在研发过程中如何有效使用Crash监控工具?
广大程序猿们还在加班分析Crash修Bug吗? 有想过早点回家陪家人吗?这期Crash实验室,阿不带大家看看鹅(腾)厂(讯)同学是怎样用Bugly提高Crash的修复效率!
先给大家讲个小故事吧!
2011年底,鹅厂内部出现一个“Crash监控”的服务后,开发某App的企鹅们发现了一个真相:原来自以为很稳定的版本,结果上线后竟然……。后来,这些企鹅们就开始默默地修Crash了。再后来,鹅厂的所有App都接入了Crash监控服务。
一般的产品开发过程,都会历经几大阶段。经过多年的经验积累,企鹅们已经将Crash监控充分融入到研发流程的各个阶段。在每个研发阶段充分利用Crash监控服务,让企鹅们的研发效率和质量得到大大的提升。
开发阶段
对于开发哥,发生Crash不是难题,发生Crash又无法分析才是问题。IDE里一闪而过的Log根本不允许你细心分析原因,如果是体验过程中发生Crash那更不可能看到Log。怎么破?
接入Bugly,只要发生了Crash就能实时上报,平时项目组体验和开发自测过程中发生的Crash都会被一一上报,开发哥可以在Bugly监控平台从容分析原因。
“用了Bugly,再也不用担心因为Crash达不到提测标准了,哈哈”,开发哥得意地说道。
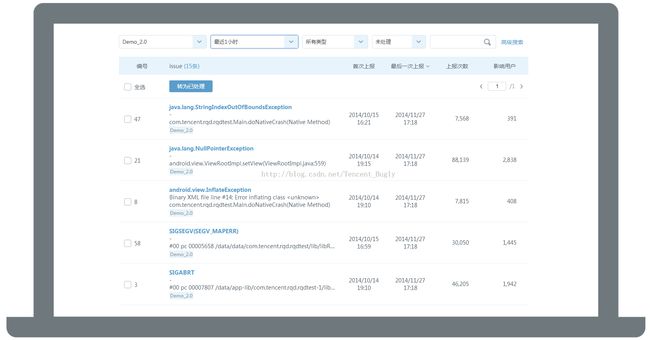
测试阶段
在测试妹面前,开发哥的自测要弱爆了,她能想到各种复杂逻辑或边界相关的场景,但追踪和重现起来都比较困难。怎么破?
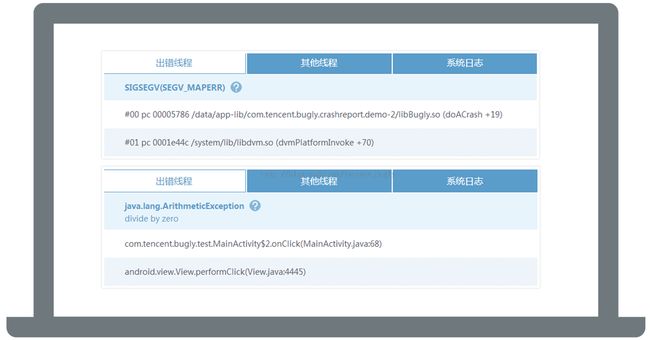
鹅厂开发哥有破解Crash三件宝:错误堆栈、运行日志、设备信息。
“Crash监控上报的信息已经非常丰富,比如:详情的堆栈信息,设备运行时信息,还有Log,开发哥通过上报的信息就可以快速定位和解决这些问题,不用和测试人员反复沟通,或想办法重现,减少了很多沟通和时间成本。”一位测试MM主动分享道,“在测试阶段就可以解决30%以上的Crash问题啦。”

灰度阶段
经过开发哥和测试妹的调戏(呃,是测试)的App就没问题?好吧,你没遇到过机型导致的Crash?你没遇到过会有网络原因导致的Crash?用户实际场景比测试环境复杂的多,怎么破?
在产品首次上线,或是有重大改动时,都要有灰度版本的发布,也称为“内测”或“公测”。灰度预热阶段,已经开始有大量用户使用产品,一般此刻会暴露出大量机型以及与实际环境相关的Crash问题。
负责项目管理的GG说,“这个时候,应用是否接入Crash监控非常关键。因为通过Crash监控平台的实时监控,可以快速了解灰度过程的Crash问题,项目组同时可以评估Crash的影响程度,确定产品是否可以正常上线。”
“ 还有,解决了灰度阶段发现的Top10问题,相当于解决上线后40%的Crash问题了。”一旁的开发哥补充。

上线阶段
App发布到用户手里谁也不能改代码,开发哥总算可以安心回家了?呃,你不知道每天的运营活动、后台服务故障都可能导致App出现Crash问题么?
怎么破?别担心,每天上班就到Crash监控平台上看看趋势分析视图,如果没有突变就安心写代码吧!
“有一次,在监控平台上发现Crash次数猛增,跟进后才知道,后台开发GG不小心把某个正在开发的功能发布到正式环境了,影响了线上服务。幸好当时项目组及时发现,并做了处理,才没有造成大的影响”,一位产品运营企鹅MM心有余悸地说道。

小结
小编还是将以上的访谈总结成一张图吧。希望看完文章的你,也能通过我们Bugly来提高研发效率和质量。这样,在后续的不管什么节日,都能早点下班陪家人过节。
本文系腾讯Bugly特邀文章,转载请注明作者和出处“腾讯Bugly(http://bugly.qq.com)”