PAT 习题
http://www.patest.cn/contests/pat-a-practise
今年报了PAT的考试,做一下题,持续更新直到考完吧,orz。。有点担心。
orz。。考完了,差一组样例没过,没100啥也没用,桑心~~还需努力。TT -2016.03.12
1001
题意:给出a+b,计算c=a+b,将c输出时每三个数加一个“,”
思路:数据范围比较小,根据特殊的数据范围,也可特殊求解,不解释
#include<iostream>
#include<cstdio>
#include<cstring>
#include<string>
#include<cmath>
#include<algorithm>
using namespace std;
int main()
{
int a,b,c,d;
cin>>a>>b;
c=a+b,d=abs(c);
if(d<1000)
printf("%d\n",c);
else if(d<1000000)
printf("%d,%03d",c/1000,d%1000);
else
printf("%d,%03d,%03d",c/1000000,(d%1000000)/1000,d%1000);
return 0;
}1002
题意:给出两个多项式系数和指数,将两个多项式相加,输出相加后的多项式的系数和指数
思路:暴力,要注意的是当系数为0的时候该项不需要输出,也不需要计算到最后的项数中去。因此要做一些处理
#include<iostream>
#include<cstdio>
#include<cstring>
#include<string>
#include<cmath>
#include<algorithm>
#include<map>
using namespace std;
map<int,double> mp;
int main()
{
int k,N;
double a;
cin>>k;
while(k--)
{
cin>>N>>a;
mp.insert(pair<int,double>(N,a));
}
cin>>k;
while(k--)
{
cin>>N>>a;
if(mp.find(N) == mp.end())
mp.insert(pair<int,double>(N,a));
else
mp[N] += a;
}
int tmpout=0;
map<int,double>::iterator it=mp.end();
while(it!=mp.begin()){
it--;
if(fabs(it->second) < 0.01) continue;
tmpout++;
}
cout<<tmpout;
it=mp.end();
while(it!=mp.begin()){
it--;
if(fabs(it->second) < 0.01) continue;
printf(" %d %.1lf",it->first,it->second);
}
cout<<endl;
return 0;
}1003
题意:N个点,M条边,起点s,终点e,每个点有对应的team数,要求计算s到e的最短路径有几条,在最短路径中team数最多的路径的team数之和。
思路:可以用dijkstra计算最短路径,计算的同时处理team数。
#include<iostream>
#include<cstdio>
#include<cstring>
#include<string>
#include<cmath>
#include<algorithm>
#include<map>
using namespace std;
const int Maxn = 550;
const int INF = 0x7fffffff;
struct node{
int team;//team数
int dis;//记录距离
int Max;//最大的team数
int num;//路径数
bool flag;
};
int dis[Maxn][Maxn];
node point[Maxn];
int N,M;
void dijkstra(int s,int e)
{
for(int i = 0;i < N;i ++)
{
int Min = INF;
int k;
for(int j = 0;j < N;j ++)
{
if(point[j].flag == false && point[j].dis < Min)
{
Min = point[j].dis;
k = j;
}
}
point[k].flag = true;
for(int j = 0;j < N;j ++)
{
if(dis[k][j] != INF)
{
if(dis[k][j] + point[k].dis < point[j].dis)
{
point[j].dis = point[k].dis + dis[k][j];
point[j].num = point[k].num;//这里计算num时要注意,一开始想单纯了,不是令point[j].num=1,与point[k]的num有关,orz
point[j].Max = point[k].Max + point[j].team;
}
else if(dis[k][j] + point[k].dis == point[j].dis)
{
point[j].num +=point[k].num;
point[j].Max = max(point[j].Max,point[k].Max + point[j].team);
}
}
}
}
cout<<point[e].num<<" "<<point[e].Max<<endl;
}
int main()
{
int s,e;
int x,y,d;
cin>>N>>M>>s>>e;
for(int i = 0;i < N;i ++)
{
cin>>point[i].team;
point[i].dis = INF;
point[i].Max = 0;
point[i].flag = false;
point[i].num = 0;
}
for(int i = 0;i < N;i ++)
for(int j = 0;j < N;j ++)
{
if(i == j) dis[i][j] = 0;
dis[i][j] = dis[j][i] = INF;
}
for(int i = 0;i < M;i ++)
{
cin>>x>>y>>d;
dis[x][y] = dis[y][x] = d;
}
point[s].dis = 0;
point[s].num = 1;
point[s].Max = point[s].team;
dijkstra(s,e);
return 0;
}1004
题意:给出家谱树,知道对应的父与子的关系,要求求出最后构成的这棵树中每一层有多少个叶子节点。
思路:我不知道数据中会不会有多个父节点指向同一个子节点,所以直接都当成森林来做了,记录每个父与子的关系,得到root节点,dfs一下,计算每层的子节点即可。这里要注意的是节点的编号应该是从1开始的,不是从0开始的。。。
#include<iostream>
#include<cstdio>
#include<cstring>
#include<string>
#include<cmath>
#include<algorithm>
#include<vector>
#include<set>
using namespace std;
const int Maxn = 110;
int N,M;
bool flag[Maxn];
int maxLevel;
vector<int> vec[Maxn];
set<int> se[Maxn];
void dfs(int s,int level)
{
maxLevel = max(maxLevel,level);
if(vec[s].size() == 0)
{
se[level].insert(s);
return;
}
for(int i = 0;i < vec[s].size();i ++)
{
dfs(vec[s][i],level + 1);
}
}
int main()
{
cin>>N>>M;
int a,b,k;
for(int i = 0;i < M;i ++)
{
cin>>a>>k;
for(int j = 0;j < k;j ++)
{
cin>>b;
vec[a].push_back(b);
flag[b] = true;
}
}
for(int i = 1;i <= N;i ++)
{
if(flag[i] == false)
{
dfs(i,0);
}
}
// cout<<maxLevel<<endl;
for(int i = 0; i <= maxLevel;i ++)
{
if(i == 0)
cout<<se[i].size();
else
cout<<" "<<se[i].size();
}
cout<<endl;
return 0;
}
1005
题意:给出非0整数N,求出N的每一位相加后的值,输出结果值每一位上的数字对用的英文字母
思路:N很大,用string输入,结果很小,最大为9*100=900,随意直接判断结果然后输出就好了。注意对应的英文别写错就好了,就像我把nine写成了night,醉了
#include<iostream>
#include<cstdio>
#include<cstring>
#include<string>
#include<cmath>
#include<algorithm>
using namespace std;
string num[10] = {"zero","one","two","three","four","five","six","seven","eight","nine"};
int main()
{
string s;
cin>>s;
int ans = 0;
for(int i = 0;i <s.length();i ++)
ans += (s[i] - '0');
if(ans >= 100)
cout<<num[ans/100]<<" "<<num[(ans%100)/10]<<" "<<num[ans%10]<<endl;
else if(ans >= 10)
cout<<num[ans/10]<<" "<<num[ans % 10]<<endl;
else
cout<<num[ans]<<endl;
return 0;
}
1006
题意:给出N个人的打卡信息,包括姓名、开门时间、关门时间。要求计算出开门人的姓名和关门人的姓名。
思路:根据开门时间和关门时间排序一发就行。(因为没给出N的范围,我在输入N后再开辟空间,竟也能过,如果N太大,person数组应该放到main函数外面,省的空间不够)
#include<iostream>
#include<cstdio>
#include<cstring>
#include<string>
#include<cmath>
#include<algorithm>
using namespace std;
struct person{
string name;
string in_time;
string out_time;
bool operator<(const person& x) const
{
return in_time < x.in_time;
}
};
bool cmp(person x,person y)
{
return x.out_time > y.out_time;
}
int main()
{
int N;
cin>>N;
person p[N];
for(int i = 0;i < N;i ++)
{
cin>>p[i].name>>p[i].in_time>>p[i].out_time;
}
sort(p,p+N);
cout<<p[0].name;
sort(p,p+N,cmp);
cout<<" "<<p[0].name<<endl;
return 0;
}
1007
题意:给出一个序列,要求和最大的子序列,并输出子序列和sum,该子序列的第一个值和最后一个值。(注:当和为负时,输出0,序列的第一个值和最后一个值)
思路:dp
#include<iostream>
#include<cstdio>
#include<cstring>
#include<string>
#include<cmath>
#include<algorithm>
using namespace std;
const int Maxn = 10010;
int dp[Maxn];
int N,num[Maxn],s[Maxn];
int main()
{
cin>>N;
for(int i = 0;i < N;i ++)
cin>>num[i];
dp[0] = num[0];
s[0] = 0;
int Max = dp[0],k = 0;
for(int i = 1;i < N;i ++)
{
if(dp[i - 1] + num[i] > num[i])
{
dp[i] = dp[i - 1] + num[i];
s[i] = s[i - 1];
}
else
{
dp[i] = num[i];
s[i] = i;
}
if(dp[i] > Max)
{
Max = dp[i];
k = i;
}
}
if(Max < 0)
cout<<0<<" "<<num[0]<<" "<<num[N - 1]<<endl;
else
cout<<Max<<" "<<num[s[k]] <<" "<<num[k] <<endl;
return 0;
}
1008
题意:电梯上升一次花费6秒,下降一次花费4秒,停留一次花费5秒。电梯一开始在0层,给出升降次数和每一次所停留的楼层,计算总共需要花费的时间。(注:最后一次停留后电梯不需要回到0层)
思路:模拟一下就可以,要注意的是就算前后两次停在同一楼层,还是需要加一遍等待时间。例如给出的样例是3 1 1 1,最后所需时间为6+5*3 = 21
#include<iostream>
#include<cstdio>
#include<cstring>
#include<string>
#include<cmath>
#include<algorithm>
using namespace std;
int main()
{
int N,f,pre = 0,ans = 0;
cin>>N;
for(int i = 0;i < N;i ++)
{
cin>>f;
if(f > pre) ans += 6 * (f - pre) + 5;
else ans += 4 *(pre - f) + 5;
pre = f;
}
cout<<ans<<endl;
return 0;
}1009
题意:给出两个多项式,求两个多项式相乘后的各项系数和指数
思路:暴力,与1002相似,注意当某项系数为0时不需要该项
#include <iostream>
#include <cstdio>
#include <cstring>
#include <string>
#include <cmath>
#include <algorithm>
#include <map>
#include <vector>
using namespace std;
const int Maxn = 1010;
map<int,double> mp;
vector<pair<int,double> > vec;
int main()
{
int k,a;
double b;
cin>>k;
while(k--)
{
cin>>a>>b;
vec.push_back(make_pair(a,b));
}
cin>>k;
while(k--)
{
cin>>a>>b;
for(int i =0;i < vec.size();i ++)
{
if(mp.find(-(a + vec[i].first)) == mp.end())
mp[-(a + vec[i].first)] = vec[i].second * b;
else
mp[-(a + vec[i].first)] += vec[i].second * b;
}
}
int sz = 0;
for(map<int,double>::iterator it = mp.begin();it != mp.end(); it ++)
{
if(fabs(it->second) < 0.01)
continue;
sz++;
}
cout<<sz;
for(map<int,double>::iterator it = mp.begin();it != mp.end(); it ++)
{
if(fabs(it->second) < 0.01)
continue;
printf(" %d %.1lf",-it->first,it->second);
}
cout<<endl;
return 0;
}
1010
题意:给出radix进制下的N1,问是否存在x进制下的N2,使得两者在同一进制下值相等。
输入:N1 N2 tag radix
tag为1时表示当前N1是radix进制的数,tag为2时,表示当前N2是radix进制的数。
6 110 1 10
表示10进制下的6,是否存在x进制下的110,使得两者相等。结果是存在的,及 1102=610
思路:此题略坑。以tag为1分析。首先想到的肯定是先求出radix进制下的N1的值,然后循环搜索,看是否存在一个进制,使得该进制下的N2 最后与N1有相同的值。这里有一个坑
zzzzzzzzz 10 1 36
那么N1 的最终值为 3610−1=3656158440062975 如果循环枚举进制,那么范围在[2,3656158440062975]之间,必然超时。。中间还可能超内存,计算太多次了。。。所以想到的就是二分枚举进制。
其次,数比较大,所以我用BigInteger。
import java.math.BigInteger;
import java.util.Scanner;
public class Main {
BigInteger getAns(String s,BigInteger radix) {
BigInteger ans = BigInteger.ZERO;
for(int i = 0;i < s.length();i ++) {
ans = ans.multiply(radix);
ans = ans.add(BigInteger.valueOf(s.charAt(i) - ((s.charAt(i)>= '0' && s.charAt(i) <='9')?'0':('a' - 10))));
}
return ans;
}
//二分查找
BigInteger binarySearch(BigInteger l,BigInteger r,String s2,BigInteger ans,Main m) {
BigInteger mid;
BigInteger res = BigInteger.valueOf(-1);
while(l.compareTo(r) <= 0) {
mid = (l.add(r)).divide(BigInteger.valueOf(2));
BigInteger value = m.getAns(s2, mid);
if(value.compareTo(ans) < 0)
l = mid.add(BigInteger.ONE);
else if(value.compareTo(ans) > 0)
r = mid.subtract(BigInteger.ONE);
else//多种进制满足时,取能取到的最小进制数
{
if(res.compareTo(BigInteger.valueOf(-1)) == 0)
res = mid;
else {
if(mid.compareTo(res) < 0)
res = mid;
}
r = mid.subtract(BigInteger.ONE);
}
}
return res;
}
public static void main(String[] args) {
Main r = new Main();
Scanner in = new Scanner(System.in);
String s1,s2;
int tag,radix;
s1 = in.next();
s2 = in.next();
tag = in.nextInt();
radix = in.nextInt();
if(tag == 2){
String tmp = s1;
s1 = s2;
s2 = tmp;
}
BigInteger ans = r.getAns(s1, BigInteger.valueOf(radix));
int from = 0;//计算最小进制数 从哪个数开始算起
for(int i = 0;i < s2.length();i ++)
{
int value = s2.charAt(i) - ((s2.charAt(i)>= '0' && s2.charAt(i) <='9')?'0':('a' - 10));
if(value > from) from= value;
}
BigInteger result = r.binarySearch(BigInteger.valueOf(from + 1) , BigInteger.valueOf(3656158440062975L), s2, ans, r);
if(result.compareTo(BigInteger.valueOf(-1)) == 0)
System.out.println("Impossible");
else
System.out.println(result);
in.close();
}
}
1011
题意:给出三组预测数据,每组预测数据有三个状态,W,T,L,选择每组数据中数值最大的数,在根据公式计算出重点内容结果
思路:暴力,套公式即可,最后保留两位小数时需要四舍五入
#include <iostream>
#include <cstdio>
#include <cstring>
#include <string>
#include <cmath>
#include <algorithm>
#include <sstream>
using namespace std;
int main()
{
double a,b,c,ans = 1;
for(int i = 0;i < 3;i ++)
{
cin>>a>>b>>c;
if(a > b && a > c)
{
ans *= a;
cout<<"W ";
}
if(b > a && b > c)
{
ans *= b;
cout<<"T ";
}
if(c > a && c > b)
{
ans *= c;
cout<<"L ";
}
}
printf("%.2lf\n",(ans * 0.65 - 1) * 2 + 0.001);
return 0;
}
1012
题意:给出N个同学的信息,包括姓名,C,M,E课程的成绩,求出平均成绩A。输出某同学的最优成绩所对应的课程(A,C,M,E)及相关的排名。课程优先级A>C>M>E
思路:排序。要注意的是相同成绩时两者的排名相同。
#include <iostream>
#include <cstdio>
#include <cstring>
#include <string>
#include <cmath>
#include <algorithm>
#include <sstream>
#include <map>
using namespace std;
const int Maxn = 2010;
struct node
{
string name;
int C,M,E,A;
int rk[4];
int flag;
node(){
for(int i = 0; i< 4;i ++)
rk[i] = 0;
}
};
char str[4] = {'A','C','M','E'};
map<string,int> mp;
node p[Maxn];
bool cmp1(node x, node y)
{
return x.A > y.A;
}
bool cmp2(node x, node y)
{
return x.C > y.C;
}
bool cmp3(node x, node y)
{
return x.M > y.M;
}
bool cmp4(node x, node y)
{
return x.E > y.E;
}
bool cmp5(node x,node y)
{
return x.flag < y.flag;
}
int main()
{
int n,m;
cin>>n>>m;
for(int i = 0;i < n;i ++)
{
cin>>p[i].name>>p[i].C>>p[i].M>>p[i].E;
p[i].A = (p[i].C + p[i].M + p[i].E) / 3;
p[i].flag = i;
mp.insert(pair<string,int>(p[i].name,i));
}
//相同分数同一排名
sort(p,p + n,cmp1);
for(int i =0;i < n;i ++)
{
if(i == 0 || p[i].A != p[i - 1].A)
p[i].rk[0] = i + 1;
else
p[i].rk[0] = p[i - 1].rk[0];
}
sort(p,p + n,cmp2);
for(int i =0;i < n;i ++)
{
if(i == 0 || p[i].C != p[i - 1].C)
p[i].rk[1] = i + 1;
else
