递归
递归是一种强大的方法,它允许一个对象以其自身更小的形式来定义自己。在计算机科学中,递归是通过递归函数来实现的。递归函数是一种可以调用自身的函数。递归可以分为基本递归和尾递归。
基本递归:一种强大的方法,允许一个问题以其自身越来越小的形式来定义自己。
尾递归:如果一个函数中所有递归形式的调用都出现在函数的末尾,我们称这个递归函数是尾递归的。当递归调用是整个函数体中最后执行的语句且它的返回值不属于表达式的一部分时,这个递归调用就是尾递归。尾递归函数的特点是在回归过程中不用做任何操作,这个特性很重要,因为大多数现代的编译器会利用这种特点自动生成优化的代码。(摘自百度百科)
基本递归
当我们通过编程来解决阶乘问题时,我们第一反应通常都是递归。阶乘的递归定义为:
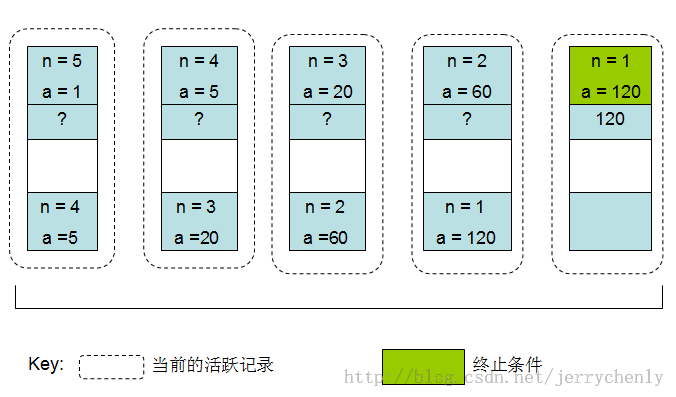
下图展示了利用递归的方法计算5!的过程。在递推阶段,每一个递归的调用进一步调用自己来记住这次递归过程。当其中有调用满足终止条件时,递推结束。一旦递推阶段结束,处理过程就进入回归阶段,在这之前的函数调用以逆序的方式回归,直到最初调用的函数返回为止,此时递归结束。
下面是递归方式计算阶乘的函数实现:
int recursion(int n){
if(n<0){
return 0;//错误参数
}else if(n==0||n==1){
return 1;//终止条件
}else{
return n* recursion(n-1);
}
}
递归究竟是如何工作的?为了理解递归的工作过程,先看看C语言中函数的执行方式。基于这点,我们需要先了解一点关于C程序在内存中的组织方式。
基本上说一个可执行程序由4个区域组成:代码段、静态数据区、堆和栈(见下图)。代码段包含程序包含程序运行时所执行的机器指令。静态数据区包含在程序生命周期内一直持久的数据,比如全局变量和静态局部变量。堆包含程序运行时动态分配的存储空间,比如用malloc分配的内存。栈包含函数调用的信息。按照惯例,堆的增长方向为从程序低地址到高地址增长,而栈的增长方向刚好相反(实际情况可能不是这样,与CPU的体系结构有关)。
当C程序中调用一个函数时,栈中会分配一块空间来保存与这个调用相关的信息。每一个调用都被当做是活跃的。栈上的那块存储空间成为活跃记录,或者称为栈帧。栈帧由5个区域组成:输入参数、返回值空间、计算表达式时用到的临时存储空间、函数调用时保存的状态信息以及输出参数。输入参数是传递到活跃记录中的参数;输出参数是传递给在活跃记录中调用的函数所使用的。一个活跃记录中的输出参数就成为下一个活跃记录的输入参数。函数调用产生的活跃记录将一直存在于栈中直到这个函数调用结束。
再来看上面的递归计算阶乘的示例程序,当计算5!时栈中都发生了些什么(如下图所示)。初始调用recursion会在栈中产生一个活跃记录,输入参数n=5。由于这个调用没有满足函数的终止条件,因此recursion将继续以n=4为参数递归调用。这将在栈上创建另一个活跃记录。这里n=4是第一个活跃期中的输出参数,因为正是在第一个活跃期内调用recursion产生了第二个活跃期。这个过程将一直继续,直到n的值变为1,此时满足终止条件,recursion将返回1。一旦当n=1时的活跃期结束,n=2时的递归计算结果就是2x1=2,因而n=2时的活跃期也将结束,返回值为2。结果就是n=3时的递归计算结果表示为3x2=6,因此n=3时的活跃期结束,返回值为6。然后就是n=4时的递归计算结果将表示为6x4=24,n=4时的活跃期将结束,返回值24。最后n=5时的递归计算结果表示为5x24=120,n=5时的活跃期将结束,返回值120。此时函数已从最初的调用中返回,递归过程结束。
栈是用来存储函数调用信息的绝好方案,这正是由于其后进先出的特点精确满足了函数调用和返回的顺序。然而,使用栈也有一些缺点。栈维护了每个函数调用的信息直到函数返回后才释放,这需要占用大量的空间,尤其是在程序中使用了许多递归调用的情况下。除此之外,因为有大量的信息需要保存和恢复,因此生成和销毁活跃记录需要耗费一定的时间。如此一来当函数调用的开销变得很大时,我们就需要考虑应该采用其他方案。幸运的是,我们可以采用一种称为尾递归的特殊递归方式来避免上面提到的这些缺点。
尾递归
上面尾递归定义中提到,尾递归函数的特点是在回归过程中不用做任何操作。这个特性很重要,因为大多数现代编译器会利用这种特点自动生成优化的代码。
当编译器检测到一个函数调用是尾递归的时候,它就覆盖当前的活跃记录而不是在栈中去创建一个新的。编译器可以做到这点,因为递归调用是当前活跃期内最后一条待执行的语句,于是当这个调用返回时栈帧中并没有其他事情可做,因此也就没有保存栈帧的必要了。通过覆盖当前的栈帧而不是在其之上重新添加一个,这样所使用的栈空间就大大缩减了,这使得实际的运行效率会变得更高。因此,只要有可能我们就需要将递归函数写成尾递归的形式。
为了理解尾递归是如何工作的,让我们再次以递归的形式计算阶乘。首先,这可以很容易让我们理解为什么上面所定义的计算阶乘的递归不是尾递归。上面计算n!的定义:在每个活跃期计算n倍的(n-1)!的值,让n=n-1并持续这个过程直到n=1为止。这种定义不是尾递归的,因为每个活跃期的返回值都依赖于用n乘以下一个活跃期的返回值,因此每次调用产生的栈帧将不得不保存在栈上直到下一个子调用的返回值确定。现在让我们考虑以尾递归的形式来定义计算n!的过程。函数可以定义成如下形式:
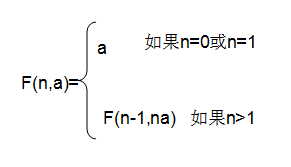
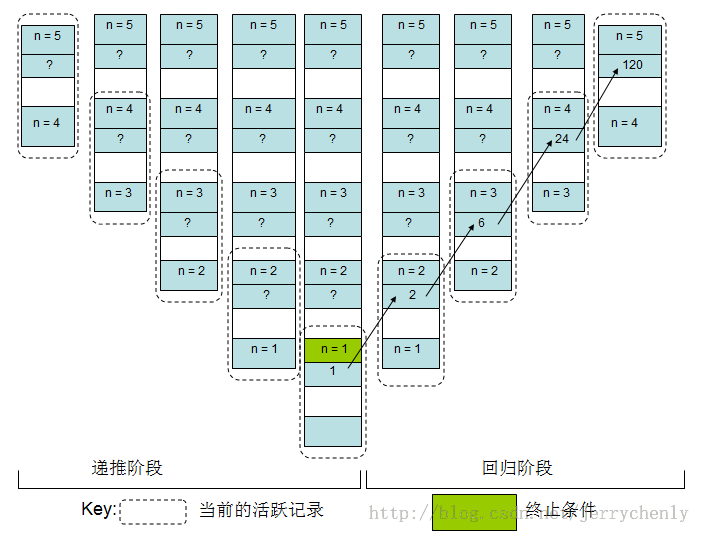
这种定义还需要接受第二个参数a。a(初始化值为1)维护递归层次的深度。这就让我们避免了每次还需要将返回值再乘以n。然而,在每次递归调用中,令a=na并且n=n-1。继续递归调用,直到n=1,这满足结束条件,此时直接返回a即可。下图说明了尾递归计算5!的过程。注意在回归过程中不需要做任何操作,这是所有尾递归函数的标志。

下面是尾递归方式计算阶乘的函数实现:
int tail_recursion(int n,int a){
if(n<0){
return 0;
}else if(n==0){
return 1;
}else if(n==1){
return a;
}else{
return tail_recursion(n-1,n*a);
}
}
上面函数是尾递归的,因为对tail_recursion的单次递归调用是函数返回前最后执行的一条语句。在tail_recursion中碰巧最后一条语句也是对tail_recursion的调用,但这并不是必需的。换句话说,在递归调用之后还可以有其他的语句执行,只是它们只能在递归调用没有执行时才可以执行。下图展示了当使用尾递归函数计算5!时栈的使用情况。