Flume-ng 1.6.0安装、配置与使用
1. 介绍
Flume NG是Cloudera提供的一个分布式、可靠、可用的系统,它能够将不同数据源的海量日志数据进行高效收集、聚合、移动,最后存储到一个中心化数据存储系统中。由原来的Flume OG到现在的Flume NG,进行了架构重构,并且现在NG版本完全不兼容原来的OG版本。经过架构重构后,Flume NG更像是一个轻量的小工具,非常简单,容易适应各种方式日志收集,并支持failover和负载均衡。
Flume 使用 java 编写,其需要运行在 Java1.6 或更高版本之上。
- 官方网站:http://flume.apache.org/
- 用户文档:http://flume.apache.org/FlumeUserGuide.html
- 开发文档:http://flume.apache.org/FlumeDeveloperGuide.html
2. 架构
Flume的架构主要有一下几个核心概念:
- Event:一个数据单元,带有一个可选的消息头
- Flow:Event从源点到达目的点的迁移的抽象
- Client:操作位于源点处的Event,将其发送到Flume Agent
- Agent:一个独立的Flume进程,包含组件Source、Channel、Sink
- Source:用来消费传递到该组件的Event
- Channel:中转Event的一个临时存储,保存有Source组件传递过来的Event
- Sink:从Channel中读取并移除Event,将Event传递到Flow Pipeline中的下一个Agent(如果有的话)
2.1 数据流
Flume 的核心是把数据从数据源收集过来,再送到目的地。为了保证输送一定成功,在送到目的地之前,会先缓存数据,待数据真正到达目的地后,删除自己缓存的数据。
Flume 传输的数据的基本单位是 Event,如果是文本文件,通常是一行记录,这也是事务的基本单位。Event 从 Source,流向 Channel,再到 Sink,本身为一个 byte 数组,并可携带 headers 信息。Event 代表着一个数据流的最小完整单元,从外部数据源来,向外部的目的地去。
Flume 运行的核心是 Agent。它是一个完整的数据收集工具,含有三个核心组件,分别是 source、channel、sink。通过这些组件,Event 可以从一个地方流向另一个地方,如下图所示。
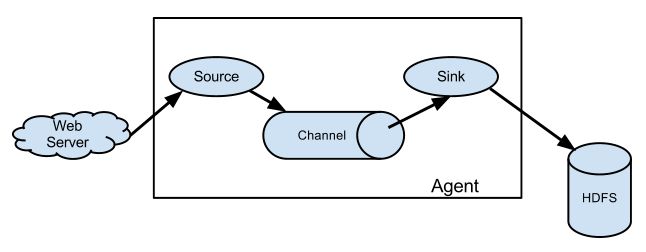
- source 可以接收外部源发送过来的数据。不同的 source,可以接受不同的数据格式。比如有目录池(spooling directory)数据源,可以监控指定文件夹中的新文件变化,如果目录中有文件产生,就会立刻读取其内容。
- channel 是一个存储地,接收 source 的输出,直到有 sink 消费掉 channel 中的数据。channel 中的数据直到进入到下一个channel中或者进入终端才会被删除。当 sink 写入失败后,可以自动重启,不会造成数据丢失,因此很可靠。
- sink 会消费 channel 中的数据,然后送给外部源或者其他 source。如数据可以写入到 HDFS 或者 HBase 中。
2.2 核心组件
2.2.1 source
Client端操作消费数据的来源,Flume 支持 Avro,log4j,syslog 和 http post(body为json格式)。可以让应用程序同已有的Source直接打交道,如AvroSource,SyslogTcpSource。也可以 写一个 Source,以 IPC 或 RPC 的方式接入自己的应用,Avro和 Thrift 都可以(分别有 NettyAvroRpcClient 和 ThriftRpcClient 实现了 RpcClient接口),其中 Avro 是默认的 RPC 协议。具体代码级别的 Client 端数据接入,可以参考官方手册。
对现有程序改动最小的使用方式是使用是直接读取程序原来记录的日志文件,基本可以实现无缝接入,不需要对现有程序进行任何改动。 对于直接读取文件 Source,有两种方式:
- ExecSource: 以运行 Linux 命令的方式,持续的输出最新的数据,如
tail -F 文件名指令,在这种方式下,取的文件名必须是指定的。 ExecSource 可以实现对日志的实时收集,但是存在Flume不运行或者指令执行出错时,将无法收集到日志数据,无法保证日志数据的完整性。 - SpoolSource: 监测配置的目录下新增的文件,并将文件中的数据读取出来。需要注意两点:拷贝到 spool 目录下的文件不可以再打开编辑;spool 目录下不可包含相应的子目录。
SpoolSource 虽然无法实现实时的收集数据,但是可以使用以分钟的方式分割文件,趋近于实时。
如果应用无法实现以分钟切割日志文件的话, 可以两种收集方式结合使用。 在实际使用的过程中,可以结合 log4j 使用,使用 log4j的时候,将 log4j 的文件分割机制设为1分钟一次,将文件拷贝到spool的监控目录。
log4j 有一个 TimeRolling 的插件,可以把 log4j 分割文件到 spool 目录。基本实现了实时的监控。Flume 在传完文件之后,将会修改文件的后缀,变为 .COMPLETED(后缀也可以在配置文件中灵活指定)。
Flume Source 支持的类型:
| Source类型 | 说明 | |
|---|---|---|
| Avro Source | 支持Avro协议(实际上是Avro RPC),内置支持 | |
