机器学习实践中12条教训
今天看了一篇论文:A Few Useful Things to Know about Machine learning http://vdisk.weibo.com/s/hxqSZfjTE0X 文章中提到机器学习实践中12条教训,受益匪浅,因为自己本身ML功力还不够,其中有一些东西理解也不是很到位,写这篇文章也是喜欢大家能多交流互相学习,感谢大家指教!
现在有很多类型机器学习算法,文章为了描述问题,专注于成熟并且广泛应用的分类机器学习算法上。
1. Learning = Representation + Evaluation + Optimazation
Representation : 一个分类器一定可以被计算机能处理的形式语言来表示 ,选择一个Representation 就是选择一个假设空间。
Evaluation : 能够区分开来什么是好的和坏的分类器
Optimazation : 在所有分类器中找到最好的分类器,最优化的效率是学习的关键。下图是几个算法这三部分实例:
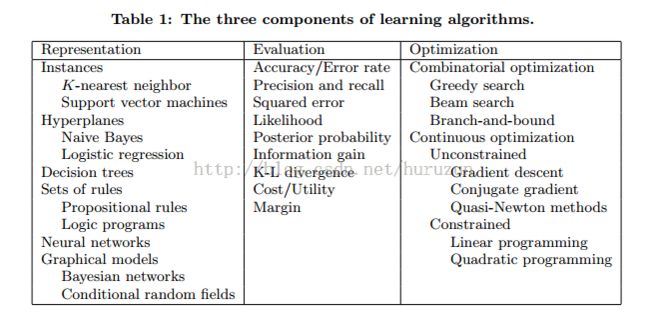
2. It‘s Generalization that counts
提高泛化能力才是重要的。我们在训练集上我们可以训练很好效果,但是一到测试集效果却下降很多,这就是算法的泛化能力不够。这里泛化能力就引出欠拟合与过度拟合概念,在这篇博文有介绍:http://blog.csdn.net/huruzun/article/details/41457433
3. Data alone is not enough
这条教训的中心思想是:只有数据是肯定不够的,我们需要将应用领域知识或者假设应用在数据上,然后产生机器学习模型。文章中提到了"no free lunch"理论形象的描述了这一点。完全基于数据不依赖知识和假设的模型不一定能超过随机的猜测模型。 像演绎、归纳(deduction、induction)就是知识水平的概念。
举例说明: 如果有很多例子特定域的相似性,基于实例的方法可能是一个好的选择。如果有概率依赖关系,则图模型可能是好的选择等。
4. Overfitting has many faces
这里已经有对这个问题一个介绍:http://blog.csdn.net/huruzun/article/details/41457433
需要补充的是,关于overfitting 的一个普遍错觉是,overfitting是因为噪音引起的,像训练数据的错误类标记。这些确实会加重overfitting,严重的overfitting问题可能在没有任何噪音数据的模型中发生。
5. Intuition fails in high demensions
机器学习中最大问题或者挑战就是:"curse of dimensionality" 也就是维灾难。 很多算法在低维数据上效果很好,一旦到了高维数据就变得非常棘手问题。
随着维度增加模型产生复杂度指数增加,除了复杂度增加,维度增加可能导致以前低维算法无法使用,例如:最近邻算法在低维(2维或三维)使用Hamming distance 衡量相似性,如果现在有100个特征,其中只有1,2特征用到,这样高维度的最近邻算法跟随机预测没有什么区别。人们通常认为收集更多的特征没有坏处,因为最坏情况下也只是不能给建模提供信息,但是实际是 "curse of dimensionality" 很可能超过收集更多特征收益。
6. Theoretical guarantees are not what they seem
机器学习是充满着理论依据,理论依据不是实际决定的标准而是一个理解和驱动算法设计的动力。
7. Feature engineering is the key
Feature engineering 是一个domain-specific
8. More data beats a cleverer algorithm
提升分类器效果两个途径,设计一个更好的算法、收集更多的数据。
实践中收集更多数据是更好更快捷构建更好模型的办法
9. Learn many models , not just one
这里的主体思想就是 ensembles method (集成学习),见 http://blog.csdn.net/huruzun/article/details/41323065
10. Simplicity does not imply accuracy
11. Representable does not imply learnable
12. Correlation does not imply causation