使用高分辨率美术资源制成的现代影片具有同样高的视觉逼真度。Matinee系统也已焕然一新,并成为非线性全效特征的编辑器。在过去,只能通过预渲染得到的高质量的过场动画,现在可以在UnrealEd内部直接创建,并可以在游戏播放时更为简便地实时渲染了。
对于游戏开发者而言,这意味着游戏、游戏过场动画,以及过去用作宣传目的的动画,如今都可以共享美术资源,这样就节省了开发者制作的时间花费或是外包给其他艺术工作室制作过场动画的经费。这也意味着,过场动画和实际的游戏在视觉上不再有什么区别了。对于玩家而言,此问题历来都是至关重要的。商业宣传时使用的游戏广告看上去都惊人的逼真。而当玩家把游戏买回家开始运行时,才发现其画面与广告的画面完全不同。Unreal Engine 3提供的强大性能已经使这一鸿沟成为了历史。![]()
VRML(Virtual Reality Modeling Language)即虚拟现实建模语言。是一种用于建立真实世界的场景模型或人们虚构的三维世界的场景建模语言,也具有平台无关性。是目前Internet上基于 WWW的三维互动网站制作的主流语言。 VRML是虚拟现实造型语言(Virtual Reality Modeling Language)的简称,本质上是一种面向web,面向对象的三维造型语言,而且它是一种解释性语言。VRML的对象称为结点,子结点的集合可以构成复杂的景物。结点可以通过实例得到复用,对它们赋以名字,进行定义后,即可建立动态的VR(虚拟世界)。
X3D是一种专为万维网而设计的三维图像标记语言。全称可扩展三维(语言),是由Web3D联盟 设计的,是 VRML 标准的最新的升级版本。 X3D 基于 XML 格式开发,所以可以直接使用 XML DOM 文档树、XML Schema 校验等技术和相关的 XML 编辑工具。目前 X3D 已经是通过 ISO 认证的国际标准。
奥卡姆剃刀
奥卡姆剃刀(Occam's Razor, Ockham's Razor)又称“奥康的剃刀”。
奥卡姆剃刀,是由14世纪逻辑学家、圣方济各会修士奥卡姆的威廉(William of Occam,约1285年至1349年)提出。奥卡姆(Ockham)在英格兰的萨里郡,那是他出生的地方。他在《箴言书注》2卷15题说“切勿浪费较多东西去做用较少的东西同样可以做好的事情。”
这个原理称为“如无必要,勿增实体”(Entities should not be multiplied unnecessarily)。有时为了显示其权威性,人们也使用它原始的拉丁文形式:
Pluralitas non est ponenda sine necessitate.
Frustra fit per plura quod potest fieri per pauciora.
Entia non sunt multiplicanda praeter necessitatem.
公元14世纪,英国奥卡姆的威廉对当时无休无止的关于“共相”、“本质”之类的争吵感到厌倦,于是著书立说,宣传唯名论,只承认确实存在的东西,认为那些空洞无物的普遍性要领都是无用的累赘,应当被无情地“剃除”。
他所主张的“思维经济原则”,概括起来就是“如无必要,勿增实体。”因为他是英国奥卡姆人,人们就把这句话称为“奥卡姆剃刀”。
这把剃刀出鞘后,剃秃了几百年间争论不休的经院哲学和基督教神学,使科学、哲学从神学中分离出来,引发了欧洲的文艺复兴和宗教改革。同时,这把剃刀曾使很多人感到威胁,被认为是异端邪说,威廉本人也受到伤害。然而,这并未损害这把刀的锋利,相反,经过数百年越来越快,并早已超越了原来狭窄的领域而具有广泛的、丰富的、深刻的意义。
奥卡姆的代表作是《逻辑大全(Summa Logical)》(商务印书馆有中译本),书中指出,世界是由具体的事物构成,不存在包罗万象的实体,而逻辑学是独立于形而上学的自然哲学工具。科学是关于具体事物的,事物是个别的,但在词语中有共相,逻辑是研究共相、词语和概念的。奥卡姆使逻辑学独立于形而上学和神学之外。
日益增加的理想的特性,大大延长其完成所需的开发时间
特征蠕动(Feature Creep)(有时候也称为需求漂移或者是范围蠕动)是产品或项目的需要在除了最开始的预见之外,在开发过程中还产生了新的要求的趋势,它导致了刚开始没有计划到的特征,对产品的质量和计划也带来了风险.特征蠕动可能是由客户增长的“需求列表”或者是开发者本身看到改进该产品的机会所带来的.为了控制特征漂移,项目管理工具,比如需求稳定指数(RSI)有时候被大家提倡.