| Thrift Source | 支持Thrift协议,内置支持 | |
| Exec Source | 基于Unix的command在标准输出上生产数据 | |
| JMS Source | 从JMS系统(消息、主题)中读取数据,ActiveMQ已经测试过 | |
| Spooling Directory Source | 监控指定目录内数据变更 | |
| Twitter 1% firehose Source | 通过API持续下载Twitter数据,试验性质 | |
| Netcat Source | 监控某个端口,将流经端口的每一个文本行数据作为Event输入 | |
| Sequence Generator Source | 序列生成器数据源,生产序列数据 | |
| Syslog Sources | 读取syslog数据,产生Event,支持UDP和TCP两种协议 | |
| HTTP Source | 基于HTTP POST或GET方式的数据源,支持JSON、BLOB表示形式 | |
| Legacy Sources | 兼容老的Flume OG中Source(0.9.x版本) |
2.2.2 Channel
当前有几个 channel 可供选择,分别是 Memory Channel, JDBC Channel , File Channel,Psuedo Transaction Channel。比较常见的是前三种 channel。
- MemoryChannel 可以实现高速的吞吐,但是无法保证数据的完整性。
- MemoryRecoverChannel 在官方文档的建议上已经建义使用FileChannel来替换。
- FileChannel保证数据的完整性与一致性。在具体配置FileChannel时,建议FileChannel设置的目录和程序日志文件保存的目录设成不同的磁盘,以便提高效率。
File Channel 是一个持久化的隧道(channel),它持久化所有的事件,并将其存储到磁盘中。因此,即使 Java 虚拟机当掉,或者操作系统崩溃或重启,再或者事件没有在管道中成功地传递到下一个代理(agent),这一切都不会造成数据丢失。Memory Channel 是一个不稳定的隧道,其原因是由于它在内存中存储所有事件。如果 java 进程死掉,任何存储在内存的事件将会丢失。另外,内存的空间收到 RAM大小的限制,而 File Channel 这方面是它的优势,只要磁盘空间足够,它就可以将所有事件数据存储到磁盘上。
Flume Channel 支持的类型:
| Channel类型 | 说明 |
|---|---|
| Memory Channel | Event数据存储在内存中 |
| JDBC Channel | Event数据存储在持久化存储中,当前Flume Channel内置支持Derby |
| File Channel | Event数据存储在磁盘文件中 |
| Spillable Memory Channel | Event数据存储在内存中和磁盘上,当内存队列满了,会持久化到磁盘文件(当前试验性的,不建议生产环境使用) |
| Pseudo Transaction Channel | 测试用途 |
| Custom Channel | 自定义Channel实现 |
2.2.3 sink
Sink在设置存储数据时,可以向文件系统、数据库、hadoop存数据,在日志数据较少时,可以将数据存储在文件系中,并且设定一定的时间间隔保存数据。在日志数据较多时,可以将相应的日志数据存储到Hadoop中,便于日后进行相应的数据分析。
Flume Sink支持的类型
| Sink类型 | 说明 |
|---|---|
| HDFS Sink | 数据写入HDFS |
| Logger Sink | 数据写入日志文件 |
| Avro Sink | 数据被转换成Avro Event,然后发送到配置的RPC端口上 |
| Thrift Sink | 数据被转换成Thrift Event,然后发送到配置的RPC端口上 |
| IRC Sink | 数据在IRC上进行回放 |
| File Roll Sink | 存储数据到本地文件系统 |
| Null Sink | 丢弃到所有数据 |
| HBase Sink | 数据写入HBase数据库 |
| Morphline Solr Sink | 数据发送到Solr搜索服务器(集群) |
| ElasticSearch Sink | 数据发送到Elastic Search搜索服务器(集群) |
| Kite Dataset Sink | 写数据到Kite Dataset,试验性质的 |
| Custom Sink | 自定义Sink实现 |
更多sink的内容可以参考官方手册。
2.3 可靠性
Flume 的核心是把数据从数据源收集过来,再送到目的地。为了保证输送一定成功,在送到目的地之前,会先缓存数据,待数据真正到达目的地后,删除自己缓存的数据。
Flume 使用事务性的方式保证传送Event整个过程的可靠性。Sink 必须在 Event 被存入 Channel 后,或者,已经被传达到下一站agent里,又或者,已经被存入外部数据目的地之后,才能把 Event 从 Channel 中 remove 掉。这样数据流里的 event 无论是在一个 agent 里还是多个 agent 之间流转,都能保证可靠,因为以上的事务保证了 event 会被成功存储起来。而 Channel 的多种实现在可恢复性上有不同的保证。也保证了 event 不同程度的可靠性。比如 Flume 支持在本地保存一份文件 channel 作为备份,而memory channel 将 event 存在内存 queue 里,速度快,但丢失的话无法恢复。
