【Linux】Linux中正则表达式
当从一个文件或命令输出中抽取或过滤文本时,可以使用正则表达式。
以下是在基本命令中使用正则表达式的一些定义及用法
基本元字符集及其含义
| ^ |
匹配行首 |
| $ |
匹配行尾 |
| . |
匹配任意单个字符 |
| * |
字符* 匹配0或多个此字符 |
| / |
屏蔽一个元字符的特殊含义 |
| [] |
匹配中括号中出现的字符,可以是单字符或字符序列,可以使用–表范围 |
| Pattern/{n/} |
匹配其那面patern出现的次数,n为次数 |
| Pattern/{n,/} |
至少出现n次 |
| Pattern/{n,m/} |
n<=次数 <=m |
使用例子:
1. 匹配任一单个字符
句点允许匹配ASCII集中任一字符,或为字母或为数字
b.g -> big bag beg 等
2. 在行首以^匹配字符串或序列
只允许在一行的开始匹配字符或单词
$ls –l | grep ^d 匹配文件夹
^001 开头为001的
3. 在行尾以$匹配字符串或序列
ld$ 以ld结尾
^$ 匹配所有空行
^.$只包含一个字符的
4. 使用*匹配字符串中单字符或其重复序列
Compu*t 匹配u重复0或多次
5. 使用/屏蔽一些特殊字符
特殊 $ . ‘ “ * [ ] ^ | ( ) / + ?
/.匹配句点
/*/.pass 匹配*.pass
6. 使用[]匹配一个范围或集合
匹配特定字符串,字符串集 可用逗号分隔
数字:[0123456789] [0-9]
小写字母: [a-z]
所有字母:[A-Za-z]
字母和数字: [A-Za-z0-9]
所有单词:[A-Za-z]*
[Cc]omputer 匹配Computer或computer
注意:在[]中,^代表否定
非字母:[^A-Za-z]
非数字:[^0-9]
7. 使用/{/}匹配模式结果出现的次数
A/{2/}B 匹配AAB
A/{4,/}B 匹配A出现至少4次B
A/{2,4/}B 匹配A出现在2至4次之间
正则表达式
热身
正则表达式(regular expression)描述了一种字符串匹配的模式,可以用来检查一个串是否含有某种子串、将匹配的子串做替换或者从某个串中取出符合某个条件的子串等。
例如 grep, expr, sed , awk. 或Vi中经常会使用到正则表达式,为了充分发挥 shell 编程的威力,需要精通正则表达式。
下面先举个简单例子来让大家对正则表达式有个直观的感受。ls命令是linux下最常用的命令。ls命令是list的缩写,缺省下ls用来打印出当前目录的清单。

现在,我们只希望列出以d开头的文件或目录,可以用ls d* 命令,这里*是通配符,它表示匹配重复零次或多次前一字符。
![]()
举一反三,列出以che 开头的文件或目录,就可以用ls che* 命令。
是不是觉得有些觉得过于简单了啊??!!好吧,打完小怪,现在升下级。
开始……
如何列出当前目录下的所有目录(不包含下面的子目录)?
思考……
到了使出正则表达式杀手锏的时候了,在这里,我们还是使用ls 命令,但是加了个 -l选项(-l选项作用是列出文件的详细信息),使用正则表达式列出当前目录下的所有目录,我们给出了两种方法(聪明的你当然会想到也可以用find命令,呵呵,这属于第三种秘笈了)。且看:
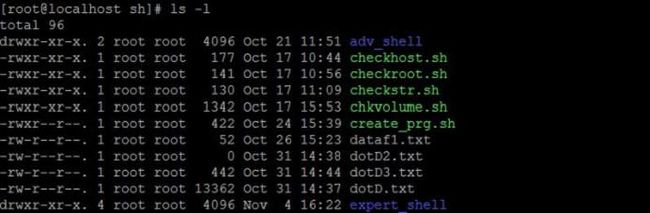
这样列出来的内容有些多,没完全截下来所有显示结果,但这并不妨碍本文的讲解。
考虑到普通文件是以-开头,如dataf1.txt文件;目录是以d 开头的,如 adv_shell 是目录,即第一个字母会不小心暴露出文件的身份属性。
![]()
所以我们就从d这里作为突破口,这时,你会想到,有多少个“开头”的d就应该有多少个目录,太聪明了,好吧,我们按照你的思路实践下。
现在,问题出来了,怎么统计出来有多少个“开头”的d?你想到了linux中grep命令,还想到了正则表达式,于是grep和正则表达式开始粉墨登场了……

ls -l |grep "^d"
这条简单的命令就轻松解决了我们的问题,。"^d"???你纳闷了,这个小东西配合起来怎么会有那么大的威力呢?这好比玩三国杀时刘备、司马懿、香香之间配合的威力……"^d",就是正则表达式的用法,"^"表示匹配行首,"^d"合起来就表示以d开头的一行,grep "^d" 就是过滤出以d开头的那些行,d 表示目录,也就过滤出了当前目录中的所有目录。
谜底解开。现在你又想到,前面不是说还有一种方法的么,既然如此迫不及待,那就只好顺水推舟了。
第二种方法还是基于ls命令,但是用了-F 选项,-F 选项能列出文件类型的指示符号,如下图所示:

仔细观察我们发现,在文件名后面,会多出了一些符号,如目录adv_shell名字后多了条斜扛(/),可执行文件checkhost.sh名字后多了个星号(*)……在此,如果想更多了解这些符号意义,可以查看ls 命令的详细信息。
我们现在把注意力集中到目录adv_shell名字后多了条斜扛(/)这条信息上。很快联想到,有多少个斜扛(/)就应该对应多少目录,而且斜扛(/)会跟在每个目录名的最后。我们又想到了grep命令,还想到了应该怎样用正则表达式表示出匹配行尾,答案已经很接近了……

ls -F | grep "/$"
这条短命令又一切成全了我们的梦想。"/$" 也是正则表达式的用法,"$"表示匹配行尾,"/$"合起来就表示匹配以/结尾的行,grep "/$" 就是过滤出以/结尾的那些行,/表示目录,也就过滤出了当前目录中的所有目录。
在此基础上,我们发散一下思维,比如说想统计当前目录下的文件个数及目录个数,就可以使用以下命令:
ls -l * |grep "^-"|wc -l
ls -l * |grep "^d"|wc -l
好了,暂且休息,下面我们开始介绍更多关于正则表达式的知识。
蓄势
前面我们初识了^ $ * 这些个正则表达式的用法,下面我们将进行更高一级的升炼。
正则表达式是一个字符或和元字符组合成的字符集,它们匹配(或指定)一个模式。字符即普通字符(例如字符 a 到 z),元字符即特殊字符(例如前面提到的字符 ^ $ *)。正则表达式作为一个模板,将某个字符模式与所搜索的字符串进行匹配。
在这里,为简单见,我们不会介绍所有的正则表达式知识,只介绍常用的一些正则表达式知识。
一个正则表达式包含下面一个或多个项:
1.一个字符集
这里的字符集里的字符表示的就是它们字面上的意思.正则表达式最简单的情况就是仅仅由字符集组成,而没有其他的元字符。
2.锚
一个锚指明了正则表达式在一行文本中要匹配的位置,例如^和$就是锚。
3.修饰符
它们用于展开或缩小(即是修改了)正则表达式匹配文本行的范围.修饰符包括了星号、括号和反斜杠符号。
* 匹配重复零次或多次前一字符
+ 匹配一个或多个前面的字符.它的作用和*很相似,但唯一的区别是它不匹配零个字 符的情况
? 匹配零或一个前面的字符。它一般用于匹配单个字符
. 匹配任意字符( 除换行符 )
^ 匹配一行的开头,但依赖于上下文环境,可能在正则表达式中表示否定一个字符 集的意思
[...] 匹配集合中任意字符 如"[xyz]" 匹配字符 x, y, 或z
[^...] 匹配不属集合 中 任意字符
^, $ 匹配 行首、行尾
\<, \> 用于表示单词的边界。\< 匹配词首,\>词尾,如"\<the\>" 匹配单词"the"
\(...\) 正则表达式分组。进行子字符串提取(substring extraction)一起使用很有用
\n 第 n 个分组内容
\ 转义(escapes) 一个特殊的字符,使这个字符表示原来字面上的意思。"\$"表示 了原来的字面意思"$",而不是在正则表达式中表达的匹配行尾的意思."\\"也被 解释成了字面上的意思"\"
\{ \} 指示前面正则表达式匹配的次数.
要转义是因为不转义的话大括号只是表示他们字面上的意思.这个用法只是技巧上 的而不是基本正则表达式的内容."[0-9]\{5\}" 精确匹配5个数字(从0到9的数字).
| "或",正则操作符用于匹配一组可选的字符
{n} n是一个非负整数。匹配确定的n次。例如,''o{2}'' 不能匹配 "Bob"中的''o'',但是能匹配"food" 中的两个o。
{n,} n是一个非负整数。至少匹配n次。例如,''o{2,}'' 不能匹配"Bob"中的'o'',但能匹配 "foooood"中的所有o。''o{1,}''等价于''o+''。''o{0,}''则等价于''o*''。
{n,m} m和n均为非负整数,其中n<=m。最少匹配n次且最多匹配m次。例如,"o{1,3}"将匹配 "fooooood"中的前三个o。''o{0,1}''等价于''o?''。请注意在逗号和两个数之间不能有空格。
\b 匹配一个单词边界,也就是指单词和空格间的位置。例如,''er\b'' 可以匹配"never" 中的''er'',但不能匹配 "verb"中的 ''er''。
\B 匹配非单词边界。''er\B''能匹配"verb"中的''er'',但不能匹配"never"中的 ''er''
\w 匹配包括下划线的任何单词字符。等价于''[A-Za-z0-9_]''。
\W 匹配任何非单词字符。等价于''[^A-Za-z0-9_]''。
\d 匹配一个数字字符。等价于[0-9]。
\D 匹配一个非数字字符。等价于[^0-9]。
\f 匹配一个换页符。等价于\x0c和\cL。
\n 匹配一个换行符。等价于\x0a和\cJ。
\r 匹配一个回车符。等价于\x0d和\cM。
\s 匹配任何空白字符,包括空格、制表符、换页符等等。等价于[\f\n\r\t\v]。
\S 匹配任何非空白字符。等价于[^\f\n\r\t\v]。
\t 匹配一个制表符。等价于\x09 和 \cI。
\v 匹配一个垂直制表符。等价于\x0b和\cK。
常用的就介绍到这里,其它的需要进一步了解可以查阅手册或资料。
翱翔
部分例子
/\b([a-z]+)\1\b/gi 一个单词连续出现的位置
/(\w+):\/\/([^/:]+)(:\d*)?([^# ]*)/ 将一个URL解析为协议、域、端口及相对路径
/^(?:Chapter|Section) [1-9][0-9]{0,1}$/定位章节的位置
/[-a-z]/ A至z共26个字母再加一个-号。
/ter\b/ 可匹配chapter,而不能terminal
/\Bapt/ 可匹配chapter,而不能aptitude
/Windows(?=95 |98 |NT )/ 可匹配Windows95或Windows98或WindowsNT,当找到一个匹配后,从Windows后面开始进行下一次的检索匹配。
下面来些更加高级些的例子。
对于vi 中命令的分析
s/\(^.*$\)\n^.*$/\1/g
初一看,会傻眼,眼前感觉全是$^.*/\……这些符号的闪动。
不要紧,下面慢慢道来。
先给出vi中替换命令的格式。
s/re/string 用string替换正则表达式re
如果在后面加了个g 如: s/re/string/g
表示表示对该行内符合模式的进行全部替换。
例如,s/\//_/g 这个正则表达式就表示,对行内所有的斜扛(/)替成下划线(_),\ /即替换命令格式中的re,用反斜扛\是为了转义,\ /即表示 / 的本意;_即替换命令格式中的string。
好了,了解vi中替换命令的格式后,我们再对细节进行分析。
前面介绍到 \(...\) 表示正则表达式分组,\n表示第 n 个分组内容,于是对于
s/\(^.*$\)\n^.*$/\1/g
中的 \1 ,就表示第一个正则表达式分组即\(^.*$\),我们暂将第一个正则表达式分组\(^.*$\)其记为:A
类推,\2就应该表示第二个正则表达式分组,即 \n^.*$ 实际上 也应该写在括号内比较好:\(\n^.*$\) ,我们也暂将第二个正则表达式分组 \n^.*$ 记为:B
好了,
%s/\(^.*$\)\n^.*$/\1/g
就可以写为:
s/AB/A/g
作用就是将行内所有的AB都替换成A。
现在我们来分别分析A和B的作用。
A=\(^.*$\)
抽取出来实际上是\(...\),表示正则表达式 分组,再分析括号内的^.*$,^代表行首,点号(.)匹配任意字符(除换行符),星号(*)匹配重复零次或多次前一字符,$代表匹配到行尾,综合起来就是:匹配这一行
B=\n^.*$
分析: \n换行,^.*$同上,表示匹配这一行,综合起来就是:下一行(即上行结束后开始的另一行)。
再于是就有:%s/AB/A/g 即将所有AB都替换成B ,代入A和B各自意思得到:
将两行(如行1和行2 )内容替换为第一行内容(即行1的内容),加上/g,就是对全文进行前述替换,也就是隔行删除,如果是从文件第一行开始进行的操作,就意味着是删除所有偶数行、保留所有奇数行操作。
从上面的分析过程中,我们总结出两条有用的正则表达式:
%s/\(^.*$\)\n^.*$/\1/g 删除偶数行
%s/^.*$\n\(^.*$\)/\1/g 删除奇数行
不过瘾的话,还可以再看看另一例子:
sed 's/\(.*\)\(.\)$/\2/'
\2就应该表示第二个正则表达式分组
同上,也将A=/\(.*\),B=\(.\)$,表达式变为's/AB/B',将AB都替换成B 。
分析A、B作用。
A=/\(.*\)
抽取出来实际上是\(...\),表示正则表达式 分组,再分析括号内的 .*,表示匹配任意零个或多个字符 ( 除换行符 )
B=\(.\)$
括号内的 . ,表示匹配任意字符(除换行符) ,括号外的$表示匹配到行尾,即表示行尾的最后一个字符;那上述的A /\(.*\) 就表示该行最后一个字符前的所有字符。
于是sed 's/\(.*\)\(.\)$/\2/' 作用就是:删除该行除最后一个字符外的所有字符,保留最后一个字符,也即取得该行最后一个字符。
好了,正则表达式的介绍就告一段落,知识点比较多,需要平时反复的积累,遇到复杂的正则表达式时首先要克服恐惧的心理,然后按照上面的方法化繁为简,抓住其本质的东西,有如探囊取物,必手到擒来。