功能蔓延(feature creep),有时也被称为需求蔓延(requirements creep)或范围蔓延(scope creep),它是指在发展过程中产品或设计的需求增加大大超过他们原来预期的趋势,导致其功能不是原本计划的并且要承担产品质量或生产进度的风险。功能蔓延可能是由于客户期望功能的增加或由于开发者自身发现了改善产品的机会而导致的。为了控制功能蔓延,设计管理工具有时被提倡使用,比如需求稳定性索引(RSI)。
原语 操作系统或计算机网络用语范畴。是由若干条指令组成的,用于完成一定功能的一个过程。primitive or atomic action 是由若干个机器指令构成的完成某种特定功能的一段程序,具有不可分割性·即原语的执行必须是连续的,在执行过程中不允许被中断。
Garbage Collection垃圾回收
浸泡测试(soak test):Soak test是在一个稳定的并发用户上进行的long run测试,用来测试应用程序的健壮性。通过soak test往往可以发现内存泄露,频繁 GC 等严重性能问题。进行soak test需要注意以下两点: Soak test需要在一定适中的用户负载量下进行,最好低于应用支持最大的负载量。 在执行long run测试时,采用几种不同用户组,并且每个用户组织性不同的业务流程。 Soak test实际上比较简单的性能测试,测试最好能够运行几天,以真正得到一个健壮的应用。确保应用测试是贴近真实世界,尽量与实际使用情况接近。 Soak testing involves testing a system with a significant load extended over a significant period of time, to discover how the system behaves under sustained use. For example, in software testing, a system may behave exactly as expected when tested for 1 hour. However, when it is tested for 3 hours, problems such as memory leaks cause the system to fail or behave randomly. Soak tests are used primarily to check the reaction of a subject under test under a possible simulated environment for a given duration and for a given threshold. Observations made during the soak test are used to improve the characteristics of the subject under test further. In electronics, soak testing may involve testing a system up to or above its maximum ratings for a long period of time. Some companies may soak test a product for a period of many months, while also applying external stresses such as elevated temperatures. This falls under stress testing.
Self语言,是一种基于原型的面向对象程序设计语言,于1986年由施乐帕洛阿尔托研究中心的David Ungar和Randy Smith给出了最初的设计。
时间戳(timestamp),通常是一个字符序列,唯一地标识某一刻的时间。数字时间戳技术是数字签名技术一种变种的应用。
CPU缓存(Cache Memory)位于CPU与内存之间的临时存储器,它的容量比内存小但交换速度快。在缓存中的数据是内存中的一小部分,但这一小部分是短时间内CPU即 将访问的,当CPU调用大量数据时,就可避开内存直接从缓存中调用,从而加快读取速度。
https://msdn.microsoft.com/en-us/library/ff604993.aspx
A back buffer is a render target whose contents will be sent to the device when GraphicsDevice.Present is called.
The graphics pipeline renders to a render target. The particular render target that the device presents to the display is called the back buffer. Use the BackBufferWidth and BackBufferHeight properties to get the back buffer dimensions. Render directly to the back buffer or to a render target by configuring the device using GraphicsDevice.SetRenderTarget and GraphicsDevice.SetRenderTargets.
Depth Bias深度偏移
通过给多边形增加一个z方向深度偏移(depthbias,z_bias),使3D空间的共面多边形看起来好像并不共面,以便它们能够被正确渲染。这种技术是很有用的,例如,我们要渲染投射在墙上的阴影,这时候墙和阴影共面,如果没有深度偏移,先渲染墙,再渲染阴影,由于depthtest,阴影可能不能正确显示。我们给墙设置一个深度偏移,使它增大,例如z增加0.01,先渲染墙,再渲染阴影,则墙和阴影可以正确的显示。
Depth-bias操作在clipping之后进行实施,所以depth-bias对几何clipping没有影响。另外需要注意的是:对一个给定体元(primitive),bias值是一个常量,在进行差值操作之前,它施加在每个顶点上。偏移操作都是32位浮点运算,还有Bias不能施加在点以及线体元上(除了线框模式的线段)。
转自http://blog.sina.com.cn/s/blog_61feffe10100ng4t.html
Depth-bias操作在clipping之后进行实施,所以depth-bias对几何clipping没有影响。
另外需要注意的是:对一个给定体元(primitive),bias值是一个常量,在进行差值操作之前,它施加在每个顶点上。
偏移操作都是32位浮点运算,还有Bias不能施加在点以及线体元上(除了线框模式的线段)。
http://blog.csdn.net/claien/article/details/8971125当2个片元距离近裁减平面 w 落在同一个区间的时候,他们的深度是相等的. 最终你所看到的结果,就是下面的这种样子:
注意到蓝圈里面.
如果避免发生Z-Fighting 才是关键. 注意到上面的depth - w 的位平面对应关系. 由于硬件都只能支持一定的深度格式,也就是说,Depth bits 是一定的,假为 D.而顶点的投影深度则毫无限制,他可以是 near_clip ---> far_clip 的任意一个浮点数.因此
dw/D = (far_clip - near_clip)/near_clip;
从上面可以看出, 要想dw 更精确,那么 near_clip 必然要更大(适用范围是far_clip >> near_clip).
上面那张存在depth-fighting 的截图当时的情况是 near_clip :0.0001 far_clip : 64000.0
下面的是在near_clip 0.1 far_clip 不变.
继续提高定点投影深度,也不会出现难看的深度冲突了.
要解决这个问题, 你只要google 或者去 beyond3d,等论坛,搜索 depth fighting ,得到的答案往往就是设置深度偏移. OpenGL : Polygon offset. D3D: Depth Bais.
http://blog.csdn.net/claien/article/details/8971125
In computer graphics and 3D rendering, color bleeding is the phenomenon in which objects or surfaces are colored byreflection of colored light from nearby surfaces.
Color Bleeding - The transfer of color between nearby objects or, caused by the colored reflection of indirect light. This is a visible effect that appears when a scene is rendered with Radiosity or full global illumination, or can otherwise be simulated by adding colored lights to a 3D scene.
A dirty bit or modified bit is a bit that is associated with a block of computer memory and indicates whether or not the corresponding block of memory has been modified.[1] The dirty bit is set when the processor writes to (modifies) this memory. The bit indicates that its associated block of memory has been modified and has not yet been saved to storage. When a block of memory is to be replaced, its corresponding dirty bit is checked to see if the block needs to be written back to secondary memory before being replaced or if it can simply be removed. Dirty bits are used by the CPU cache and in the page replacement algorithms of an operating system.
Dirty bits can also be used in Incremental computing by marking segments of data that need to be processed or have yet to be processed. This technique can be used with delayed computing to avoid unnecessary processing of objects or states that have not changed. When the model is updated (usually by multiple sources), only the segments that need to be reprocessed will be marked dirty. Afterwards, an algorithm will scan the model for dirty segments and process them, marking them as clean. This ensures the unchanged segments are not recalculated and saves processor time.
When speaking about page replacement, each page (frame) may have a modify bit associated with it in the hardware. The dirty bit for a page is set by the hardware whenever any word or byte in the page is written into, indicating that the page has been modified. When we select a page for replacement, we examine its modify bit. If the bit is set, we know that the page has been modified since it was read in from the disk. In this case, we must write that page to the disk. If the dirty bit is not set, however, the page has not been modified since it was read into memory. Therefore, if the copy of the page on the disk has not been overwitten (by some other page, for example), then we can avoid writing the memory page to the disk: it is already there.[2]
http://baike.baidu.com/link?url=EFGmAQIGWzEMS76JQz2EEU0jG_bbKjzRyhiDeeobR7HQN2l61FXjCkNYvBbJ_Iil9ZNC7r241IIU-_4HneKHKq
薄透镜(thin lenses),在光学中,是指透镜的厚度(穿过光轴的两个镜子表面的距离)与焦距的长度比较时,可以被忽略不计的透镜。厚度不能被忽略的透镜有时会称为厚透镜。薄透镜的主要参数有焦距、色差、球差、折射率等。
一种很薄的透镜,它的厚度可以在计算物距、像距、放大率等时忽略不计.
Depth peeling is a method of Order-independent transparency. Depth peeling has the advantage of being able to generate correct results even for complex images containing intersecting transparent objects.
its quality and performance determined by the number of rendering passes.." Depth peeling works by rendering the image multiple times.[1] The twist is that depth peeling uses two Z buffers, one that works conventionally, and one that is not modified, and sets theminimum distance at which a fragment can be drawn without being discarded. For each pass, the previous pass' conventional Z-buffer is used as the minimal Z-buffer, so each pass draws what was "behind" the previous pass. The resulting images can be combined to form a single image.
https://en.wikipedia.org/wiki/Depth_peeling
https://en.wikipedia.org/wiki/Order-independent_transparency
http://www.cnblogs.com/tiandsp/archive/2013/09/07/3307378.html
根据结构张量能区分图像的平坦区域、边缘区域与角点区域。
此算法也算是计算机科学最重要的32个算法之一了。链接的文章中此算法名称为Strukturtensor算法,不过我搜索了一下,Strukturtensor这个单词好像是德语,翻译过来就是structure tensor结构张量了。
此处所说的张量不是相对论或黎曼几何里的张量,黎曼几何的张量好多论文都叫张量场了。也不是数学界还没研究明白的对矩阵进行扩展的高阶张量,主要是张量分解。这里的结构张量就是一个矩阵,一个对图像像素进行组织的数据结构而已。
像素组织而成的矩阵如下:
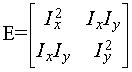
这个公式太常见了,在harris角点检测中就用到了。其中Ix,Iy就是原对原图像在x和y方向求得的偏导。
然后求矩阵E的行列式K和迹H。然后根据K和H的关系就能区分图像的区域模式了。
模式分以下三类:
平坦区域:H=0;
边缘区域:H>0 && K=0;
角点区域:H>0 && K>0;
harris角点检测就用到了第三类判断。
当然,在实际应用的时候H和K的值肯定都不会是理想,所以我用的都是近似判断。
处理结果如下:
原图:
平坦区域:

边缘区域:
角点区域(好像也不全角点,求角点还是harris好了):

结构张量行列式与迹的关系:
其中红框为平坦区域,黄框为边缘区域,铝框为角点区域。
https://en.wikipedia.org/wiki/Structure_tensor
In mathematics, the structure tensor, also referred to as the second-moment matrix, is amatrix derived from thegradient of a function. It summarizes the predominant directions of the gradient in a specified neighborhood of a point, and the degree to which those directions are coherent. The structure tensor is often used inimage processing and computer vision
http://baike.baidu.com/link?url=KyLEqZ1N2I_YnW0Efr3CZ-5cQtYc2emG6GxeC_THjW4viKYNHyLsq5itp81NX1Fsk9M1bQKgeS1cQ3AG-Ef-7IfCcn3VDcF1qzl5_IdD4Bm
http://baike.baidu.com/link?url=PztToXJ1wBvc62Wr46uJayCXlB2IiYIasPWYc1z1GIhUpeq5ndZm7TmMB0NkWhHZ4Wss88cdeBDDcfFCKopOG_
The accumulation buffer is an extended-range color buffer.Images are not rendered into it.Rather,images rendered into one of the color buffers are added to the contents of the accumulation buffer after rendering.Effects such as antialiasing (of points, lines, and polygons),motion blur,and depth of field can be created by accumulating images generated with different transformation matrices.Each portion of a pixel in the accumulation buffer consists offour values:one for each of R, G, B, and A.
The accumulation buffer holds RGBA color data just like the color buffers do in RGBA mode. (The results of using the accumulation buffer in color-index mode are undefined.) It's typically used for accumulating a series of images into a final, composite image. With this method, you can perform operations like scene antialiasing by supersampling an image and then averaging the samples to produce the values that are finally painted into the pixels of the color buffers. You don't draw directly into the accumulation buffer; accumulation operations are always performed in rectangular blocks, which are usually transfers of data to or from a color buffer.
The accumulation buffer provides support for many special effects such as motion blur and depth of field. It also supports full-screen anti-aliasing, although other methods (such as multisampling) are better suited to this task.
http://whatis.techtarget.com/definition/moire-effect
Moiré effect is a visual perception that occurs when viewing a set of lines or dots that is superimposed on another set of lines or dots, where the sets differ in relative size, angle, or spacing. The moiré effect can be seen when looking through ordinary window screens at another screen or background. It can also be generated by a photographic or electronic reproduction, either deliberately or accidentally.
莫尔效应(moiré effect)是当注视一组线或点与另一组线或点的叠层时的一种视觉效果,这两组点或线在相对大小,角落或间距上不同。莫尔效应可以在通过平常的纱窗看另一个纱窗或背景时被观察到。在照片或电子复制品上也能产生这种效果。
The illustration below shows two sets of lines of equal thickness and equal spacing, but one set is angled at a few degrees while the other set runs vertically. The moiré effect in this case appears as a set of thick, ill-defined, nearly horizontal bars.
下面的图展示了两组厚度和间距相同的直线,只是一组是垂直的,而另一组有点倾斜。这个例子中的莫尔效应看来像一组厚而不清楚的单杆。
 |
Moiré effect can produce interesting and beautiful geometric patterns. However, the phenomenon degrades the quality and resolution of graphic images. Problems occur when a screened image, such as is found in a newspaper, is directly photographed and then the photograph is reprinted in screened format. It can also occur when the image from a computer display is reproduced by photographic means and then rendered in a screened or dot-matrix format. The fine matrix of dots in the original image almost invariably conflicts with the matrix of dots in the reproduction. This generates a characteristic criss-cross pattern on the reproduced image.
莫尔效应(moiré effect)能产生有趣和美丽的几何图样。然而,这种现象减低了图画的质量,歪曲了原来面目。当一个屏像被直接拍照得到然后照片被印刷再版时就会出现问题。当计算机显示的图象被通过照相的方式复制,然后以点矩阵格式还原时也会产生这种情况。原时图片的优良的点矩阵总是和复制品的点矩阵相冲突。在重现图像时就产生了一个特色的十字型模式。
The word moiré is French (from the past participle of the verb moirer, meaning to water) and can be written with or without an accent aigu on the final "e." It was originally used to describe an effect applied to silk material to give it a wavy or rippled texture.
单词moire是法文(动词moirer的过去分词,意思是水),可以在最后一个"e"上加上或不加重音符号。它原本是用来描述给丝绸材料加上纹理的效果的。