2.4 可恢复性
3. Flume安装与配置
3.1 Flume安装
tar -zxvf apache-flume-1.6.0-bin.tar.gz配置系统环境变量:
vi /etc/profile 添加: export FLUME_HOME=/home/hadoop1/bms/flume-1.6.0 export FLUME_CONF_DIR=$FLUME_HOME/conf export PATH=$PATH:$FLUME_HOME/bin
sorce /etc/profile
export JAVA_HOME=/home/hadoop1/bms/jdk1.8.0_65 exportJAVA_OPTS="-Xms100m -Xmx2000m -Dcom.sun.management.jmxremote"
#把配置好的flume分发到slave1节点,同时配置slave1节点的环境变量 scp flume-1.6.0 hadoop1@slave1:/home/hadoop1/bms/
3.2 Flume的conf下属性文件配置
这一部分是最终要的,决定了source、channel、sink的连接,也决定了Flume的使用。下面实例,为下图所示通信,将监视一台服务器的文档的变化,并将变化写入hdfs中。slave1节点为监视文件的agent,并sink即将数据发送到master中,master负责将收到的文件写入hdfs中。
#Name the components on this agent a1.sources= r1 a1.sinks= k1 a1.channels= c1 #Describe/configure the source a1.sources.r1.type= avro a1.sources.r1.channels= c1 a1.sources.r1.bind= master a1.sources.r1.port= 44444 #Describe the sink #a1.sinks.k1.type= logger #a1.sinks.k1.channel = c1 a1.sinks.k1.type=hdfs a1.sinks.k1.hdfs.useLocalTimeStamp=true a1.sinks.k1.hdfs.path=hdfs://master:9000/flume-dir/%Y%m%d%H%M%S a1.sinks.k1.hdfs.filePrefix=log a1.sinks.k1.hdfs.fileType=DataStream a1.sinks.k1.hdfs.writeFormat=TEXT a1.sinks.k1.hdfs.rollInterval=10 a1.sinks.k1.hdfs.rollCount=0 a1.sinks.k1.hdfs.rollSize=0 a1.sinks.k1.channel=c1 #Use a channel which buffers events in memory a1.channels.c1.type= memory a1.channels.c1.keep-alive= 50 a1.channels.c1.capacity= 100000 a1.channels.c1.transactionCapacity= 100000
slave1节点中配置$FLUME_HOME/conf/pushtail.conf,其内容如下:
#Name the components on this agent a2.sources= r1 a2.sinks= k1 a2.channels= c1 #Describe/configure the source #a2.sources.r1.type= spooldir #a2.sources.r1.spoolDir= /home/hadoop1/asia/test #a2.sources.r1.channels= c1 a2.sources.r1.type = exec a2.sources.r1.command = tail -F /home/hadoop1/asia/asia.log a2.sources.r1.channels = c1 #Use a channel which buffers events in memory a2.channels.c1.type= memory a2.channels.c1.keep-alive= 2 a2.channels.c1.capacity= 100000 a2.channels.c1.transactionCapacity= 100000 #Describe/configure the source a2.sinks.k1.type= avro a2.sinks.k1.channel= c1 a2.sinks.k1.hostname= master a2.sinks.k1.port= 44444
以下都是在$FLUME_HOME下运行,首先启动master节点上agent,在运行slave1上的agent,命令如下: master: bin/flume-ng agent -c conf -f conf/pulltail.conf -n a1 -Dflume.root.logger=INFO,console slave1: flume-ng agent -n a2 -c conf -f conf/pushtail.conf -Dflume.root.logger=INFO,console
参数说明: