linux系统调用(2)
慕课18原创作品转载请注明出处 《Linux内核分析》MOOC课程http://mooc.study.163.com/course/USTC-1000029000 ”
这里我们通过一个小例子来了解一下里linux中系统调用的编程方法!我们以 系统调用 uname 为例
<一> 我们先通过C语言来实现这个小程序(后面使用嵌入式汇编来实现)
第一步:我们只知道系统调用的名字为uname,却不知道这个调用是用来干什么的,那么我们通过一条指令来查看一下:
在终端中输入:man 2 uname 回车 会得到如下图所示的介绍:
那么我们知道了uname的作用是获取当前系统内核的名字及其他相关的信息,他的用法是:uname(struct utsname *buf)
而且需要包含头文件 utsname.h ,因为他需要的参数指针是一个utsname类型的结构体,而这个结构体是在utsname.h中定义的,其完整定义为:
struct utsname {
char sysname[]; /* Operating system name (e.g., "Linux") */
char nodename[]; /* Name within "some implementation-defined
network" */
char release[]; /* OS release (e.g., "2.6.28") */
char version[]; /* OS version */
char machine[]; /* Hardware identifier */
#ifdef _GNU_SOURCE
char domainname[]; /* NIS or YP domain name */
#endif
};
这里传递的参数是一个指针,所以很容易想到,这个系统调用的结果很可能就保存在这个指针所指向 的结构体中,从介绍信息中也能确认这一点!
uname有一个整型的返回值,这个值的作用是用来判断调用是否成功,当返回值 fb<0 时表示调用出错了(比如参数不正确等),fb= 0 表示调用成功。

第二步: 知道了uname的功能和用法之后,我们就用起来!下面给一个小的demo
程序和简单,先通过uname获取信息,然后用printf()格式化输出打印出来。

第三步:在当前目录输入gcc -o uname_c uname_c.c 将文件进行编译成可执行文件 uname_c
然后输入 ./uname_c 运行程序,运行结构如下:

结果可以看到,程序按照预期打印出了内核的相关信息。
<二> 下面用嵌入式汇编来实现上面的系统调用:
第一步:按照前面的步骤,我们已经知道了,uname的作用,但是用嵌入式汇编来实现时,需要用到uname对应的终端号,所以我们来查一下:
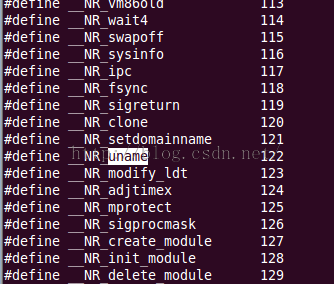
在终端中输入: less ***/arch/x86/include/asm/unistd_32.h: (*** 表示linux源码解压后的目录!)
然后输入 /uname 找到uname对应的记录项,(/name 为输入的内容,“ / ”也是)
我们可以看到uname对应的中断号为 122
第二步:我们看一段demo:
这里为了简便,和代码的可读性,只将前面C代码中的 “ fd = uname( &unm) ” 用嵌入式汇编来重写,其余部分与C代码部分的一样。
代码如下:
第三步:我们来简单分析一下这段汇编代码
asm volatile( // asm 表示告诉下面这段代码是汇编代码;volatile 表示告诉编译器对下面这段代不进行优化
"mov %1, %%ebx\n\t" // %1 表示的是后面跟的 1 号参数(和数组一样,从0 开始计数所以这里是第二个参数),参数时候以“ : ”开始的那几行。所以这一行代码的意思是把 参数 u 的值送到寄存器ebx中。
"mov $122, %%eax\n\t" // $122 表示常数 122 也就是uname的中断号,这一行表示将122 送到寄存器eax中,因为在
"int $0x80 \n\t" // int 表示出发一个系统中断,触发后系统转到中断向量表中的对应项所指的地址去执行,这里是跳转到第128 项所指地址去执行(该中断专门为系统调用而设),进入中断后,系统默认以寄存器eax中的值为 子中断号(上一步已经将uanme的中断号送到了eax中)
"mov %%eax, %0" //执行这一步的时候已经从中断中返回了,而且中断处理程序的返回值默认放在了eax中,所以这里我们又将返回值从eax中写到内存变量fd中。
:"=m"(fd) // 这下面两行的意思是表示的参数,“=m”表示后面的变量是在内存中,且用作输出;“m”表示的后面的变量在内存中,且是输入值。
:"m"(u)
);
更多信息可参考:http://blog.csdn.net/clp_csdnid/article/details/50936419
第四步:编译,运行结果

< 三 > 总结:
所谓系统调用,就是内核提供的、功能十分强大的一系列的函数。这些系统调用是在内核中实现的,再通过一定的方式把系统调用给用户,一般都通过门(gate)陷入(trap)实现。系统调用是用户程序和内核交互的接口。
整个系统调用的过程可以总结如下:
1. 执行用户程序(如:fork)
2. 根据glibc中的函数实现,取得系统调用号并执行int $0x80产生中断。
3. 进行地址空间的转换和堆栈的切换,执行SAVE_ALL。(进行内核模式)
4. 进行中断处理,根据系统调用表调用内核函数。
5. 执行内核函数。
6. 执行RESTORE_ALL并返回用户模式
库函数是对系统调用的封装(不是所有的库函数都是),为的是解决一些公共的问题和提供统一的系统调用的接口,他和系统调用的优缺点就是:系统调用速度是明显要快于库函数(并不一定全部是,但绝大部分是),但系统调用缺乏移植性。库函数速度要慢,但解决了移植问题。这些在开发过程中要根据自己的实际情况来决定使用那一个