数据库系统原理1
第一章
数据库管理技术发展的不同阶段形成不同的特点
数据描述经历了三个阶段对应于三个数据模型
第二章
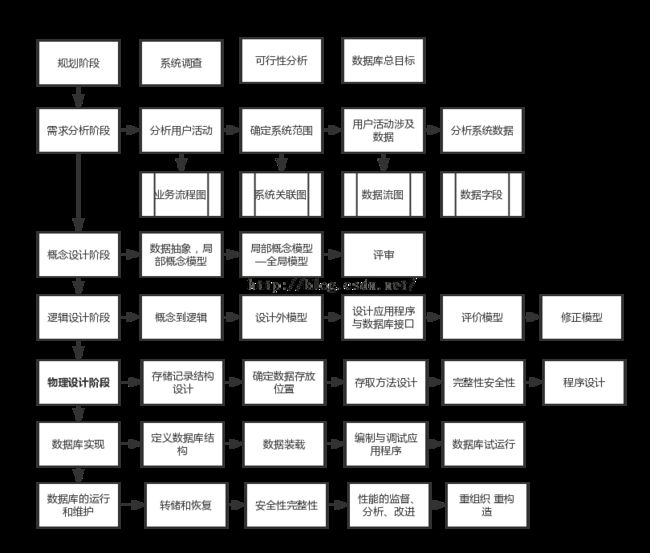
数据库系统的生命周期,书中可能和我们学习软工的时候有些出入,其实就是不同时间有不同的理解,横看成岭侧成峰,多看一些自然可以把握全局
区分超键、候选键、主键,首先看一下他们之间的关系图
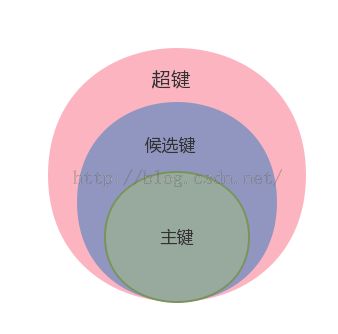
如:在一个班级里假设没有重名的同学,现有四个属性:学号 姓名 年龄 性别
超键:在关系中可以唯一标识元组的属性集。学号是超键;学号、姓名是超键;学号,姓名、性别是超键。所以超键可以是一个属性也可以是一个属性集,只要可以唯一标识就行。
候选键:不含有多余属性的超键。意思就是可以是多个属性确定,如:班里有男生小明和女生小明,现在就可以用姓名和性别来唯一确定他们,如果你删除 其中一个属性就不可以唯一确定了。
主键:用户选作元组标识的候选键。如学号和姓名都是候选键,但是这个时候我选择学号作为唯一标识符,那么它就是主键,主键带有我们的主观色彩。
三类完整性约束
1.实体完整性规则:元组在组成主键属性上不为空
2.参照完整性规则:主键和外键对应
3.用户定义完整性规则:定义数据类型时要满足用户需求
画ER模型
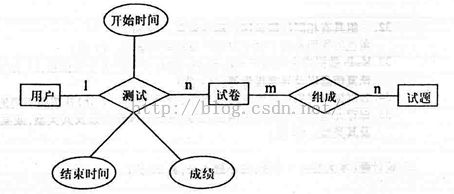
1.图形表示:实体:矩形;属性:椭圆;关系:菱形2.例题:某课程的计算机模拟考试系统涉及的部分信息如下:
用户:用户号、姓名、密码。
试题:试题编号、试题内容、知识点、难度系数、选项A、选B、选项C、选项D、答案。
试卷:试卷编号、生成时间。
说明:允许用户多次登录系统进行模拟测试;每次登录后,测试试卷由系统自动抽题随机生成,即每次生成试卷均不相同;每份试卷由若干试题组成;系统要记录每次测试的起始和结束时间,以及测试成绩。
(1)建立一个反映上述局部应用的ER模型,要求标注联系类型(可省略实体属性)。
分析:
步骤1用矩形把三个实体:用户 试卷 试题表示出来;
步骤2看用户和试卷之间的关系“允许用户多次登录系统进行模拟测试”可知用户:试卷是1:N联系;“系统要记录每次测试的起始和结束时间,以及测试成绩”这个是在测试过程中生成的,所以把三个属性写在关系测试中;
步骤3看试卷和试题的关系:“测试试卷由系统自动抽题随机生成,即每次生成试卷均不相同”可知一份卷子是有许多题组成,每一道题又可以组成许多卷子,所以是M:N的关系,下图即得:
由ER模型转换关系模型:还是上题:
(2)根据转换规则,将ER模型转换成关系模型,要求标注每个关系模型的主键和外键(如果存在)。
分析:
步骤1:用户,用户的主键是用户名,在用户:试卷=1:N,所以用户的主键用户号应该写在试卷中作为外键
步骤2:试卷同上,把用户名作为他的外键
步骤3:在试卷和试题之间是M:N的关系,他们的属性按照原来的写不用变,但是需要把试卷和试题的主键提取出来作为主键,建立一个新的关系模型,注意:因为他们都是外键所以每个下面要写波浪线,他们两个是主键,所以要画一条直线

其他的ER模型和关系模型题基本就是这个思路了。
第三章
每个关系模型只对应一个实体类型或一个联系类型
1.闭包
如:设有关系模式R(ABCDEG),F是R上成立的FD集,F={D→G,C→A,CD→E,A→B},则(AC)+F为
分析:先分别看A、C、AC根据关系F={D→G,C→A,CD→E,A→B},可以推出什么,A->B,所以闭包变成(ABC)F,然后再看A、B、C、AB、AC、BC、ABC分别可以推出什么即可,因为没有可以推出的,所以为ABC
2.无损分解:刚鹏写的非常好,就不写了,嘿嘿谈模式分解——表的分解
3.范式
第一范式:如果关系模式R中的每个关系r的属性都是不可分的原子
第二范式:如果关系为1NF,且每个非主属性完全依赖于候选键(不存在局部依赖)
第三范式:如果关系是1NF,且每个非主属性都不传递依赖于R的候选键
例题:设某校教材管理系统中,有一个记录各班级领用教材情况的关系模式:
R(教材编号,教材名称,出版社,班级号,领用时间,领用数量)
如果规定:每个班级每次可领用多种教材,但每种教材只允许领用一次;同一种教材可被不同班级领用;不同班级可同时领用教材。
分析:
第一范式:教材编号->教材名称;教材编号->出版社;(班级号,教材编号)->领用时间;(班级号,教材编号)->领用数量。 关键码(班级号,教材编号)
第三范式:R1(教材编号,教材名称,出版社) R2(班级号,教材编号,领用时间,领用数量)
第四章
前言:
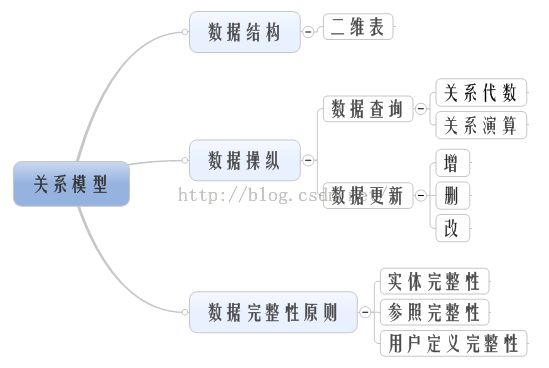
关系代数:查询操作是以谓词演算为基础的运算
关系代数的五个基本操作
关系代数的四个组合操作
外连接:R和S做自然连接时,把原来应该舍弃的元组也保留在新关系中,同时在这些元组新增加的属性上填上空值
优化:尽可能早地执行选择操作,投影操作,避免直接做笛卡尔积
关系演算:查询操作是以集合操作为基础的运算
元组关系演算
例如:
R(s):R是关系名,s是元组变量。s是R的一个元组。
s[i]θu[j]:s和u是元组变量,θ是算术比较运算符,s[i]表示s元组的第i个分量。元组s的第i个分量和元组u的第j个分量满足θ关系。
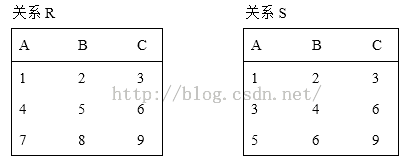
1)R1={t|S(t)∧t[1]>2}表示:关系S的第1列中大于2的数对应的行截取留下组成新的关系表。即如下:
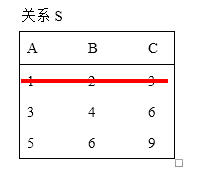
2)R2={t|(∃u)(S(t)∧R(u)∧t[3]<u[2])}表示:关系S中的元组为t,关系R中的元组为u,在S表中,S的第三列的数<R的第二列的数其中的一个(∃)
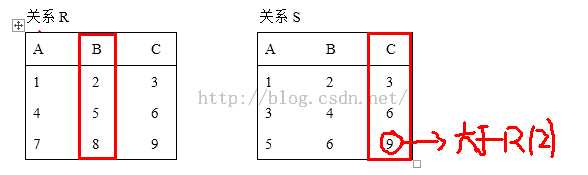
所以在S表中除去最后一列即可得
域关系演算
用域变量代替元组的每一个分量,这个和上的类似,如上图的关系R1={t|S(t)∧t[1]>2}可以表示
R1={xyz|S(xyz)∧x>2}其实就是用xyz把关系的每一列表示出来
尾音:喜欢盲人摸象的故事,剥丝抽茧一点点得到真相。