p[i].rk[1] = p[i - 1].rk[1];
}
sort(p,p + n,cmp3);
for(int i =0;i < n;i ++)
{
if(i == 0 || p[i].M != p[i - 1].M)
p[i].rk[2] = i + 1;
else
p[i].rk[2] = p[i - 1].rk[2];
}
sort(p,p + n,cmp4);
for(int i =0;i < n;i ++)
{
if(i == 0 || p[i].E != p[i - 1].E)
p[i].rk[3] = i + 1;
else
p[i].rk[3] = p[i - 1].rk[3];
}
sort(p,p + n,cmp5);
string name;
while(m --)
{
cin>>name;
if(mp.find(name) == mp.end())
cout<<"N/A"<<endl;
else
{
int f = mp[name];
int k = 0;
int Min = p[f].rk[0];
for(int i = 1;i < 4;i ++)
{
if(p[f].rk[i] < Min)
{
Min = p[f].rk[i];
k = i;
}
}
cout<<Min<<" "<<str[k]<<endl;
}
}
return 0;
}
1013
题意:N个点,m条边,k个询问。每次询问时给出一个数a,当a这个点被占领时(即去掉a这个点以及与之相关的边),问至少增加多少条边才能使剩下的点能连接起来(即两两到达)
思路:dfs。因为点的个数不多,每次询问时dfs一下,看能把所有的点分成几组,若分成x组,最后需要x-1条边将各组连接起来。
#include <iostream>
#include <cstdio>
#include <cstring>
#include <string>
#include <cmath>
#include <algorithm>
#include <vector>
using namespace std;
const int Maxn = 1010;
bool flag[Maxn];
vector<int> vec[Maxn];
void dfs(int n)
{
if(vec[n].size() <= 0) return;
for(int i = 0;i < vec[n].size();i ++)
{
if(flag[vec[n][i]] == false)
{
flag[vec[n][i]] = true;
dfs(vec[n][i]);
}
}
}
int main()
{
int n,m,k,a,b;
cin>>n>>m>>k;
for(int i = 1;i <= n;i ++)
flag[i] = false;
for(int i = 0;i < m;i ++)
{
cin>>a>>b;
vec[a].push_back(b);
vec[b].push_back(a);
}
for(int i = 0;i < k;i ++)
{
cin>>a;
flag[a] = true;
int cnt = 0;
for(int j = 1;j <= n;j ++)
{
if(flag[j] == false)
{
flag[j] = true;
cnt ++;
dfs(j);
}
}
cout<<cnt - 1<<endl;
for(int j = 1;j <= n;j ++)
flag[j] = false;
}
return 0;
}
1014
题意:
思路:
1015
题意:给出一个数N,以及基数D,要求N在D进制下反转得到的数M,判断N,M是否为素数,如果是素数,则输出Yes,否则输出No
思路:将N转化为D进制数x,将x反转,在转化为十进制数M,再进行判断素数。
eg:23 2
2310=101112
反转得到 111012=2910
再判断23,29是否为素数
#include <iostream>
#include <cstdio>
#include <cstring>
#include <string>
#include <cmath>
#include <algorithm>
#include <vector>
using namespace std;
bool isPrime(int n)
{
if(n <= 1) return false;
for(int i = 2;i <= floor(sqrt(n));i ++)
{
if(n % i == 0) return false;
}
return true;
}
int main()
{
int n,radix;
int ans1 = 0, ans2 = 0;
while(cin>>n)
{
if(n < 0) break;
cin>>radix;
ans1 = n;
ans2 = 0;
while(n)
{
ans2 = ans2 * radix + (n % radix);
n /= radix;
}
if(isPrime(ans1) && isPrime(ans2))
cout<<"Yes"<<endl;
else
cout<<"No"<<endl;
}
return 0;
}
1016
题意:给出一天24小时,以一小时为一个时间段,共24个时间段中每个时间段每分钟打电话所需的费用。N条数据,每条数据表示一个人某次打电话的记录。错误记录可忽略不计,例如只有on-line没有off-line或者只有off-line没有on-line。要求计算每个人打电话的时间段和所需的费用,以及最后的费用总和。
思路:模拟。
#include <iostream>
#include <cstdio>
#include <cstring>
#include <string>
#include <cmath>
#include <algorithm>
#include <vector>
#include <map>
using namespace std;
const int Maxn = 1010;
struct person
{
string name;//姓名
string time;//通话时间段
string state;//通话状态
int day,hour,minute;//从time中提取dd,HH,mm
bool operator<(const person &x) const
{
if(name != x.name)
return name < x.name;
return time < x.time;
}
};
double cost[25];
person p[Maxn];
map<string,bool> mp;
int main()
{
int n;
double sum[24];
for(int i = 0;i < 24;i ++)
{
cin>>cost[i];
sum[i] = ((i == 0)?cost[i]:(sum[i - 1] + cost[i]));
}
cin>>n;
for(int i = 0;i < n;i ++)
{
cin>>p[i].name>>p[i].time>>p[i].state;
p[i].day = (p[i].time[3] - '0') * 10 + p[i].time[4] - '0';
p[i].hour = (p[i].time[6] - '0') * 10 + p[i].time[7] - '0';
p[i].minute = (p[i].time[9] - '0') * 10 + p[i].time[10] - '0';
}
sort(p,p + n);
double total = 0;
int cnt = 0;
for(int i = 1;i < n; i ++)
{
if(p[i].name == p[i - 1].name && p[i].state == "off-line" && p[i - 1].state == "on-line")
{
if(mp.find(p[i].name) == mp.end())
{
if(mp.size() > 0)
printf("Total amount: $%.2lf\n",total / 100),total = 0,cnt ++;
mp.insert(pair<string,bool>(p[i].name,true));
cout<<p[i].name<<" "<<p[i].time.substr(0,2)<<endl;
}
cout<<p[i - 1].time.substr(3)<<" "<<p[i].time.substr(3)<<" "<<(p[i].day * 24 * 60 + p[i].hour * 60 + p[i].minute) - (p[i - 1].day * 24 * 60 + p[i - 1].hour * 60 + p[i - 1].minute)<<" ";
double money = 0;
if(p[i].day != p[i - 1].day)//dd 有跨度
{
money += (p[i].day - p[i - 1].day - 1) * sum[23] * 60;
money += sum[23] * 60 - ((p[i - 1].hour == 0)?0:(sum[p[i - 1].hour - 1])) * 60 - p[i - 1].minute * cost[p[i - 1].hour];
money += ((p[i].hour == 0)?0:(sum[p[i].hour - 1] * 60)) + p[i].minute * cost[p[i].hour];
}
else//dd属于同一天的
{
money += ((p[i].hour == 0)?0:(sum[p[i].hour - 1] * 60)) + p[i].minute * cost[p[i].hour];
money -= (((p[i - 1].hour == 0)?0:(sum[p[i - 1].hour - 1])) * 60 + p[i - 1].minute * cost[p[i - 1].hour]);
}
printf("$%.2lf\n",money / 100);
total += money;
}
}
if(cnt < mp.size())
printf("Total amount: $%.2lf\n",total / 100);
return 0;
}
1017
题意:银行有K个窗口,可同时供K个人办理业务,银行营业时间为08:00:00-17:00:00,在08:00:00前到需要等到8点,在17:00:00后到的不办理业务了。按顺序哪个窗口有空了等待的人就去哪个窗口。现在给出每个人的到达时间和办理业务时间,问平均每个人的等待时间,精确到小数点后1位。(不办理业务的人不用算到平均等待时间中去。)
思路:模拟
#include <iostream>
#include <cstdio>
#include <cstring>
#include <string>
#include <cmath>
#include <algorithm>
#include <vector>
#include <queue>
using namespace std;
const int Maxn = 10010;
struct person
{
string arriveTime;//到达时间
int process;//业务处理时间
double seconds;//为了方便处理,将时间转化为秒数,省的每次去计算一遍
bool operator < (const person &x) const
{
return arriveTime < x.arriveTime;
}
};
//保存正在办理业务的人的结束时间,按从小到达排
priority_queue<double, vector<double>,greater<double> > que;
person p[Maxn];
int getSeconds(string s)
{
return ((s[0] - '0') * 10 + s[1] - '0') * 60 * 60 + ((s[3] - '0') * 10 +s[4] - '0') * 60 + (s[6] - '0') * 10 + s[7] - '0';
}
int main()
{
int N,K;
cin>>N>>K;
for(int i = 0;i < N;i ++)
{
cin>>p[i].arriveTime>>p[i].process;
p[i].seconds = getSeconds(p[i].arriveTime);
}
sort(p,p + N);
double waitTime = 0;
int cnt = 0;
int startTime = getSeconds("08:00:00");
for(int i = 0;i < min(K,N);i ++)
{
cnt ++;
if(p[i].seconds <= startTime)//在08:00:00前到的需要等待一段时间
{
waitTime += startTime - p[i].seconds;
que.push(startTime + p[i].process * 60);
}
else
que.push(p[i].seconds + p[i].process * 60);
}
for(int i = K;i < N;i ++)
{
if(p[i].arriveTime > "17:00:00")
break;
cnt ++;
if(p[i].seconds <= que.top())
{
waitTime += que.top() - p[i].seconds;
double endTime = que.top() + p[i].process * 60;
que.pop();
que.push(endTime);
}
else
{
que.pop();
que.push(p[i].seconds + p[i].process * 60);
}
}
printf("%.1lf\n",waitTime / 60 / cnt );
return 0;
}
1018
题意:背景为杭州公共自行车租借点,已知每个节点停车数为Cmax/2时效果最佳,因此需要调整节点中的自行车数,使得起点到终点的每个节点(起点0除外)都要满足自行车数为Cmax/2。现要找到一条起点0到终点S的最短路径,同时,计算从起点要拿出多少辆自行车才能调整这条路径中各节点的自行车数,并计算返回起点时可以带回多少辆多余的自行车数,同时,还需计算出路径所经过的各个节点。(ps:当起点带出去的自行车数相等时,需要返回起点时带回来的自行车数更少的路径)
思路:最短路,dijkstra即可,中间再处理题目中的要求。此题有个坑,感觉题目说的不清楚,路径中节点的自行车数的调整只能在起点到终点的路途中调整,不能利用终点回起点时多余的自行车数来调整,被这点坑了一下午。。。
#include <iostream>
#include <cstdio>
#include <cstring>
#include <string>
#include <cmath>
#include <algorithm>
#include <vector>
using namespace std;
const int Maxn = 550;
const int Inf = 0x7fffffff;
struct pbmc
{
int dis;//记录0到该点的最短路径
int bikeNum;//该站点的自行车数
vector<vector<int> > vec; //我把所有满足条件的路径都记下来了。。
};
int dis[Maxn][Maxn];
pbmc p[Maxn];
bool flag[Maxn];
int Cmax,N,S,M;
void dijkstra(int s,int e)//一开始理解错题意了,在去的路径中要同时调整中间站点的自行车数,不能回来的时候用多余的自行车来调整
{
for(int i = 0;i <= N;i ++)
{
int Min = Inf;
int k = 0;
for(int j = 0;j <= N;j ++)
{
if(p[j].dis < Min && flag[j] == false)
{
Min = p[j].dis;
k = j;
}
}
flag[k] = true;
for(int j = 0;j <= N;j ++)
{
if(j == k) continue;
if(dis[k][j] != Inf && dis[k][j] + p[k].dis < p[j].dis)//碰到更短的路径时,更新到该点的路径
{
p[j].dis = p[k].dis + dis[k][j];
p[j].vec.clear();
p[j].vec = p[k].vec;
for(int z = 0;z < p[j].vec.size();z ++)
p[j].vec[z].push_back(j);
}
else if(dis[k][j] != Inf && dis[k][j] + p[k].dis == p[j].dis)//当路径相同时,添加不同的路径到该点的路径中
{
for(int z = 0;z < p[k].vec.size();z ++)
{
vector<int> tmpvec = p[k].vec[z];
tmpvec.push_back(j);
p[j].vec.push_back(tmpvec);
}
}
}
}
int Min = Inf,backMin = Inf;
int k = 0;
for(int i = 0;i < p[e].vec.size();i ++)
{
int send = 0;//去的途中要增加的自行车数
int cost = 0,add = 0;//add:调整完后多余的自行车数
for(int j = 1;j < p[e].vec[i].size();j ++)
{
cost = add + p[p[e].vec[i][j]].bikeNum;
if(cost >= Cmax)
add = cost - Cmax;
else
{
send += Cmax - cost;
add = 0;
}
}
if(send < Min)
{
Min = send;
backMin = add;
k = i;
}
else if(send == Min)
{
if(add < backMin)
{
backMin = add;
k = i;
}
}
}
cout<<Min<<" ";
for(int i = 0;i < p[e].vec[k].size();i ++)
cout<<((i == 0)?"":"->")<<p[e].vec[k][i];
cout<<" "<<backMin<<endl;
}
int main()
{
int a,b,d;
cin>>Cmax>>N>>S>>M;
Cmax = Cmax / 2;
for(int i = 1;i <= N;i ++)
{
cin>>p[i].bikeNum;
p[i].dis = Inf;
}
p[0].bikeNum = 0;
p[0].dis = 0;
vector<int> v(1);
p[0].vec.push_back(v);
for(int i = 0;i <= N;i ++)
for(int j = 0;j <= N;j ++)
{
if(i == j) dis[i][j] = 0;
else dis[i][j] = dis[j][i] = Inf;
}
for(int i = 0;i < M;i ++)
{
cin>>a>>b>>d;
dis[a][b] = dis[b][a] = d;
}
dijkstra(0,S);
return 0;
}
1019
题意:给出N,base,将N转化为base进制的数,判断该数是否为回文数。
思路:暴力。
#include <iostream>
#include <cstdio>
#include <cstring>
#include <string>
#include <cmath>
#include <algorithm>
using namespace std;
const int Maxn = 110;
int num[Maxn];
int main()
{
int n,base,cnt = 0;
bool flag = true;
cin>>n>>base;
if(n == 0)
num[cnt++] = 0;
while(n)
{
num[cnt++] = n % base;
n /= base;
}
for(int i = 0;i <= (cnt - 1) / 2; i++)
{
if(num[i] != num[cnt - 1 - i])
{
flag = false;
break;
}
}
if(flag)
cout<<"Yes"<<endl;
else
cout<<"No"<<endl;
for(int i = cnt - 1;i >= 0;i --)
cout<<((i == cnt - 1)?"":" ")<<num[i];
cout<<endl;
return 0;
}
/* 10 6 5 7 5 5 5 11 0 5 0 1 1 1 2 1 2 3 1 0 4 1 4 6 1 6 3 1 3 5 1 结果:0 0->4->6->3->5 1 10 3 3 3 5 3 8 0 1 1 1 2 1 2 3 1 结果:2 0->1->2->3 3 */1020
题意:已知一棵二叉树的后续和中序,构造二叉树,并按每一层的节点顺序打印节点。
思路:根据后续和中序的特点,后续排列从右往左计算,每一次是一个节点,根据该节点划分树的左侧和右侧,构造二叉树。我一开始想的就是把二叉树构造出来然后打印,但也有更方便的方法,直接用数组进行存数数据。不一定要把树建出来。
#include <iostream>
#include <cstdio>
#include <cstring>
#include <string>
#include <cmath>
#include <algorithm>
#include <map>
#include <queue>
using namespace std;
const int Maxn = 50;
struct node
{
int val;
node *left;
node *right;
node(int x):val(x),left(NULL),right(NULL){}
};
int postOrder[Maxn],inOrder[Maxn];
map<int,int> mp;
queue<node*> que;
//构造二叉树
node* buildTree(node *root,int l,int r,int &cnt)
{
if(l > r) return NULL;
root = new node(postOrder[cnt]);
int tmp = postOrder[cnt];
cnt--;
root->right = buildTree(root->right,mp[tmp]+ 1,r,cnt);
root->left = buildTree(root->left,l,mp[tmp] - 1,cnt);
return root;
}
int main()
{
int n;
cin>>n;
for(int i = 0;i < n;i ++)
cin>>postOrder[i];
for(int i = 0;i < n;i ++)
{
cin>>inOrder[i];
mp.insert(pair<int,int>(inOrder[i],i));
}
node *root = NULL;
int cnt = n - 1;
root = buildTree(root,0,n - 1,cnt);
//打印
if(root != NULL)
{
que.push(root);
while(!que.empty())
{
node *p = que.front();
que.pop();
cout<<((p == root)?"":" ")<<p->val;
if(p->left != NULL)
que.push(p->left);
if(p->right != NULL)
que.push(p->right);
}
cout<<endl;
}
return 0;
}
1021
题意:给出N个点,N-1条边,如果它不能构成一棵树,求出此图被分成几个部分。如果构成一棵树,则按字典顺序输出节点,这些节点满足条件是:当以该点为root时,树的深度最深
思路:我首先用并查集判断它是不是一棵树,不是一棵树,求出由几部分组成。然后再算出数的直径,求出能构成树的直径长度的那些节点即可。这题还被坑了一会,原因在代码注释中了。
#include<iostream>
#include<cstdio>
#include<algorithm>
#include<cmath>
#include<cstring>
#include<string>
#include<set>
using namespace std;
set<int> se;
set<int>::iterator it;
const int Maxn = 10010;
int root[Maxn];
struct node
{
int to;//指向的点
int next;//从同一个head出发的上一条也有的边
};
node edge[Maxn * 2];
int etot,head[Maxn],flag[Maxn],len[Maxn];
//树的直径部分
void addAge(int u,int v)
{
edge[etot].to = v;
edge[etot].next = head[u];
head[u] = etot++;
}
void dfs(int x,int cnt)
{
flag[x] = true;
len[x] = cnt;
for(int i = head[x];i != -1;i = edge[i].next)
{
if(flag[edge[i].to] == false)
{
dfs(edge[i].to,cnt + 1);
flag[edge[i].to] = false;
}
}
}
void getTreeLength(int N)
{
dfs(1,1);
int Max = 0,k = 0;
for(int i = 1;i <= N;i ++)
if(len[i] > Max)
{
Max = len[i];
k = i;
}
/*保存在set中是因为在第一遍找树的直径的某个终点时,可能有多个终点属于同一子树下,那么在计算树的直径时这些点的等级是一样的 7 1 2 1 3 2 4 2 5 3 6 3 6 如果第一遍dfs选择的节点是4,那么以4为端点寻找另一个端点时,5不会被遍历到,因为5和4的等级是相同的,并且在同一子树下。 */
for(int i = 1;i <= N;i ++)
if(len[i] == Max)
se.insert(i);
flag[1] = false;
dfs(k,1);
Max = 0;
for(int i = 1;i <= N;i ++)
Max = max(Max,len[i]);
for(int i = 1;i <= N;i ++)
if(len[i] == Max)
se.insert(i);
for(it = se.begin();it != se.end();it++)
cout<<*it<<endl;
}
//并查集部分
int Find(int x)
{
if(x == root[x])
return x;
return root[x] = Find(root[x]);
}
void Union(int a,int b)
{
int ra = Find(a);
int rb = Find(b);
if(ra != rb)
root[ra] = rb;
}
int main()
{
int N,a,b;
cin>>N;
for(int i = 1;i <= N;i ++)
root[i] = i,head[i] = -1;
for(int i = 1;i < N;i ++)
{
cin>>a>>b;
Union(a,b);
addAge(a,b);
addAge(b,a);
}
int cnt = 0;
for(int i = 1;i <= N;i ++)
{
Find(i);
if(i == root[i]) cnt++;
}
if(cnt > 1)
{
cout<<"Error: "<<cnt<<" components"<<endl;
}
else
{
getTreeLength(N);
}
return 0;
}
1022
题意:一本书有它的ID号,书名,作者,关键字,出版社,出版日期。先给定N本书的属性,M次询问,每次询问根据书名/作者/…来提问,给出相关的书的ID号,并按字典顺序输出,如果没有,就输出Not Found
思路:模拟题。因为题意中说明了书的关键字、作者等不会超过1000,所以直接暴力上了
#include <iostream>
#include <cstdio>
#include <cstring>
#include <string>
#include <cmath>
#include <algorithm>
#include <map>
#include <vector>
using namespace std;
map<string,vector<string> > title,author,key,publisher,year;
map<string,vector<string> >::iterator it;
int main()
{
int N,M;
cin>>N;
string id,t,a,k,p,y,f;
getchar();
while(N --)
{
getline(cin,id);
getline(cin,t);
getline(cin,a);
getline(cin,k);
getline(cin,p);
getline(cin,y);
//书名
if(title.find(t) == title.end())
title.insert(pair<string,vector<string> >(t,vector<string>(1,id)));
else
title[t].push_back(id);
//作者
if(author.find(a) == author.end())
author.insert(pair<string,vector<string> >(a,vector<string>(1,id)));
else
author[a].push_back(id);
//关键字
int f = 0;
while(f >= 0)
{
f = k.find(" ");
string str = k.substr(0,f);
if(key.find(str) == key.end())
key.insert(pair<string,vector<string> >(str,vector<string>(1,id)));
else
key[str].push_back(id);
k = k.substr(f + 1);
}
//出版社
if(publisher.find(p) == publisher.end())
publisher.insert(pair<string,vector<string> >(p,vector<string>(1,id)));
else
publisher[p].push_back(id);
//出版年份
if(year.find(y) == year.end())
year.insert(pair<string,vector<string> >(y,vector<string>(1,id)));
else
year[y].push_back(id);
}
cin>>M;
getchar();
vector<string> ans;
while(M--)
{
getline(cin,f);
cout<<f<<endl;
if(f[0] == '1')
{
if(title.find(f.substr(3)) == title.end())
cout<<"Not Found"<<endl;
else
{
ans = title[f.substr(3)];
sort(ans.begin(),ans.end());
for(int i = 0;i < ans.size();i ++)
cout<<ans[i]<<endl;
}
}
if(f[0] == '2')
{
if(author.find(f.substr(3)) == author.end())
cout<<"Not Found"<<endl;
else
{
ans = author[f.substr(3)];
sort(ans.begin(),ans.end());
for(int i = 0;i < ans.size();i ++)
cout<<ans[i]<<endl;
}
}
if(f[0] == '3')
{
if(key.find(f.substr(3)) == key.end())
cout<<"Not Found"<<endl;
else
{
ans = key[f.substr(3)];
sort(ans.begin(),ans.end());
for(int i = 0;i < ans.size();i ++)
cout<<ans[i]<<endl;
}
}
if(f[0] == '4')
{
if(publisher.find(f.substr(3)) == publisher.end())
cout<<"Not Found"<<endl;
else
{
ans = publisher[f.substr(3)];
sort(ans.begin(),ans.end());
for(int i = 0;i < ans.size();i ++)
cout<<ans[i]<<endl;
}
}
if(f[0] == '5')
{
if(year.find(f.substr(3)) == year.end())
cout<<"Not Found"<<endl;
else
{
ans = year[f.substr(3)];
sort(ans.begin(),ans.end());
for(int i = 0;i < ans.size();i ++)
cout<<ans[i]<<endl;
}
}
}
return 0;
}
1023
题意:给出一个数N(不超过20位),将其乘2,判断所得的数是否为原先的数中每个数的另一中排列。例如123456789, 乘2后得2469135798,每个数字出现的次数与123456789相同,只是位置不同。
思路:字符串模拟一下就好了,每个数出现的次数用hash表保存下来,在判断的时候用。
#include <iostream>
#include <cstdio>
#include <cstring>
#include <string>
#include <cmath>
#include <algorithm>
#include <sstream>
using namespace std;
const int Maxn = 30;
int hashNum[Maxn];
int num[Maxn];
string str;
void getStr()
{
int len = str.length();
for(int i = len - 1;i >= 0;i --)
num[len - i - 1] = (str[i] - '0') * 2;
for(int i = 0;i < len;i ++)
{
num[i + 1] += num[i] / 10;
num[i] = num[i] % 10;
}
while(num[len])
{
num[len + 1] += num[len] / 10;
num[len] = num[len] % 10;
len ++;
}
str.clear();
for(int i = len - 1;i >= 0;i --)
{
ostringstream ss;
ss<<num[i];
str = str + ss.str();
}
}
int main()
{
cin>>str;
int len = str.length();
for(int i = 0;i < len;i ++)
hashNum[str[i] - '0'] ++;
getStr();
if(str.length() > len)
{
cout<<"No"<<endl;
cout<<str<<endl;
}
else
{
int i;
for(i = 0;i < str.length();i ++)
{
if(hashNum[str[i] - '0'] > 0)
hashNum[str[i] - '0'] --;
else
break;
}
if(i == str.length())
cout<<"Yes"<<endl;
else
cout<<"No"<<endl;
cout<<str<<endl;
}
return 0;
}
1024
题意:给定一个数N ( N≤1010 ),看其是否为回文数,如果不是回文数,就将数反转后与原数相加,再进行回文数判断,以此类推,直到数是回文数为止或者反转次数达到上限M( M≤100 )
思路:数的范围有点大,若进行100次反转相加后可能达到 10100 , 我没有用java,所以用字符串去模拟。
#include <iostream>
#include <cstdio>
#include <cstring>
#include <string>
#include <cmath>
#include <algorithm>
#include <sstream>
using namespace std;
const int Maxn = 150;
string str;
int len,k;
int cal[Maxn];
//判断是否为回文串
bool checkPalindromic()
{
for(int i = len - 1;i >= (len - 1) / 2;i --)
if(str[i] != str[len - i - 1])
return false;
return true;
}
//处理数据,反转后与原数相加。感觉写的不太好,不那么简洁
void getStr()
{
string tmp = str;
reverse(tmp.begin(),tmp.end());
for(int i = len - 1;i >= 0;i --)
cal[len - i - 1] = str[i] - '0' + (tmp[i] - '0');
for(int i = 0;i < len;i ++)
{
cal[i + 1] += cal[i] / 10;
cal[i] = cal[i] % 10;
}
while(cal[len])
{
cal[len + 1] += cal[len] / 10;
cal[len] %= 10;
len ++;
}
str.clear();
for(int i = len - 1;i >= 0;i --)
{
ostringstream ss;
ss<<cal[i];
str = str + ss.str();
}
}
int main()
{
cin>>str>>k;
len = str.length();
for(int i = 1;i <= k;i ++)
{
if(checkPalindromic())
{
cout<<str<<endl;
cout<<i - 1<<endl;
break;
}
else
{
getStr();
if(i == k)
{
cout<<str<<endl;
cout<<k<<endl;
}
}
}
return 0;
}
1025
题意:N组数据,每组数据有K个人,每个人有个id和成绩,现要对所有人的成绩进行排序,要求该人所在的组,在该组中的成绩排名,以及在所有人中的成绩排名。相同成绩时属于同一名次。注意最后的输出如果成绩相同,按id号从小到大排
思路:排序,写个cmp比较函数即可。
#include <iostream>
#include <cstdio>
#include <cstring>
#include <string>
#include <cmath>
#include <algorithm>
using namespace std;
const int Maxn = 30010;
struct person
{
string id;
int location_number;
int local_rank;
int final_rank;
int score;
};
bool cmp(person x,person y)
{
if(x.score != y.score)
return x.score > y.score;
return x.id < y.id;
}
person p[Maxn];
int main()
{
int N,K,cnt = 0;
cin>>N;
for(int cas = 1;cas <= N;cas ++)
{
cin>>K;
int tmp = K;
while(tmp--)
{
cin>>p[cnt].id>>p[cnt].score;
p[cnt++].location_number = cas;
}
sort(p + cnt - K,p + cnt,cmp);
for(int i = cnt - K;i < cnt;i ++)
{
if(i == cnt - K || p[i].score != p[i - 1].score)
p[i].local_rank = i - (cnt - K)+ 1;
else
p[i].local_rank = p[i - 1].local_rank;
}
}
sort(p,p + cnt,cmp);
cout<<cnt<<endl;
for(int i = 0;i < cnt;i ++)
{
if(i == 0 || p[i].score != p[i - 1].score)
p[i].final_rank = i + 1;
else
p[i].final_rank = p[i - 1].final_rank;
cout<<p[i].id<<" "<<p[i].final_rank<<" "<<p[i].location_number<<" "<<p[i].local_rank<<endl;
}
return 0;
}
1026
题意:
思路:
1027
题意:将3个十进制数转化为13进制数,并按格式输出
思路:水题
#include <iostream>
#include <cstdio>
#include <cstring>
#include <string>
#include <cmath>
#include <algorithm>
using namespace std;
char getCharacter(int a)
{
if(a < 10)
return a + '0';
return a - 10 + 'A';
}
int main()
{
int a,b,c;
cin>>a>>b>>c;
cout<<"#"<<getCharacter(a/13)<<getCharacter(a%13)<<getCharacter(b/13)<<getCharacter(b%13)<<getCharacter(c/13)<<getCharacter(c%13)<<endl;
return 0;
}
1028
题意:给出N个学生的信息,id,name ,score,按要求进行排序,当C==1时,按id从小到大排,当C==2时,按name从小到大排,当C == 3时,按score从小到大排,如果name或score相等时,按id号从小到大排
思路:简单的排序。但是这里给的时限只有200ms,如果用c++的cin什么的容易超时,所以我改成了C风格,scanf和printf来进行读入和输出。
#include <iostream>
#include <cstdio>
#include <cstring>
#include <string>
#include <cmath>
#include <algorithm>
using namespace std;
const int Maxn = 100010;
struct person
{
char id[10];
char name[10];
int score;
bool operator < (const person& x) const
{
return strcmp(id,x.id) < 0;
}
};
bool cmpName(person x,person y)
{
return strcmp(x.name,y.name) < 0;
}
bool cmpScore(person x,person y)
{
return x.score < y.score;
}
person p[Maxn];
int main()
{
int N,C;
scanf("%d%d",&N,&C);
for(int i = 0;i < N;i ++)
scanf("%s%s%d",&p[i].id,&p[i].name,&p[i].score);
sort(p,p + N);
if(C == 2)
sort(p,p + N,cmpName);
if(C == 3)
sort(p,p + N,cmpScore);
for(int i = 0;i < N;i ++)
printf("%s %s %d\n",p[i].id,p[i].name,p[i].score);
return 0;
}
1029
题意:给出两组递增数组,要求将两组数据合并后的中位数
思路:数的范围比较大,而且是排好序的,直接O(n)的方法去模拟即可,因为给了400ms实现,所以输入输出用scanf和printf
#include <iostream>
#include <cstdio>
#include <cstring>
#include <string>
#include <cmath>
#include <algorithm>
using namespace std;
typedef long long LL;
const int Maxn = 1000010;
LL a[Maxn],b[Maxn];
int main()
{
int N,k;
scanf("%d",&N);
k = N;
for(int i = 0;i < N;i ++)
scanf("%lld",&a[i]);
scanf("%d",&N);
for(int i = 0;i < N;i ++)
scanf("%lld",&b[i]);
int mid = (k + N - 1)/ 2,cnt = 0;
int i,j;
for(i = 0,j = 0;i < k && j < N;)
{
if(a[i] < b[j])
{
if(cnt == mid)
{
printf("%lld\n",a[i]);
break;
}
i ++;
}
else
{
if(cnt == mid)
{
printf("%lld\n",b[j]);
break;
}
j ++;
}
cnt ++;
}
if(i >= k || j >= N)
{
if(i >= k)
{
for(;j < N;j ++)
{
if(cnt == mid)
{
printf("%lld\n",b[j]);
break;
}
cnt++;
}
}
else
{
for(;i < k;i ++)
{
if(cnt == mid)
{
printf("%lld\n",a[i]);
break;
}
cnt++;
}
}
}
return 0;
}
1030
题意:N个点(N<=500),M条边,起点S,终点D,已知每条边有长度和花费,要求从S到D最短路的长度,如果有多条,输出花费最小的。
思路:跟1018,1087差不多,dijkstra即可。
#include <iostream>
#include <cstdio>
#include <cstring>
#include <string>
#include <cmath>
#include <algorithm>
#include <vector>
using namespace std;
const int Maxn = 550;
const int Inf = 0x7fffffff;
struct node
{
int dis;
vector<vector<int> > vec;//把所有可能的路径存起来
};
node road[Maxn];
int dis[Maxn][Maxn];
int cost[Maxn][Maxn];
bool flag[Maxn];
int N,M,S,D;
void dijkstra()
{
for(int i = 0;i < N;i ++)
{
int Min = Inf;
int k;
for(int j = 0;j < N;j ++)
{
if(flag[j] == false && road[j].dis < Min)
{
Min = road[j].dis;
k = j;
}
}
flag[k] = true;
for(int j = 0;j < N;j ++)
{
if(j == k) continue;
if(dis[k][j] != Inf && dis[k][j] + road[k].dis < road[j].dis)
{
road[j].dis = road[k].dis + dis[k][j];
road[j].vec.clear();
road[j].vec = road[k].vec;
for(int z = 0;z < road[j].vec.size();z++)
road[j].vec[z].push_back(j);
}
else if(dis[k][j] != Inf && dis[k][j] + road[k].dis == road[j].dis)
{
for(int z = 0;z < road[k].vec.size();z++)
{
vector<int> tmpvec = road[k].vec[z];
tmpvec.push_back(j);
road[j].vec.push_back(tmpvec);
}
}
}
}
//计算最小花费
int Min = Inf;
int k = 0;
for(int i = 0;i < road[D].vec.size();i ++)
{
int d = 0;
for(int j = 1;j < road[D].vec[i].size();j ++)
d += cost[road[D].vec[i][j]][road[D].vec[i][j - 1]];
if(d < Min)
{
Min = d;
k = i;
}
}
for(int i = 0;i < road[D].vec[k].size();i ++)
cout<<road[D].vec[k][i]<<" ";
cout<<road[D].dis<<" "<<Min<<endl;
}
int main()
{
int a,b,d,c;
cin>>N>>M>>S>>D;
for(int i = 0;i < N;i ++)
road[i].dis = Inf;
for(int i = 0;i < N;i ++)
for(int j = 0;j < N;j ++)
{
if(i == j) dis[i][j] = 0;
else dis[i][j] = Inf;
}
for(int i = 0;i < M;i ++)
{
cin>>a>>b>>d>>c;
dis[a][b] = dis[b][a] = d;
cost[a][b] = cost[b][a] = c;
}
road[S].dis = 0;
road[S].vec.push_back(vector<int>(1,S));
dijkstra();
return 0;
}
1031
题意:给出一个长度为N的字符串str,要求将其按“U”字形进行输出。U字形左侧和右侧分别有n1,n3个字符,底部有n2个字符,那么n1 + n2 + n3 - 2 = N,其中n1 = n3 = max { k| k <= n2 for all 3 <= n2 <= N }
思路:条件就是使得在n1<=n2的情况下n1取最大能取到的值。2*n1 + n3 = N - 2,2 * n1 + n3 >= 3 * n1,所以n1 <= (N - 2) / 3
#include <iostream>
#include <cstdio>
#include <cstring>
#include <string>
#include <cmath>
#include <algorithm>
using namespace std;
int main()
{
string str;
cin>>str;
int len = str.length();
int x = (len + 2) / 3;
int y = len + 2 - 2 * x;
for(int i = 0;i < x - 1;i ++)
{
cout<<str[i];
for(int j = 0;j < y - 2;j ++)
cout<<" ";
cout<<str[len - i - 1]<<endl;
}
for(int i = x - 1;i < x - 1 + y;i ++)
cout<<str[i];
cout<<endl;
return 0;
}
1032
题意:给定两个字符串,判断两个字串从哪个位置开始拥有相同的后缀,输出开始的那个字符串的位置
思路:水题
#include <iostream>
#include <cstdio>
#include <cstring>
#include <string>
#include <cmath>
#include <algorithm>
#include <map>
#include <vector>
using namespace std;
const int Maxn = 100010;
int Hash[Maxn];
bool flag[Maxn];
int main()
{
int s1,s2,N,f,e;
char s;
int ans = -1;
scanf("%d%d%d",&s1,&s2,&N);
while(N --)
{
scanf("%d %c %d",&f,&s,&e);
Hash[f] = e;
}
while(s1 != -1)
{
flag[s1] = true;
s1 = Hash[s1];
}
while(s2 != -1)
{
if(flag[s2] == true)
{
ans = s2;
break;
}
s2 = Hash[s2];
}
if(ans == -1)
printf("%d\n",ans);
else
printf("%05d\n",ans);
return 0;
}
1033
题意:
思路:
1034
题意:给出一幅图,供N条边,每条边有个权值,连接这条边的两个点都可加上相应的权值,现要求给出的点共构成几个子图。若子图中点的个数>2 且边的权值之和>threshold,则输出子图中权值最大的点以及该子图的点的个数。要求按点的名字的字典序进行输出
思路:由于点是字符串,可先离散化,将字符串与值想对应。并查集看功能分出多少个子图,再计算最终的结果。ps 我觉得我写的下面的代码有点浪费空间的,orz
#include <iostream>
#include <cstdio>
#include <cstring>
#include <string>
#include <cmath>
#include <algorithm>
#include <map>
using namespace std;
const int Maxn = 2010;
/*tm:保存每个点的通话时间 cnt:并查集后计算每个子集的点的个数 sum:并查集后计算每个子集的总通话时间 heads:保存每个子集中的通话时间最长的点 */
int tm[Maxn],root[Maxn],cnt[Maxn],sum[Maxn],heads[Maxn];
string Hash[Maxn];//点的string与int的映射关系
map<string,int> mp;
struct node
{
int totalNum;
string heads;
bool operator < (const node& x) const
{
return heads < x.heads;
}
};
node res[Maxn];
int Find(int x)
{
if(root[x] == x)
return x;
return root[x] = Find(root[x]);
}
void Union(int x,int y)
{
int ra = Find(x);
int rb = Find(y);
if(ra != rb)
root[ra] = rb;
}
int main()
{
int N,threshold,t,num = 1;
string name1,name2;
cin>>N>>threshold;
for(int i = 1;i <= 2 * N;i ++)
root[i] = heads[i] = i;
for(int i = 1;i <= N;i ++)
{
cin>>name1>>name2>>t;
if(mp.find(name1) == mp.end())
mp[name1] = num,Hash[num++] = name1;
if(mp.find(name2) == mp.end())
mp[name2] = num,Hash[num++] = name2;
tm[mp[name1]] += t;
tm[mp[name2]] += t;
Union(mp[name1],mp[name2]);
}
N = mp.size();
for(int i = 1;i <= N;i ++)
{
Find(i);
cnt[root[i]] ++;
sum[root[i]] += tm[i];
if(tm[i] > tm[heads[root[i]]])
heads[root[i]] = i;
}
num = 0;
for(int i = 1;i <= N;i ++)
{
if(cnt[i] > 2 && sum[i] > threshold * 2)
res[num].totalNum = cnt[i],res[num++].heads = Hash[heads[i]];
}
sort(res,res + num);
cout<<num<<endl;
for(int i = 0;i < num;i ++)
cout<<res[i].heads<<" "<<res[i].totalNum<<endl;
return 0;
}
1035
题意:给出N个用户的信息,包括名字name和密码pwd,由于pwd中有些字符不容易识别,需要替换。1 替换成 @, 0 替换成 %, l 替换成 L, O 替换成 o. 计算最后有几个用户的pwd需要进行替换,按输入顺序输出用户信息。最后输出的格式注意一下即可
思路:水题。
#include <iostream>
#include <cstdio>
#include <cstring>
#include <string>
#include <cmath>
#include <algorithm>
using namespace std;
const int Maxn = 1010;
struct user
{
string name;
string pwd;
bool change;
};
user users[Maxn];
bool check(string &s)
{
bool flag = false;
for(int i = 0;i < s.length();i ++)
{
if(s[i] == '1')
s[i] = '@',flag = true;
if(s[i] == '0')
s[i] = '%',flag = true;
if(s[i] == 'l')
s[i] = 'L',flag = true;
if(s[i] == 'O')
s[i] = 'o',flag = true;
}
return flag;
}
int main()
{
int N,cnt = 0;
cin>>N;
for(int i = 0;i < N;i ++)
{
cin>>users[i].name>>users[i].pwd;
users[i].change = false;
if(check(users[i].pwd))
users[i].change = true,cnt ++;
}
if(cnt == 0)
{
if(N == 1)
cout<<"There is 1 account and no account is modified"<<endl;
else
cout<<"There are "<<N<<" accounts and no account is modified"<<endl;
}
else
{
cout<<cnt<<endl;
for(int i = 0;i < N;i ++)
if(users[i].change == true)
cout<<users[i].name<<" "<<users[i].pwd<<endl;
}
return 0;
}
1036
题意:给出N个学生的信息,姓名,性别,id,成绩,现要求出男生中成绩最低的学生和女生中成绩最高的学生, 并计算两者的成绩差,按要求输出。
思路:由于最后只要保留两个学生的成绩,所以在输入的时候就可以进行判断了,用不着都存下来然后去排序。
#include <iostream>
#include <cstdio>
#include <cstring>
#include <string>
#include <cmath>
#include <algorithm>
#include <vector>
using namespace std;
struct people
{
string name;
string gender;
string id;
int grade;
};
people p[5];
int main()
{
int N;
cin>>N;
string name,gender,id;
int grade,male = 0,female = 0;
while(N --)
{
cin>>name>>gender>>id>>grade;
if(gender == "M")
{
if(male == 0 || grade < p[0].grade)
p[0].name = name,p[0].gender = gender,p[0].id = id,p[0].grade = grade,male = 1;
}
else
{
if(female == 0 || grade > p[1].grade)
p[1].name = name,p[1].gender = gender,p[1].id = id,p[1].grade = grade,female = 1;
}
}
if(female == 0)
cout<<"Absent"<<endl;
else
cout<<p[1].name<<" "<<p[1].id<<endl;
if(male == 0)
cout<<"Absent"<<endl;
else
cout<<p[0].name<<" "<<p[0].id<<endl;
if(male == 1 && female == 1)
cout<<p[1].grade - p[0].grade<<endl;
else
cout<<"NA"<<endl;
return 0;
}
1037
题意:有一些优惠券和商品,每张优惠券上都有一个值,每样商品也有一个值,优惠券上的值x表示使用该优惠券时可以拿回x倍商品的价格,但是,商品的价格有可能出现负数,例如当x=4,商品价格y = -3的时候表示我反而需要支付12元钱。求最后我使用优惠券能拿回的最大的价钱。
思路:可以将优惠券和商品的价格按正负分开,正的降序排,负的升序排,正的优惠券去买价格为正的商品,负的优惠券去买价格为负的商品
#include <iostream>
#include <cstdio>
#include <vector>
#include <algorithm>
#include <cstring>
#include <string>
#include <map>
using namespace std;
const int Maxn = 100010;
int product[Maxn],negProduct[Maxn];
int coupon[Maxn],negCoupon[Maxn];
bool cmp(int x,int y)
{
return x > y;
}
int main()
{
int N,posP = 0,negP = 0,posC = 0,negC = 0,x;
cin>>N;
for(int i = 0;i < N;i ++)
{
cin>>x;
if(x > 0)
coupon[posC++] = x;
else if(x < 0)
negCoupon[negC++] = x;
}
cin>>N;
for(int i = 0;i < N;i ++)
{
cin>>x;
if(x > 0)
product[posP++] = x;
else if(x < 0)
negProduct[negP++] = x;
}
sort(coupon,coupon + posC,cmp);
sort(product,product + posP,cmp);
sort(negCoupon,negCoupon + negC);
sort(negProduct,negProduct + negP);
long long ans = 0;
for(int i = 0;i < min(posP,posC);i ++)
ans += ((long long)coupon[i])* product[i];
for(int i = 0;i < min(negP,negC);i ++)
ans += ((long long)negCoupon[i]) * negProduct[i];
cout<<ans<<endl;
return 0;
}1038
题意:给出N个数字,要将这N个数字连成一串,得到的结果为字典序最小的结果。{32, 321, 3214, 0229, 87}可以随意组合成32-321-3214-0229-87 or 0229-32-87-321-3214 等等,但是0229-321-3214-32-87这种组合是最小的
思路:我把这些数字都看成字符串,其实就是对这一组字符串进行排序,考虑有两个字符串s1 和 s2 如果s1 + s2 < s2 + s1 ,那么s1排在s2前面,否则s2排在前面。
例如
s1 = "123",s2 = "45",
s1 + s2 = "12345",
s2 + s1 = "45123",
明显s1 + s2 < s2 + s1,s1排在前面
#include <iostream>
#include <cstdio>
#include <vector>
#include <algorithm>
#include <cstring>
#include <string>
using namespace std;
const int Maxn = 10010;
bool cmp(string x,string y)
{
return x + y < y + x;
}
string s[Maxn];
int main()
{
int N;
cin>>N;
for(int i = 0;i < N;i ++)
cin>>s[i];
sort(s,s + N,cmp);
bool flag = false;
for(int i = 0;i < N;i ++)
{
if(flag)
cout<<s[i];
else
{
for(int j = 0;j < s[i].length();j ++)
{
if(s[i][j] == '0' && flag == false) continue;
cout<<s[i][j];
flag = true;
}
}
}
if(!flag)
cout<<0;
cout<<endl;
return 0;
}1039
题意:有N个学生和K门课( N≤40000,k≤2500 ),给出k门课的index以及对应的学生姓名,没门课的学生不超过200,最后要求每个学生分别选了哪几门课。
思路:首先想到的就是 map<string,set<int>> 结构来存储每个学生对应的课程index。但是计算一下空间,40000 * 2500 * 8byte = 800000kb左右,可能超内存,但是实际上应该是没有那么多的。但是这个存储结构最后一组数据过不去。再看看题目中给的条件,name由3个大写字母和一个数字构成,一般在比较字符串相不相等时比较费时,需要一个个字符比下去直到比出结果,所以可以将字符串转换为数字进行比较,这里可以转换的最大数字是ZZZ9, 。所以只要开辟 Maxn = 26*26*26*10的空间去存储相应的值就可以了, set<int>se[Maxn]
#include <iostream>
#include <cstdio>
#include <cstring>
#include <string>
#include <cmath>
#include <algorithm>
#include <vector>
#include <set>
using namespace std;
const int Maxn = 200010;
set<int> se[Maxn];
set<int>::iterator it;
int getVal(const char *s)
{
return (s[0] - 'A') * 26 * 26 * 10 + (s[1] - 'A') * 26 * 10 + (s[2] - 'A') * 10 + (s[3] - '0');
}
int main()
{
int N,K,index,n;
char name[10];
scanf("%d%d",&N,&K);
while(K --)
{
scanf("%d%d",&index,&n);
while(n --)
{
scanf("%s",name);
int nameVal = getVal(name);
se[nameVal].insert(index);
}
}
while(N --)
{
scanf("%s",name);
int nameVal = getVal(name);
printf("%s %d",name,se[nameVal].size());
for(it = se[nameVal].begin();it != se[nameVal].end();it++)
printf(" %d",*it);
printf("\n");
}
return 0;
}
相关题目:1047
1040
题意:给出一个字符串s(长度不超过1000),求最长回文子串的长度。
思路:由于长度不超过1000,可用dp来做。dp[i][j] 表示从第i个字符串到第j个字符串是否为回文字符串。当s[i] == s[j] && (i + 1 > j - 1 || dp[i + 1][j - 1] == true )时,dp[i][j] = true,否则dp[i][j] = false,计算dp[i][j] = true时j - i + 1的最大长度即可。这里没有用manacher这种复杂度低的算法是因为题目也没有告诉我们s中不可能出现的字符,不能用常见的‘#’去替代。
#include <iostream>
#include <cstdio>
#include <cstring>
#include <string>
#include <cmath>
#include <algorithm>
#include <vector>
using namespace std;
const int Maxn = 1010;
bool dp[Maxn][Maxn];
int main()
{
string str;
getline(cin,str);
int len = str.length();
int Max = 1;
for(int j = 0;j < len;j ++)
{
for(int i = 0;i <= j;i ++)
{
if(i == j) dp[i][j] = true;
else
{
dp[i][j] = false;
if(str[i] == str[j])
{
if(i + 1 > j - 1 || dp[i + 1][j - 1] == true)
{
dp[i][j] = true;
Max = max(Max,j - i + 1);
}
}
}
}
}
cout<<Max<<endl;
return 0;
}
1041
题意:给定N个数(N<=10^5),计算这些数中只出现一次的数,并输出这种数中第一个出现的数,没有就输出None
思路:比较暴力的算法就可以了, 这里时限卡的比较严,可能用STL就会超时,毕竟要find一下,直接暴力上
#include <iostream>
#include <cstdio>
#include <cstring>
#include <string>
#include <cmath>
#include <algorithm>
#include <vector>
using namespace std;
const int Maxn = 10010;
int x[Maxn * 10];
int flag[Maxn];
int main()
{
int N;
cin>>N;
for(int i = 0;i < N;i ++)
{
cin>>x[i];
flag[x[i]]++;
}
int f = -1;
for(int i = 0; i < N;i ++)
{
if(flag[x[i]] == 1)
{
f = x[i];
break;
}
}
if(f == -1)
cout<<"None"<<endl;
else
cout<<f<<endl;
return 0;
}
1042
题意:54张牌,给定初始的顺序,先要洗牌,给出洗牌的序列,表示第i张牌洗一次后应该放在第j个位置上,现要求洗k次牌后牌的最终顺序。
思路:暴力。
#include <iostream>
#include <cstdio>
#include <cstring>
#include <string>
#include <cmath>
#include <algorithm>
using namespace std;
string str[60]={"","S1","S2","S3","S4","S5","S6","S7","S8","S9","S10","S11","S12","S13",
"H1","H2","H3","H4","H5","H6","H7","H8","H9","H10","H11","H12","H13",
"C1","C2","C3","C4","C5","C6","C7","C8","C9","C10","C11","C12","C13",
"D1","D2","D3","D4","D5","D6","D7","D8","D9","D10","D11","D12","D13",
"J1","J2"};
string res[60];
int num[60];
int main()
{
int k;
cin>>k;
k--;
for(int i = 1;i <= 54;i ++)
cin>>num[i],res[i] = str[i];
for(int i = 1;i <= 54;i ++)
{
if(k < 0) continue;
int tmp = k;
int ans = num[i];
while(tmp --)
ans = num[ans];
res[ans] = str[i];
}
for(int i = 1;i <= 54;i ++)
cout<<((i == 1)?"":" ")<<res[i];
cout<<endl;
return 0;
}
1043
题意:给出一棵树先序遍历的结果,判断其是否为二叉搜索树(BST)或者镜像二叉搜索树。如果是,输出后序遍历的结果
思路:不要直接用数组去表示,因为最坏情况要开2^1000空间,不可能。
我的思路是先构建树,再先序遍历一遍构建的数,看看顺序是否等于给出的序列,如果是,则它是一棵BST,如果不是,再判断一下它是否为镜像BST。
我在建树的时候每次都从顶端开始找某个点应该放的位置,这样我感觉效率不是很高?是否有更好的建树的方法?
#include <iostream>
#include <cstdio>
#include <vector>
#include <algorithm>
#include <cstring>
#include <string>
using namespace std;
const int Maxn = 10020;
int x[Maxn];
bool flag = true;
int cnt;
struct node
{
int val;
node *left,*right;
node(int x)
{
val = x;
left = right = NULL;
}
};
node *root = NULL;
node* buildTree(int x,node *p)//建树
{
if(p == NULL)
{
if(root == NULL)
{
root = new node(x);
p = root;
}
else
p = new node(x);
return p;
}
if(x < p->val)
p->left = buildTree(x,p->left);
else
p->right = buildTree(x,p->right);
return p;
}
void preOrder(node* p)//先序遍历
{
if(p == NULL) return;
if(p->val != x[cnt++])
flag = false;
preOrder(p->left);
preOrder(p->right);
}
void postOrder(node* p)//看看是否为mirror BST
{
if(p == NULL) return;
if(p->val != x[cnt++])
flag = false;
postOrder(p->right);
postOrder(p->left);
}
void postPrint(node* p)//BST 后序输出
{
if(p == NULL) return;
postPrint(p->left);
postPrint(p->right);
if(cnt++ != 0) cout<<" ";
cout<<p->val;
}
void mirrorPostPrint(node* p)//mirror BST 后序输出
{
if(p == NULL) return;
mirrorPostPrint(p->right);
mirrorPostPrint(p->left);
if(cnt++ != 0) cout<<" ";
cout<<p->val;
}
int main()
{
int N;
cin>>N;
for(int i = 0;i < N;i ++)
{
cin>>x[i];
root = buildTree(x[i],root);
}
cnt = 0;
preOrder(root);//看看构建的树先序遍历的结果是否等于给出的序列
if(flag == true)
{
cnt = 0;
cout<<"YES"<<endl;
postPrint(root);
cout<<endl;
}
else
{
cnt = 0;
flag = true;
postOrder(root);//看看构建的树 镜像先序遍历是否等于给出的序列
if(flag == true)
{
cout<<"YES"<<endl;
cnt = 0;
mirrorPostPrint(root);
cout<<endl;
}
else
{
cout<<"NO"<<endl;
}
}
return 0;
}1044
题意:给出N个数( N≤105 )和M,要求连续子系列,使得子序列的和为M,输出满足条件的子序列的起点和终点,按起点的字典序输出。如果找不到这样的子序列,则要找子序列的和与M相差最小的子序列,并按同样的要求输出。
思路:如果只是要找sum=M的子序列就比较好找,容易想到先计算前缀和,然后一次遍历每个数,二分查找可能出现的位置。但是题目中还有个条件,sum!=M时,找一个离M最近的sum,若还是按原来的想法,那么就是O(N^2)的复杂度了。。。
这题可以用尺取法的方法来做,尺取法之前有写过,见这里
#include <iostream>
#include <cstdio>
#include <cstring>
#include <string>
#include <cmath>
#include <algorithm>
#include <vector>
using namespace std;
const int Maxn = 100010;
const int Inf = 100000010;
int val[Maxn];
int main()
{
int N,M,l,r,Max,sum;
bool flag = false;
scanf("%d%d",&N,&M);
for(int i = 1;i <= N;i ++)
scanf("%d",&val[i]);
l = r = 1;
Max = Inf;
sum = val[1];
while(r <= N)
{
if(sum < M)
sum += val[++r];
else
{
Max = min(Max,sum);
if(sum == M)
{
flag = true;
printf("%d-%d\n",l,r);
}
sum -= val[l ++];
}
}
if(Max > M)//没找到sum=M的,就再找一遍距离M值最近且大于M的值Max,使得sum=Max
{
l = r = 1;
sum = val[1];
while(r <= N)
{
if(sum < Max)
sum += val[++r];
else
{
if(sum == Max)
printf("%d-%d\n",l,r);
sum -= val[l++];
}
}
}
return 0;
}
1045
题意:给出两个串x,y(x中元素个数<=200,y中元素个数<=10000)。现要按x中元素给出的顺序在y中找相应的子序列,使得这个子序列长度最长。
eg:
x = {2 3 1 5 6}
y = {2 2 4 1 5 5 6 3 1 1 5 6}
可找出4个子序列,使得长度最长: {2 2 1 1 1 5 6}, {2 2 1 5 5 5 6}, {2 2 1 5 5 6 6}, and {2 2 3 1 1 5 6}.
思路:dp。dp[i][j] 表示x中前i个字符与y中前j个字符可组成满足条件的最长子序列。当x[i] = y[j] 时dp[i][j] = max(dp[i - 1][j - 1] ,dp[i - 1][j], dp[i][j - 1] ) + 1。否则,dp[i][j] = max(dp[i - 1][j - 1] ,dp[i - 1][j], dp[i][j - 1] ) 。
#include <iostream>
#include <cstdio>
#include <cstring>
#include <string>
#include <cmath>
#include <algorithm>
using namespace std;
const int Maxn = 210;
int dp[Maxn][10010];
int x[Maxn],y[10010];
int main()
{
int N,n,m;
cin>>N;
cin>>n;
for(int i = 1;i <= n;i ++)
cin>>x[i];
cin>>m;
for(int i = 1;i <= m;i ++)
cin>>y[i];
for(int i = 1;i <= n;i ++)
for(int j = 1;j <= m;j ++)
{
dp[i][j] = max(dp[i - 1][j - 1],max(dp[i - 1][j],dp[i][j - 1]));
if(x[i] == y[j])
dp[i][j] ++;
}
cout<<dp[n][m]<<endl;
return 0;
}
上面的代码可以过,但是比较浪费空间,dp其实没必要开那么大的空间,可以用滚动数组的方法,节省空间:
#include <iostream>
#include <cstdio>
#include <cstring>
#include <string>
#include <cmath>
#include <algorithm>
using namespace std;
const int Maxn = 210;
int dp[Maxn][2];
int x[Maxn],y[10010];
int main()
{
int N,n,m;
cin>>N;
cin>>n;
for(int i = 1;i <= n;i ++)
cin>>x[i];
cin>>m;
for(int i = 1;i <= m;i ++)
cin>>y[i];
for(int j = 1;j <= m;j ++)
{
for(int i = 1;i <= n;i ++)
{
dp[i][1] = max(dp[i - 1][0],max(dp[i - 1][1],dp[i][0]));
if(x[i] == y[j])
dp[i][1] ++;
}
for(int i = 1;i <= n;i ++)
dp[i][0] = dp[i][1];
}
cout<<dp[n][0]<<endl;
return 0;
}
1046
题意:给出N个点及N条边的长度,N个点连成一个环,N条边的长度表示1->2,2->3,…N - 1 -> N, N->1的长度,要求x->y的最短距离。
思路:暴力,求个前缀和就可以了
#include <iostream>
#include <cstdio>
#include <cstring>
#include <string>
#include <cmath>
#include <algorithm>
using namespace std;
const int Maxn = 100010;
int val[Maxn];
int main()
{
int N,M,x,a,b;
cin>>N;
for(int i = 1;i <= N;i ++)
{
cin>>x;
val[i + 1] = val[i] + x;
}
cin>>M;
while(M--)
{
cin>>a>>b;
if(a > b) swap(a,b);
cout<<min(val[b] - val[a],val[a] + val[N + 1] - val[b])<<endl;
}
return 0;
}
1047
题意:给出N个学生的选课情况( N≤40000 ),课程数量为K( K≤2500 ),N条记录,每条记录包括学生姓名(name),选课数量(C)和所选课程对应ID,( C≤20 ),最后要求给出每门课的学生姓名,按字典序顺序输出。
思路:跟1039题的需求刚好相反,将学生姓名转换为数字存储。 vector<int>vec[Maxn] ,Maxn开2500大小,存放第i们课所选学生的信息。姓名的字符串与int的对应关系可存放在map中,但是也不要用string,因为输出会变慢,所以可以用char*。
#include <iostream>
#include <cstdio>
#include <cstring>
#include <string>
#include <cmath>
#include <algorithm>
#include <vector>
#include <set>
#include <map>
using namespace std;
const int Maxn = 2510;
vector<int> vec[Maxn];//我的方法若使用set也会超时。。不如最后统一排一下序来得快
vector<int>::iterator it;
map<int,char*> mp;
int getVal(char *s)
{
return (s[0] - 'A') * 26 * 26 * 10 + (s[1] - 'A') * 26 * 10 + (s[2] - 'A') * 10 + (s[3] - '0');
}
int main()
{
std::ios::sync_with_stdio(false);
int N,K,n,x;
char name[5];
scanf("%d%d",&N,&K);
while(N --)
{
scanf("%s%d",name,&n);
int nameVal = getVal(name);
char *tmpName = new char[5];
strcpy(tmpName,name);
mp[nameVal] = tmpName;
for(int i = 0;i < n;i ++)
{
scanf("%d",&x);
vec[x].push_back(nameVal);
}
}
for(int i = 1;i <= K;i ++)
{
printf("%d %d\n",i,vec[i].size());
sort(vec[i].begin(),vec[i].end());
for(it = vec[i].begin();it != vec[i].end();it++)
printf("%s\n",mp[*it]);
}
return 0;
}
1048
题意:给出N个银币的值和要买的物品的价格M,( N≤105 ),要求是否正好有两个硬币能构成的价格为M,要求输出这两个硬币的值x,y(x < y),若有多组数据,输出x较小的那组解,如果不存在解,输出No Solution。
思路:水题。
#include <iostream>
#include <cstdio>
#include <cstring>
#include <string>
#include <cmath>
#include <algorithm>
#include <map>
using namespace std;
map<int,int> mp;
map<int,int>::iterator it;
int main()
{
int N,M,x;
cin>>N>>M;
while(N --)
{
cin>>x;
mp[x]++;
}
bool flag = false;
for(it = mp.begin();it != mp.end();it ++)
{
int y = M - it->first;
if(y < it->first) break;
if((it->first == y && it->second > 1) || (it->first != y && mp.find(y) != mp.end()))
{
cout<<it->first<<" "<<y<<endl;
flag = true;
break;
}
}
if(flag == false)
cout<<"No Solution"<<endl;
return 0;
}
1049
题意:
思路:
1050
题意:给出字符串A,B,要求将A中去掉出现在B中字符,输出最后的结果,字符范围ascii表
思路:给的时间很少,注意就好。
#include <iostream>
#include <cstdio>
#include <cstring>
#include <string>
#include <cmath>
#include <algorithm>
using namespace std;
const int Maxn = 10010;
char str[Maxn],sub[Maxn];
bool f[200];
int main()
{
gets(str);
gets(sub);
/*这里不要为了图方便写成for(int i = 0;i < strlen(sub);i ++)
这样每次循环都会计算一遍strlen(sub),会超时的。 */ int len = strlen(sub);
for(int i = 0;i < len;i ++)
f[sub[i]] = true;
len = strlen(str);
for(int i = 0;i < len;i ++)
{
if(f[str[i]] == false)
printf("%c",str[i]);
}
printf("\n");
return 0;
}
1051
题意:模拟栈。给出M,N,K, 表示K组数据,每组数据有N个数,栈的最大容量为M。现要求每组数据是不是一组可能出现的出栈顺序。
思路:直接用栈去模拟就可以了
#include <iostream>
#include <cstdio>
#include <cstring>
#include <string>
#include <cmath>
#include <algorithm>
#include <stack>
using namespace std;
const int Maxn = 1010;
stack<int> stk;
int val[Maxn];
int main()
{
int N,M,K;
cin>>M>>N>>K;
while(K --)
{
for(int i = 1;i <= N;i ++)
cin>>val[i];
int s = 1;
for(int i = 1;i <= N;i ++)
{
if(i != val[s])
{
if(stk.size() >= M)
break;
stk.push(i);
}
else
{
if(stk.size() >= M)
break;
s++;
while(!stk.empty())
{
if(stk.top() != val[s])
break;
s++;
stk.pop();
}
}
}
if(stk.size() > 0)
cout<<"NO"<<endl;
else
cout<<"YES"<<endl;
while(!stk.empty())
stk.pop();
}
return 0;
}
1052
题意:链表排序。给出N个节点和起始点的位置,每个节点有3个值,节点的位置,节点的值和下一个节点。现要根据节点的值对链表进行排序。输出最终的结果。
思路:此题好坑,题目说的不清不楚的。题中可能有多条链的存在,若这种情况,只需输出第一条链重排后的结果就行。 还有,若一开始给出的其实节点就是-1,那输出0,-1
eg:
5 00001
11111 100 -1
00001 0 22222
33333 100000 11111
12345 -1 -1
22222 1000 12345
输出结果:
3 12345
12345 -1 00001
00001 0 22222
22222 1000 -1
5 -1
11111 100 -1
00001 0 22222
33333 -1000 11111
12345 -1 33333
22222 1000 12345
输出结果:
0 -1注意上面两点,代码还是不难的:
#include <iostream>
#include <cstdio>
#include <cstring>
#include <string>
#include <cmath>
#include <algorithm>
using namespace std;
const int Maxn = 100010;
struct node
{
int start;
int val;
int next;
bool operator < (const node &x) const
{
return val < x.val;
}
};
node p[Maxn],q[Maxn];
int Hash[Maxn];
int main()
{
int N,S,start;
scanf("%d%d",&N,&S);
for(int i = 0;i < N;i ++)
{
scanf("%d%d%d",&p[i].start,&p[i].val,&p[i].next);
Hash[p[i].start] = i;
}
int x = S;
int cnt = 0;
while(x != -1)
{
q[cnt].start = p[Hash[x]].start;
q[cnt].val = p[Hash[x]].val;
q[cnt++].next = x = p[Hash[x]].next;
}
sort(q,q + cnt);
if(S == -1)
printf("0 -1\n");
else
{
printf("%d %05d\n",cnt,q[0].start);
for(int j = 0;j < cnt - 1;j ++)
printf("%05d %d %05d\n",q[j].start,q[j].val,q[j + 1].start);
printf("%05d %d -1\n",q[cnt - 1].start,q[cnt - 1].val);
}
return 0;
}
1053
题意:给定N个节点的一棵树,每个节点都有一个权值weight,现有给定值K,要求从根节点到某叶节点的路径中所有点的权值相加等于K,求出这些路径。最后输出这些路径中每个节点的权值,要求按权值大小降序输出。
Note: sequence {A1, A2, …, An} is said to be greater than sequence {B1, B2, …, Bm} if there exists 1 <= k < min{n, m} such that Ai = Bi for i=1, … k, and Ak+1 > Bk+1.
例如:
10 5 2 7
10 4 10
5 > 4 ,所以路径定义中10 5 2 7这条路 > 10 4 10这条路
思路:由于最后要求按路径权值从大到小输出,所以在保存某个节点的子节点时,可以先按子节点的权值顺序进行排序存储,然后dfs一遍就可以了。
#include <iostream>
#include <cstdio>
#include <vector>
#include <algorithm>
#include <cstring>
#include <string>
#include <vector>
using namespace std;
const int Maxn = 110;
int val[Maxn];
vector<int> vec[Maxn],tmp;
vector<vector<int> > ans;//存储最后的结果
int N,M,K,sum;
bool cmp(int x,int y)
{
return val[x] > val[y];
}
void dfs(int n)
{
if(vec[n].size() == 0)
{
if(sum == K)
ans.push_back(tmp);
return ;
}
for(int i = 0;i < vec[n].size();i ++)
{
tmp.push_back(val[vec[n][i]]);
sum += val[vec[n][i]];
dfs(vec[n][i]);
sum -= val[vec[n][i]];
tmp.erase(tmp.end() - 1);
}
}
int main()
{
int x,n,num;
cin>>N>>M>>K;
for(int i = 0;i < N;i ++)
cin>>val[i];
for(int i = 0;i < M;i ++)
{
cin>>x>>n;
for(int j = 0;j < n;j ++)
{
cin>>num;
vec[x].push_back(num);
}
sort(vec[x].begin(),vec[x].end(),cmp);//先按每个节点的weight排好序,符合输出结果要求的顺序
}
tmp.push_back(val[0]);
sum = val[0];
dfs(0);
for(int i = 0;i < ans.size();i ++)
{
for(int j = 0;j < ans[i].size();j ++)
{
if(j != 0) cout<<" ";
cout<<ans[i][j];
}
cout<<endl;
}
return 0;
} 1054
题意:给出N*M的矩阵,求出其中出现次数大于N*M/2的数
思路:暴力,遍历一遍好了
#include <iostream>
#include <cstdio>
#include <cstring>
#include <string>
#include <cmath>
#include <algorithm>
#include <map>
using namespace std;
map<int,int> mp;
int main()
{
int N,M,x,num,ans;
cin>>N>>M;
num = (N * M + 1) / 2;
for(int i = 0;i < M;i ++)
{
for(int j = 0;j < N;j ++)
{
cin>>x;
mp[x] ++;
if(mp[x] >= num)
ans = x;
}
}
cout<<ans<<endl;
return 0;
}
1055
题意:给出N个人的信息( N≤105 ),包括姓名,年龄,价值。现有K( M≤1000 )个询问,每个询问包括M,a,b,( M≤100 )要求出年龄在[a,b]之间的价值最大的M个人的信息,不足M人时输出符合条件的人就可以了,一个都没有就输出None。
思路:排序。。要注意M和K的范围。M比较小,所以我可以先对N个人按最后的要求进行排序,每次询问时找到符合条件数量的人后就不继续找就可以了。
#include <iostream>
#include <cstdio>
#include <cstring>
#include <string>
#include <cmath>
#include <algorithm>
using namespace std;
const int Maxn = 100010;
struct people
{
char name[10];
int age;
int val;
bool operator < (const people &x) const
{
if(val != x.val)
return val > x.val;
else
{
if(age != x.age)
return age < x.age;
else
return strcmp(name,x.name) < 0;
}
}
};
people p[Maxn];
int N,K,M,a,b;
int main()
{
scanf("%d%d",&N,&K);
for(int i = 0;i < N;i ++)
scanf("%s%d%d",p[i].name,&p[i].age,&p[i].val);
sort(p,p + N);
for(int cas = 1;cas <= K;cas ++)
{
scanf("%d%d%d",&M,&a,&b);
printf("Case #%d:\n",cas);
int f = 0;
for(int i = 0;i < N; i ++)
{
if(p[i].age >= a && p[i].age <= b)
{
printf("%s %d %d\n",p[i].name,p[i].age,p[i].val);
M--;
f = 1;
if(M == 0) break;
}
}
if(f == 0)
printf("None\n");
}
return 0;
}
上面的做法还是不够优化的,很多信息冗余,比如同一年龄段的人数如果超过100,那只要取前100就可以了,后面的人时不可能用到的,所以有效的总人数会减少,这样最后循环判断的时候可以节省一些时间。
1056
题意:有NP只老鼠,每只老鼠有一个体重值w,每只体重都不相同。现在要进行决斗,每NG只老鼠为一组,最后不足NG只也凑一组,每组中体重值最大的获胜,获胜的老鼠中再进行组合,直到所有老鼠都分出胜负,求出每只老鼠最后的排名。
思路:简单题,就是题目描述有点点鬼畜。首先给出NP,NG,接下来给出NP只老鼠的体重。再接下来一行给出一开始老鼠的排序情况,6,0,8…表示6号老鼠排在第一位,0号老鼠排在第二位,依次。。组队时按排列的顺序从左到右每NG只老鼠组一队。
#include <iostream>
#include <cstdio>
#include <cmath>
#include <algorithm>
#include <cstring>
#include <string>
#include <vector>
using namespace std;
vector<int> vec,tmp;
const int Maxn = 1010;
int w[Maxn],rk[Maxn];
int main()
{
int NP,NG,x;
cin>>NP>>NG;
for(int i = 0;i < NP;i ++)
cin>>w[i];
for(int i = 0;i < NP;i ++)
{
cin>>x;
vec.push_back(x);
}
while(vec.size())
{
int sz = vec.size();
if(sz == 1)
{
rk[vec[0]] = 1;
break;
}
for(int i = 0;i < sz;i += NG)
{
int Max = -1,k;
for(int j = i;j < min(i + NG,sz);j ++)
{
if(w[vec[j]] > Max)
{
Max = w[vec[j]];
k = vec[j];
}
rk[vec[j]] = int(ceil(sz*1.0/NG)) + 1;
}
tmp.push_back(k);
}
vec = tmp;
tmp.clear();
}
for(int i = 0;i < NP;i ++)
{
if(i != 0) cout<<" ";
cout<<rk[i];
}
cout<<endl;
return 0;
}
1057
题意:现有3中栈的操作,Push 入栈,Pop 出栈,PeekMedian 求站在栈中的所有N个数中中间小的数,若N为偶数,表示第N/2小的数,N为奇数,表示第(N + 1)/ 2小的数。
思路:扩展开来其实可以表示求第K小的数,我是用树状数组做的,数组中val[i]表示当前小于等于i的有几个数。每次查询时可以二分查找,求得小于等于K的最小的数就可以了。
用cin又会超时啊。。。
#include <iostream>
#include <cstdio>
#include <vector>
#include <algorithm>
#include <cstring>
#include <string>
#include <vector>
#include <stack>
using namespace std;
const int Maxn = 100010;
stack<int> stk;
int val[Maxn];
int lower_bit(int x)
{
return x & -x;
}
void add(int n,int x)
{
while(n < Maxn)
{
val[n] += x;
n += lower_bit(n);
}
}
int sum(int n)
{
int ans = 0;
while(n)
{
ans += val[n];
n -= lower_bit(n);
}
return ans;
}
int binarySearch(int k)
{
int l = 0,r = Maxn;
while(l <= r)
{
int mid = l + (r - l ) / 2;
int ans = sum(mid);
if(k <= ans)
r = mid - 1;
else
l = mid + 1;
}
return l;
}
int main()
{
int N,x;
char s[15];
scanf("%d",&N);
for(int i = 0;i < N;i ++)
{
scanf("%s",s);
if(s[1] == 'o')
{
if(stk.empty())
{
printf("Invalid\n");
}
else
{
printf("%d\n",stk.top());
add(stk.top(),-1);
stk.pop();
}
}
else if(s[1] == 'u')
{
scanf("%d",&x);
stk.push(x);
add(x,1);
}
else
{
if(stk.empty())
{
printf("Invalid\n");
}
else
{
printf("%d\n",binarySearch((stk.size() + 1) / 2));
}
}
}
return 0;
} 1058
题意:给出 “Galleon.Sickle.Knut”格式的两个串 (Galleon is an integer in [0, 10^7], Sickle is an integer in [0, 17), and Knut is an integer in [0, 29)).要求两个串相加后的结果,按格式输出。
思路:水题,直接计算。但是为什么我最后计算结果时把Galleon位上的数%10000001就错了呢?数据有问题吗?
#include <iostream>
#include <cstdio>
#include <algorithm>
#include <cmath>
#include <cstring>
#include <string>
using namespace std;
int main()
{
int a[3][2];
scanf("%d.%d.%d%d.%d.%d",&a[0][0],&a[1][0],&a[2][0],&a[0][1],&a[1][1],&a[2][1]);
int tmp = (a[2][0] + a[2][1]) / 29;
int x = (a[2][0] + a[2][1]) % 29;
int y = (a[1][0] + a[1][1] + tmp) % 17;
tmp = (a[1][0] + a[1][1] + tmp) / 17;
int z = (a[0][0] + a[0][1] + tmp) ;//?
printf("%d.%d.%d\n",z,y,x);
return 0;
}1059
题意:求一个数的质因子组成。97532468=2^2*11*17*101*1291
思路:先用筛素数的方法把质因子筛出来,再计算该数能被哪几个质数整除。
#include <iostream>
#include <cstdio>
#include <cstring>
#include <string>
#include <cmath>
#include <algorithm>
#include <map>
using namespace std;
const int Maxn = 100010;
int prime[Maxn];
bool flag[Maxn];
int cnt;
map<int,int> mp;
void _init()
{
for(int i = 2;i < Maxn;i ++)
{
if(flag[i] == false)
{
prime[cnt++] = i;
for(int j = i * 2;j < Maxn;j += i)
flag[j] = true;
}
}
}
void getFactor(int n)
{
cout<<n<<"=";
for(int i = 0;prime[i] * prime[i] <= n;i ++)
{
if(n % prime[i] == 0)
{
while(n % prime[i] == 0)
{
mp[prime[i]] ++;
n /= prime[i];
}
}
}
if(n != 1)
mp[n] ++;
for(map<int,int>::iterator it = mp.begin();it != mp.end();it ++)
{
cout<<((it == mp.begin())?"":"*")<<it->first;
if(it->second > 1)
cout<<"^"<<it->second;
}
cout<<endl;
}
int main()
{
_init();
int N;
cin>>N;
if(N < 2)
cout<<N<<"="<<N<<endl;
else
getFactor(N);
return 0;
}
1060
题意:给出两个数s1,s2,要求转换成 “ 0.d1...dN∗10k ” 这种格式的数,保留N为小数。判断s1,s2格式转换后是否相等。
思路:注意一些细节就可以了。给一些样例:
6 12300 12300.9
NO 0.123000*10^5 0.123009*10^5
5 12300 12300.9
YES 0.12300*10^5
0 12300 12300.9 有点奇怪的数。。
YES 0.*10^5
0 12300 12300
YES 0.*10^5
3 000 0000
YES 0.000*10^0
3 000 0001
NO 0.000*10^0 0.100*10^1
3 0.001 0.002
NO 0.100*10^-2 0.200*10^-2
#include <iostream>
#include <cstdio>
#include <cstring>
#include <string>
#include <cmath>
#include <algorithm>
using namespace std;
string getAns(string s,int n)
{
string ans = "0.";
int length = s.length();
int i = 0;
while(n --)
{
if(i >= length)
{
ans += "0";
continue;
}
if(s[i] == '.') i ++;
ans += s[i ++];
}
return ans;
}
/*将给出的字符串转化为有效的字符串,去掉前导0 000123 -> 123 */
string getS(string s,int &l)//l表示调整后的数字小数点之前的长度,如果没有小数点就是整个字符串的长度
{
string str = "";
int len = s.length();
int i = 0;
int p = -1;
while(i < len)//找出第一个不是0的数
{
if(s[i] == '.')
p = i;
else if(s[i] != '0') break;
i ++;
}
if(i == len)//遍历到末尾,此数为0,eg 000,0.000这类的
str += "0",l = 0;
else
{
if(p == -1)//第一个不是0的数之前没有小数,eg 123.36 0012.3这类 可调整成123.36 12.3
{
for(;i < s.length();i ++)
str += s[i];
l = str.find(".");
l = (l == -1)?str.length():l;
}
else//0.0012这类
{
l = p - i + 1;
for(;i < s.length();i ++)
str += s[i];
}
}
return str;
}
int main()
{
int N,len1,len2;
string s1,s2;
cin>>N>>s1>>s2;
s1 = getS(s1,len1);
s2 = getS(s2,len2);
string ans1 = getAns(s1,N);
string ans2 = getAns(s2,N);
if(len1 != len2)
{
cout<<"NO "<<ans1<<"*10^"<<len1<<" "<<ans2<<"*10^"<<len2<<endl;
}
else
{
if(ans1 == ans2)
{
cout<<"YES "<<ans1<<"*10^"<<len1<<endl;
}
else
{
cout<<"NO "<<ans1<<"*10^"<<len1<<" "<<ans2<<"*10^"<<len2<<endl;
}
}
return 0;
}
1061
题意:水题,但是题目描述真实不清。给出s1,s2,s3,s4,找出s1,s2中相同位置上相等的两个字符,代表DAY 和HH,其中DAY必须是’A’-‘G’中的数,HH必须是’0’-‘9’和’A’-‘N’中的数,同样的,在s3,s4中找同一位置上字符相同的两个数,范围在大写和小写字母中间,其他的数都不算,输出对应的位置index即可。
思路:
#include <iostream>
#include <cstdio>
#include <cstring>
#include <string>
#include <cmath>
#include <algorithm>
#include <map>
using namespace std;
string day[10] = {"MON","TUE","WED","THU","FRI","SAT","SUN"};
int main()
{
string s1,s2,s3,s4;
cin>>s1>>s2>>s3>>s4;
int len1 = s1.length(),len2 = s2.length();
int cnt = 0;
for(int i = 0,j = 0;i < len1 && j < len2;i ++,j ++)
{
if(s1[i] == s2[j])
{
if(cnt == 0)
{
if(s1[i] < 'A' || s1[i] > 'G') continue;
cout<<day[s1[i]-'A']<<" ";
}
else
{
if(s1[i] >= '0' && s1[i] <= '9')
cout<<"0"<<s1[i]<<":";
else if(s1[i] >= 'A' && s1[i] <='N')
cout<<s1[i] - 'A' + 10<<":";
else
continue;
}
cnt ++;
if(cnt >= 2) break;
}
}
len1 = s3.length(),len2 = s4.length();
for(int i = 0,j = 0;i < len1 && j < len2;i++,j ++)
{
if(s3[i] == s4[j] && ((s3[i] >= 'a' && s3[i] <= 'z') ||(s3[i] >= 'A' && s3[i] <= 'Z')))
{
if(i < 10)
cout<<"0"<<i<<endl;
else
cout<<i<<endl;
break;
}
}
return 0;
}
1062
题意:有n个人的信息,每个人包括ID,viture,talent。现有两个阈值L,H,
若 viture<L且talent<L ,这部分人考虑不计,
若 viture≥H且talent≥H ,此人为圣人;
若 viture≥H且talent<H ,此人为君子;
若 viture<H且talent<H且viture≥talent ,此人为愚人;
否则为小人。
先要按圣人、君子、愚人、小人的顺序输出相应的人物。首先按talent+viture的得分降序排,得分相同时按viture降序排列,还相同时,按ID升序排。
思路:sort一发,注意cin要超时。
#include <iostream>
#include <cstdio>
#include <algorithm>
#include <cmath>
#include <string>
#include <cstring>
using namespace std;
const int Maxn = 100010;
struct person
{
int ID;
int talent,virtue,grade;
int f;
bool operator < (const person& x ) const
{
if(f != x.f) return f > x.f;
if(grade != x.grade) return grade > x.grade;
if(virtue != x.virtue) return virtue > x.virtue;
return ID < x.ID;
}
};
person p[Maxn];
int main()
{
int N,L,H,id,t,v,cnt = 0;
scanf("%d%d%d",&N,&L,&H);
for(int i = 0;i < N;i ++)
{
scanf("%d%d%d",&id,&v,&t);
if(t >= L && v >= L)
{
p[cnt].ID = id,p[cnt].talent = t,p[cnt].virtue = v,p[cnt].grade = t + v;
if(t >= H && v >= H)
p[cnt++].f = 4;
else if(t < H && v >= H)
p[cnt++].f = 3;
else if(t < H && v < H && v >= t)
p[cnt++].f = 2;
else
p[cnt++].f = 1;
}
}
sort(p,p + cnt);
printf("%d\n",cnt);
for(int i = 0;i < cnt;i ++)
printf("%d %d %d\n",p[i].ID,p[i].virtue,p[i].talent);
return 0;
}
1063
题意:给出N个序列,每个序列有K个数,现有M个询问,每次询问x,y两个序列中的 去重后相同数的个数/去重后x,y中拥有的数的个数 * 100。结果保留一位小数
思路:虽然每个序列中的数的范围在[0,10^9],但是N的范围比较小(<= 50),每个序列中的个数K(<=10^4),所以可以先计算一下两两序列的公共个数。
#include <iostream>
#include <cstdio>
#include <algorithm>
#include <cmath>
#include <string>
#include <cstring>
#include <set>
using namespace std;
const int Maxn = 60;
set<int> se[Maxn];
set<int>::iterator it;
int common[Maxn][Maxn];
int main()
{
int N,K,x,y;
scanf("%d",&N);
for(int i = 1;i <= N;i ++)
{
scanf("%d",&K);
while(K--)
{
scanf("%d",&x);
se[i].insert(x);
}
}
for(int i = 1;i <= N;i ++)
{
for(int j = i;j <= N;j ++)
{
if(i == j)
{
common[i][j] = se[i].size();
continue;
}
int sum = 0;
for(it = se[j].begin();it != se[j].end();it ++)
{
if(se[i].find(*it) != se[i].end())
sum++;
}
common[i][j] = sum;
}
}
scanf("%d",&K);
while(K--)
{
scanf("%d%d",&x,&y);
if(x > y) swap(x,y);
printf("%.1lf%%\n",common[x][y]*100.0 / (se[x].size() + se[y].size() - common[x][y]));
}
return 0;
}1064
题意:给出一个序列,构建完全二叉搜索树,按每一层的顺序进行输出。
思路:直接构建树,dfs一遍就好。
#include <iostream>
#include <cstdio>
#include <vector>
#include <algorithm>
#include <cstring>
#include <string>
using namespace std;
const int Maxn = 1010;
int val[Maxn],ans[Maxn];
int N;
int cnt;
void buildTree(int n)//建树
{
if(n > N) return ;
buildTree(n<<1);
ans[n] = val[cnt++];
buildTree(n<<1|1);
}
int main()
{
cin>>N;
for(int i = 0;i < N;i ++)
cin>>val[i];
sort(val,val + N);
buildTree(1);
for(int i = 1;i <= N;i ++)
{
if(i != 1) cout<<" ";
cout<<ans[i];
}
cout<<endl;
return 0;
}1065
题意:给出a,b,c,若a+b>c 输出true,否则false
思路:因为数给的范围比较大,所以直接上java大整数了
import java.math.BigInteger;
import java.util.Scanner;
public class Main {
public static void main(String[] args) {
Scanner in = new Scanner(System.in);
int N = in.nextInt();
BigInteger a,b,c;
for(int i = 1;i <= N;i ++) {
a = in.nextBigInteger();
b = in.nextBigInteger();
c = in.nextBigInteger();
System.out.print("Case #"+i+": ");
if(a.add(b).compareTo(c) > 0)
System.out.println("true");
else
System.out.println("false");
}
}
}
1066
题意:构造二叉搜索平衡树,求根节点的值。
思路:节点挺少的,按平衡树四种旋转方式进行。当年保研机试的题,orz。
由于每个数都不同,所以可以进行简单的如下考虑。如果有重复的值,就不能简单考虑,不如左旋时可能会将相等大小的值旋转到左子树上,这样就不符合二叉搜索平衡树的要求了。

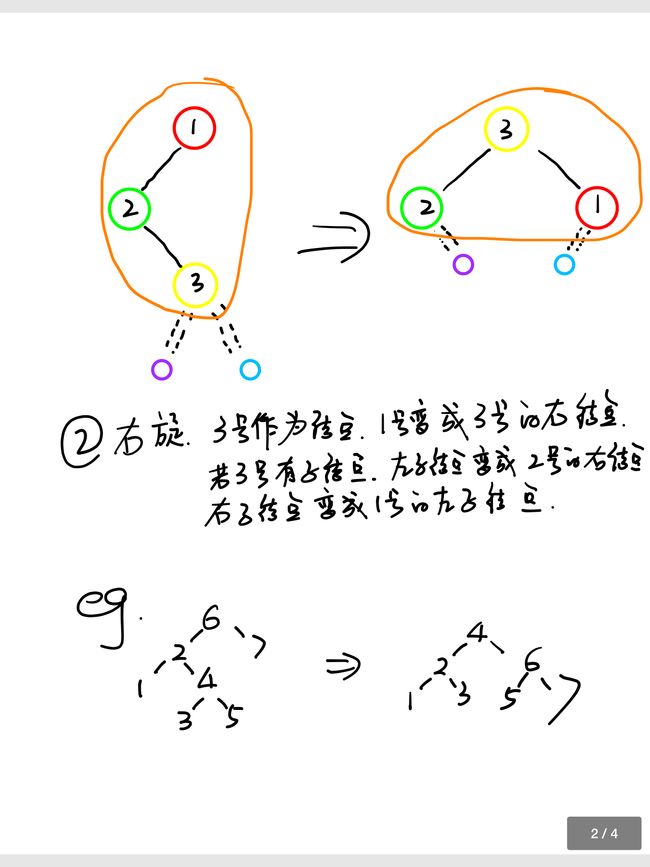

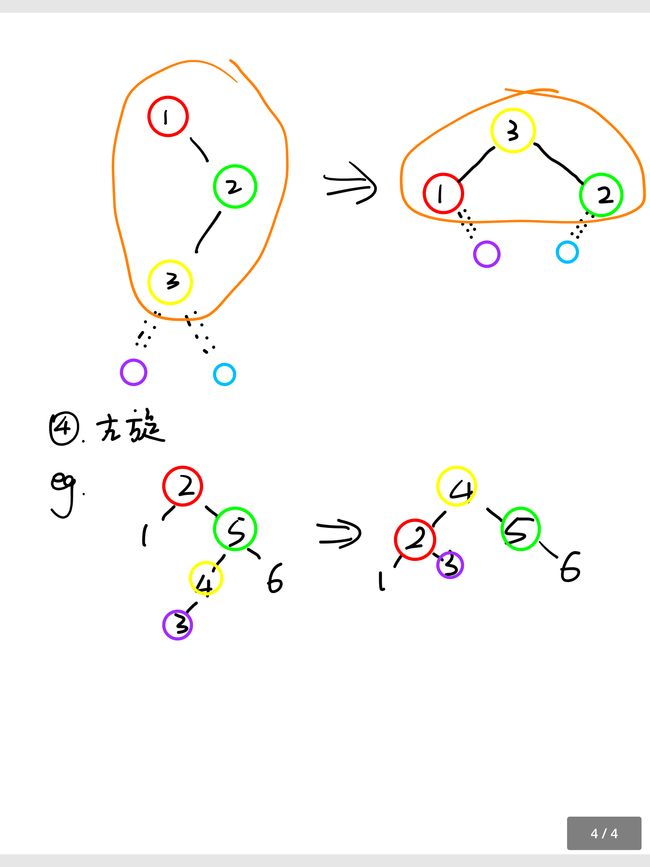
代码貌似写得有点冗余
#include <iostream>
#include <cstdio>
#include <cmath>
#include <algorithm>
#include <cstring>
#include <string>
#include <vector>
using namespace std;
struct node
{
int val,lsum,rsum;//lsum,rsum记录当前节点左子树深度和右子树深度
node *left,*right;
node(int x)
{
val = x;
lsum = rsum = 0;
left = right = NULL;
}
};
node *root = NULL;
bool flag ;
node* buildTree(node *root,int k)//建树
{
if(root == NULL)
{
root = new node(k);
return root;
}
if(k < root->val)
root->left = buildTree(root->left,k);
else
root->right = buildTree(root->right,k);
return root;
}
int checkDeep(node *root)
{
if(root == NULL) return 0;
root->lsum = checkDeep(root->left);
root->rsum = checkDeep(root->right);
if(abs(root->lsum - root->rsum) > 1)
{
flag = true;
if(root->lsum - root->rsum == 2)//右旋
{
int tmp = root->val;
if(root->left->lsum > root->left->rsum)
{
node *p = root->left;
node *newNode = new node(tmp);
newNode->right = root->right;
newNode->left = p->right;
root->val = p->val;
root->left = p->left;
root->right = newNode;
delete(p);
}
else
{
node *p = root->left->right;
node *newNode = new node(tmp);
newNode->right = root->right;
newNode->left = p->right;
root->val = p->val;
root->right = newNode;
root->left->right = p->left;
delete(p);
}
root->lsum --;
root->rsum ++;
}
else if(root->rsum - root->lsum == 2)//左旋
{
int tmp = root->val;
if(root->right->rsum > root->right->lsum)
{
node *p = root->right;
node *newNode = new node(tmp);
newNode->left = root->left;
newNode->right = p->left;
root->val = p->val;
root->right = p->right;
root->left = newNode;
delete(p);
}
else
{
node *p = root->right->left;
node *newNode = new node(tmp);
newNode->left = root->left;
newNode->right = p->left;
root->val = p->val;
root->left = newNode;
root->right->left = p->right;
delete(p);
}
root->lsum ++;
root->rsum --;
}
}
return max(root->lsum , root->rsum )+ 1;
}
int main()
{
root = NULL;
int N,x;
cin>>N;
for(int i = 0;i < N;i ++)
{
cin>>x;
flag = true;
root = buildTree(root,x);
while(flag)
{
flag = false;
checkDeep(root);
}
}
cout<<root->val<<endl;
return 0;
}1067
题意:对给出的乱序序列进行排序,但是排序规则跟平常不同,swap(0,*)表示数字0与某个数进行交换。求出最少交换多少次能将乱序序列排成递增序列。
思路:如果能一次将数字排到对应的位置上,就将0与它交换,交换次数+1。如果不能一次排好(即0在自己的位置上,那就先将0排到任意一个还没排好序的位置上,然后在继续排序)
eg:
0 1 2 3 4 5 6 7 8 9
3 5 7 2 6 4 9 0 8 1
可以一次将7换到对应的位置上。
0 1 2 3 4 5 6 7 8 9
0 5 2 3 6 4 9 7 8 1
0在自己的位置上,但是序列还没有排好,所以先将0随便换到一个还没有排好序的位置上。
0 1 2 3 4 5 6 7 8 9
5 0 2 3 6 4 9 7 8 1
然后再重复之前的动作
0 1 2 3 4 5 6 7 8 9
5 0 2 3 6 4 9 7 8 1
1又可以一次就换到自己的位置了,但整体下来,这个过程需要花费2步。
#include <iostream>
#include <cstdio>
#include <algorithm>
#include <cmath>
#include <string>
#include <cstring>
#include <set>
using namespace std;
const int Maxn = 100010;
int Hash[Maxn];
int N,pos = 1;
int check()
{
//查找的时候不要每次从1查起,这样会超时的,充分利用前面的步骤来找到第一个还没有排好序的位置!
for(int i = pos;i < N;i ++)
if(Hash[i] != i)
{
pos = i;
return Hash[i];
}
pos = N;
return -1;
}
int main()
{
int x;
scanf("%d",&N);
for(int i = 0;i < N;i ++)
{
scanf("%d",&x);
Hash[x] = i;
}
int cnt = 0;
while(true)
{
while(Hash[0] != 0)
{
swap(Hash[0],Hash[Hash[0]]);
cnt ++;
}
int p = check();
if(p == -1)
break;
swap(Hash[0],Hash[p]);
swap(Hash[0],Hash[Hash[0]]);
cnt += 2;
}
printf("%d\n",cnt);
return 0;
}1068
题意:有N个硬币,每个硬币有对应的面值,现要买M价格的物品,使用其中的一些硬币使得刚好能凑够M,如果有多个解,输出字典序最小的一组。
字典序的定义如下:sequence {A[1], A[2], …} is said to be “smaller” than sequence {B[1], B[2], …} if there exists k >= 1 such that A[i]=B[i] for all i < k, and A[k] < B[k].
例如商品价格为9,用{1,2,5}优于{1,3,4}
思路:其实就是个DP,01背包,用vec[i]记录价格为M时可以由哪些面值的硬币构成。复杂度N*M。首先按硬币面值从小到大排列,依次遍历,加入当前面值为x[i]的硬币时能构成哪些价格。
样例:
8 9
5 9 8 7 2 3 4 1
(1) 排序:1 2 3 4 5 7 8 9
(2) DP
1 2 3 4 5 6 7 8 9
加入1:{1}
加入2: {2} {1,2}
加入3: {2} {1,2} {1,3} {2,3} {1,2,3}
|| ||
{1,2}比{3}小 由组成3的{1,2}得来
依次加入所有的值,即可得出最后的答案
随便扯两句。这题好像是我保研面试时的题,当时没时间做了,随便next_permutation了一发,好像只得了几分,想想那时真是白痴,哈哈。不过也让我想起了很多那个时间段的往事,如今一切都变了。。。
今天看这题的时候,一开始也没往dp上想,就简单的dfs了一发,想着应该会超时,还是试了一下,结果最后一组数据妥妥超时了,代码如下:
#include <iostream>
#include <cstdio>
#include <cmath>
#include <algorithm>
#include <cstring>
#include <string>
#include <vector>
using namespace std;
const int Maxn = 10010;
vector<int> vec,ans;
int x[Maxn];
int N,M,sum = 0;
bool flag = true;
void dfs(int n)
{
if(sum == M)
{
ans = vec;
flag = false;
return ;
}
if(n >= N) return;
for(int i = n ;i < N;i ++)
{
if(flag)
{
if(sum + x[i] <= M)
{
vec.push_back(x[i]);
sum += x[i];
dfs(i + 1);
sum -= x[i];
vec.erase(vec.end() - 1);
}
else
break;
}
else
break;
}
return ;
}
int main()
{
scanf("%d%d",&N,&M);
for(int i = 0;i < N;i ++)
scanf("%d",&x[i]);
sort(x,x + N);
dfs(0);
if(ans.size() == 0)
printf("No Solution\n");
else
{
for(int i = 0;i < ans.size();i ++)
{
if(i != 0) printf(" ");
printf("%d",ans[i]);
}
printf("\n");
}
return 0;
}
后来想了一下dp的方法,于是A了,具体代码:
#include <iostream>
#include <cstdio>
#include <cmath>
#include <algorithm>
#include <cstring>
#include <string>
#include <vector>
using namespace std;
const int Maxn = 10010;
vector<int> vec[Maxn];
int x[Maxn];
bool check(int a ,int b)
{
for(int i = 0;i < min(vec[a].size(),vec[b].size());i ++)
if(vec[a][i] < vec[b][i])
return true;
return false;
}
int main()
{
int N,M;
scanf("%d%d",&N,&M);
for(int i = 0;i < N;i ++)
scanf("%d",&x[i]);
sort(x,x + N);
for(int i = 0;i < N;i ++)
{
for(int j = M;j > x[i];j --)
{
if(vec[j - x[i]].size() != 0)
{
if(vec[j].size() == 0 || check(j - x[i],j))
{
vec[j] = vec[j - x[i]];
vec[j].push_back(x[i]);
}
}
}
if(vec[x[i]].size() == 0)
vec[x[i]].push_back(x[i]);
}
if(vec[M].size() == 0)
cout<<"No Solution"<<endl;
else
{
for(int i = 0;i < vec[M].size();i ++)
{
if(i != 0) cout<<" ";
cout<<vec[M][i];
}
cout<<endl;
}
return 0;
}
1069
题意:给出一个四位的整数,将该数每一位上的数从小到大排列所得的数 减去 该数每一位上的重点内容数从小到大排列所得数。结果再做相同的运算直到结果出现重复或者结果为0时停止。
思路:水题。
#include <iostream>
#include <cstdio>
#include <algorithm>
#include <cmath>
#include <string>
#include <cstring>
#include <set>
using namespace std;
const int Maxn = 10010;
bool Hash[Maxn];
void check(int n,int &Max,int &Min)
{
int a[4]={0};
int cnt = 0,tmp = n;
while(tmp)
{
a[cnt++] = tmp % 10;
tmp /= 10;
}
sort(a,a+4);
Max = (a[3] * 1000 + a[2] * 100 + a[1] * 10 + a[0]);
Min = (a[0] * 1000 + a[1] * 100 + a[2] * 10 + a[3]);
}
int main()
{
int N;
scanf("%d",&N);
while(true)
{
int Max,Min,diff;
check(N,Max,Min);
diff = Max - Min;
if(Hash[diff] == false)
{
printf("%04d - %04d = %04d\n",Max,Min,diff);
Hash[diff] = true;
N = diff;
}
else
break;
if(N == 0)
break;
}
return 0;
}1070
题意:已知每件物品的数量和总利润,现要买total数量的物品,最大的利润是多少。
思路:就是要求单价,然后按单价从大到小排,没什么难得,主要是物品数量不一定是整数,用int第三组数据会过不去,换成浮点型就好,被坑了。。
#include <iostream>
#include <cstdio>
#include <algorithm>
#include <cmath>
#include <string>
#include <cstring>
using namespace std;
const int Maxn = 1010;
struct mooncake
{
double amount;
double price;
bool operator < (const mooncake& x) const
{
return price * x.amount > amount * x.price;
}
};
mooncake moon[Maxn];
int main()
{
int N;
double total;
cin>>N>>total;
for(int i = 0;i < N;i ++)
cin>>moon[i].amount;
for(int i = 0;i < N;i ++)
cin>>moon[i].price;
sort(moon,moon + N);
int cnt = 0;
double ans = 0;
while(total > 0)
{
if(moon[cnt].amount <= total)
ans += moon[cnt].price;
else
ans += total * moon[cnt].price / moon[cnt].amount;
total -= moon[cnt++].amount;
if(cnt >= N) break;
}
printf("%.2lf\n",ans);
return 0;
}
//注意amount不一定是整数 1071
题意:给出一个字符串,求出字符串中重复次数最多的单词,如果有多个,按单词字典序输出。字符串大小写不敏感,最后将大写字符都转换为小写字符,并且只包含[a-z,0-9]的字符。
思路:将符合条件的单词筛出来就可以了。
#include <iostream>
#include <cstdio>
#include <algorithm>
#include <cmath>
#include <string>
#include <cstring>
#include <map>
using namespace std;
string str;
map<string,int> mp;
map<string,int>::iterator it;
int main()
{
int len;
getline(cin,str);
len = str.length();
for(int i = 0;i < len;i ++)
str[i] = tolower(str[i]);
int cnt = 0, Max = 0;
string s = "";
while(cnt < len)
{
while(cnt < len && (str[cnt] < '0' || (str[cnt] > '9' && str[cnt] < 'a') || str[cnt] > 'z'))
cnt++;
while(cnt < len && ((str[cnt] >= '0' && str[cnt] <='9') || (str[cnt] >= 'a' && str[cnt] <='z')))
s += str[cnt++];
if(s.length() > 0)
{
mp[s] ++;
Max = max(mp[s],Max);
}
s = "";
}
for(it = mp.begin();it != mp.end();it ++)
if(it->second == Max)
cout<<it->first<<" "<<it->second<<endl;
return 0;
}1072
1073
题意:将科学技术法表示的数还原成一般性表示的数。
思路:水题
#include <iostream>
#include <cstdio>
#include <cmath>
#include <algorithm>
#include <cstring>
#include <string>
#include <vector>
using namespace std;
int main()
{
string s;
cin>>s;
int p = s.find("E");
int Exp = 0;
for(int i = p + 2;i < s.length();i ++)
Exp = Exp * 10 + s[i] - '0';
if(s[0] == '-')
cout<<s[0];
if(s[p + 1] == '-')
{
cout<<"0.";
for(int i = 0;i < Exp - 1;i ++)
cout<<"0";
for(int i = 1;s[i] != 'E';i ++)
{
if(s[i] == '.') continue;
cout<<s[i];
}
cout<<endl;
}
else
{
int i = 3;
cout<<s[1];
while(Exp--)
{
if(i < p) cout<<s[i++];
else cout<<"0";
}
if(i < p)
{
cout<<".";
for(;i < p;i ++)
cout<<s[i];
}
cout<<endl;
}
return 0;
}
1074
题意:给出一个链表,要求每K个数旋转一次,求最后的链表。
思路:跟1052差不多,模拟一下就好,要注意的是给出的N个点不一定能刚好连成一条链,只需管能连成链的那些点就可以了。
#include <iostream>
#include <cstdio>
#include <algorithm>
#include <cmath>
#include <string>
#include <cstring>
using namespace std;
const int Maxn = 100010;
struct node
{
int from,val,next;
};
node Hash[Maxn],q[Maxn];
int main()
{
int start,N,K,from,val,next;
scanf("%d%d%d",&start,&N,&K);
for(int i = 0;i < N;i ++)
{
scanf("%d%d%d",&from,&val,&next);
Hash[from].from = from;
Hash[from].val = val;
Hash[from].next = next;
}
int cnt = 0;
while(start != -1)
{
q[cnt].from = start;
q[cnt].val = Hash[start].val;
q[cnt++].next = Hash[start].next;
start = Hash[start].next;
}
int i;
N = cnt;//给出的N个点不一定能全部连起来的
for(i = K - 1;i < N;i += K)
{
for(int j = 0;j < K;j ++)
{
printf("%05d %d ",q[i - j].from,q[i - j].val);
if(j == K - 1)
{
if(i + K < N) printf("%05d\n",q[i + K].from);
else
{
if(i + 1 == N) printf("-1\n");
else printf("%05d\n",q[i + 1].from);
}
}
else
printf("%05d\n",q[i - j - 1].from);
}
}
i = i - K + 1;
if(i < N)
{
for(;i < N;i ++)
{
printf("%05d %d ",q[i].from,q[i].val);
if(i + 1 == N)
printf("-1\n");
else
printf("%05d\n",q[i + 1].from);
}
}
return 0;
}1075
题意:模拟PAT做题问题。N个学生,K道题,M次提交,每次提价包括学生id,题目的id和得分(编译错误表示为-1),现要对学生最后成绩从大到小排序,若总分相同,按题目完全通过的个数降序排序,还相同,按id从小到大排序。对应没有提交过题目的人或者没有题目通过编译的人,则不参与排序,输出最后的排序结果。
思路:简单的排序,注意一些细节,比如同一道题提交满分的情况出现了好几次,perfectNum不要多加,不然影响排序,一开始wa在这里了,导致最后一组数据没有通过。还有N比较小,为节省空间可以hash一下id。
#include <iostream>
#include <cstdio>
#include <algorithm>
#include <cmath>
#include <string>
#include <cstring>
using namespace std;
const int Maxn = 10010;
struct person
{
int id;
int score[10];
int totalScore;
int perfectNum;
bool flag;
bool operator < (const person &x) const
{
if(totalScore != x.totalScore)
return totalScore > x.totalScore;
if(perfectNum != x.perfectNum)
return perfectNum > x.perfectNum;
return id < x.id;
}
};
person p[Maxn];
int score[10];
int Hash[Maxn * 10];
int main()
{
int N,K,M;
int id,x,y,cnt = 0;
memset(Hash,-1,sizeof(Hash));
scanf("%d%d%d",&N,&K,&M);
for(int i = 0;i < K;i ++)
scanf("%d",&score[i]);
for(int i = 0;i < M;i ++)
{
scanf("%d%d%d",&id,&x,&y);
if(Hash[id] == -1)
{
Hash[id] = cnt++;
for(int j = 0;j < K;j ++)
p[Hash[id]].score[j] = -2;
p[Hash[id]].perfectNum = 0;
p[Hash[id]].totalScore = 0;
}
p[Hash[id]].id = id;
if(p[Hash[id]].score[x - 1] == -2 || p[Hash[id]].score[x - 1] < y)
{
if(y >= 0)
{
p[Hash[id]].totalScore = p[Hash[id]].totalScore - ((p[Hash[id]].score[x - 1]) < 0?0:p[Hash[id]].score[x - 1]) + y;
p[Hash[id]].flag = true;
}
p[Hash[id]].score[x - 1] = y;
if(y == score[x - 1])//注意这里,若提交了好几次满分的,不要重复计算 p[Hash[id]].perfectNum,最后一组数据要注意这个问题
p[Hash[id]].perfectNum++;
}
}
sort(p,p + cnt);
int rank;
for(int i = 0;i < cnt;i ++)
{
if(p[i].flag == false) break;
if(i == 0 || p[i].totalScore != p[i - 1].totalScore)
{
printf("%d ",i + 1);
rank = i + 1;
}
else
printf("%d ",rank);
printf("%05d %d",p[i].id,p[i].totalScore);
for(int j = 0;j < K;j ++)
{
if(p[i].score[j] == -2)
printf(" -");
else
printf(" %d",p[i].score[j] < 0?0:p[i].score[j]);
}
printf("\n");
}
return 0;
} 1076
题意:模拟微博关注好友之间的转发。已知有N个人( N≤1000 ),每个人有自己的关注列表,关注M( M≤100 )个人及对应的id。从而形成一张社交网。现在给出K个询问,每个询问给出一个id,表示该用户发表了一条信息,那个最多经过L层用户关系,这条消息能被多少人看到。
思路:因为N,M的数据不是很大,所以用dfs就可以了。当然,要做些优化,比如题中的样例,用户6发出一条消息后,可以经过6-3-1-4,也可以6-3-4-5等等,对于4号用户来说,6-3-4-5这条路径更近,所以我用了个step来表示到该用户最短的距离,如果某条路径过来到x点的长度已经查过了step[x],那没必要在遍历x后面的点了。
#include <iostream>
#include <cstdio>
#include <cmath>
#include <algorithm>
#include <cstring>
#include <string>
#include <set>
#include <vector>
using namespace std;
const int Maxn = 1010;
set<int> se;
vector<int> vec[Maxn];
int step[Maxn];
int N,L;
void dfs(int n,int root,int cnt)
{
if(cnt >= L) return ;
for(int i = 0;i < vec[n].size();i ++)
{
if(vec[n][i] != root && (step[vec[n][i]] == 0 || cnt + 1 < step[vec[n][i]]))
{
se.insert(vec[n][i]);
step[vec[n][i]] = cnt + 1;
dfs(vec[n][i],root,cnt + 1);
}
}
}
int main()
{
int M,x;
scanf("%d%d",&N,&L);
for(int i = 1;i <= N;i ++)
{
scanf("%d",&M);
while(M--)
{
scanf("%d",&x);
vec[x].push_back(i);
}
}
scanf("%d",&M);
while(M--)
{
se.clear();
scanf("%d",&x);
dfs(x,x,0);
printf("%d\n",se.size());
for(int i = 1;i <= N;i ++)
step[i] = 0;
}
return 0;
}
1077
题意:给出N个字符串,求出这些字符串的公共后缀。
思路:题目要求不是很严格,字符串前后有多余空格的照输出就可以,所以比较简单。
#include <iostream>
#include <cstdio>
#include <cmath>
#include <algorithm>
#include <cstring>
#include <string>
using namespace std;
const int Maxn = 110;
string str[Maxn];
int len[Maxn];
int main()
{
int N,minLength = 300;
cin>>N;
getchar();
for(int i = 0;i < N;i ++)
{
getline(cin,str[i]);
len[i] = str[i].length();
minLength = min(minLength,len[i]);
}
string s = "";
for(int i = 1;i <= minLength;i ++)
{
char last = str[0][len[0] - i];
int j;
for(j = 1;j < N;j ++)
{
if(str[j][len[j] - i] != last)
break;
}
if(j == N)
s += last;
else
break;
}
if(s.length() == 0)
cout<<"nai"<<endl;
else
{
reverse(s.begin(),s.end());
cout<<s<<endl;
}
return 0;
}1078
题意:Hash表 ,二次探测
思路:主要部分,筛素数和二次探测。素数我是先筛出来并二分查找比给定值大的最小的素数。题目没有说清楚二次探测,应该是默认大家都知道二次探测,所以要看清题意。二次探测google之,这里只要探测正方向的数,负方向的不用探测。
#include <iostream>
#include <cstdio>
#include <cmath>
#include <algorithm>
#include <cstring>
#include <string>
using namespace std;
const int Maxn = 100010;
int flag[Maxn];
int prime[Maxn];
int cnt;
bool visit[Maxn];
void _init()
{
for(int i = 2;i < Maxn;i ++)
{
if(flag[i] == false)
{
prime[cnt++] = i;
for(int j = i * 2;j < Maxn;j += i)
flag[j] = true;
}
}
}
int binarySearch(int x)
{
int l = 0,r = cnt - 1;
int mid;
while(l <= r)
{
mid = (l + r)>> 1;
if( x <= prime[mid])
r = mid - 1;
else
l = mid + 1;
}
return prime[l];
}
int main()
{
_init();
int Msize,N,x,tmp;
scanf("%d%d",&Msize,&N);
Msize = binarySearch(Msize);
for(int i = 0;i < N;i ++)
{
scanf("%d",&x);
if(i != 0) printf(" ");
int cnt = 1;
bool f = false;
int num = Msize;
tmp = x = x % Msize;
while(num--) //二次探测最多探测Msize次,不然无意义了
{
if(visit[x % Msize] == false)
{
printf("%d",x % Msize);
visit[x % Msize] = true;
f = true;
break;
}
if(f) break;
x = tmp + cnt * cnt;
cnt ++;
}
if(!f)
printf("-");
}
printf("\n");
return 0;
}1079
题意:
思路:
1080
题意:模拟研究生根据成绩申请学校的过程。有N个学生,M所学校,每所学校有quota[i]的录取名额。现在每个学生有K个心仪的学校。首先根据学生成绩进行排序。考试成绩分为GE,GI两部分
1.按GE+GI最终得分降序排
2.总得分相同,按GE降序排
3.若总得分和GE都相同,那么这两个学生的排名就相同。
4.排好序后,根据学生心仪的学校以此录取,如果心仪的学校还有名额,则录取该学生。如果没有名额了,但是前一个录取的学生与当前的学生排名是相同的,那不管有没有超额,都要录取当前的学生。否则,不录取。
思路:还算简单的排序。就是要处理一下如果连个学生排名相同,申请同一所学校但是该学校名额超限这种情况。我用了一个flag[i]表示当前i学校最后一个录取的学生是谁。当名额超限时,如果现在有一个学生与最后一个录取的学生排名相同,那这个学生也得录取。注意这点就好了。
#include <iostream>
#include <cstdio>
#include <cmath>
#include <algorithm>
#include <cstring>
#include <string>
#include <vector>
using namespace std;
const int Maxn = 40010;
struct person
{
int id;
int rank;
int GE,GI;
int school[5];
bool operator < (const person& x) const
{
if(GE + GI != x.GE + x.GI)
return GE + GI > x.GE + x.GI;
return GE > x.GE;
}
};
person p[Maxn];
int quota[110];
int flag[110];//用来保存第i所学校最后一个录取的人是谁,如果当前遍历到的人与最后录取的人排名相同,那么当前的人也要加入该学校
vector<int> vec[110];
int main()
{
int N,M,K;
scanf("%d%d%d",&N,&M,&K);
for(int i = 0;i < M;i ++)
scanf("%d","a[i]);
for(int i = 0;i < N;i ++)
{
scanf("%d%d",&p[i].GE,&p[i].GI);
for(int j = 0;j < K;j ++)
scanf("%d",&p[i].school[j]);
p[i].id = i;
}
sort(p,p + N);
for(int i = 0; i < N;i ++)
{
if(i == 0 || p[i].GE + p[i].GI != p[i - 1].GE + p[i - 1].GI || p[i].GE != p[i - 1].GE)
p[i].rank = i;
else
p[i].rank = p[i - 1].rank;
for(int j = 0;j < K;j ++)
{
if(quota[p[i].school[j]] > 0)
{
vec[p[i].school[j]].push_back(p[i].id);
quota[p[i].school[j]] --;
flag[p[i].school[j]] = i;
break;
}
else if(p[flag[p[i].school[j]]].rank == p[i].rank)
{
vec[p[i].school[j]].push_back(p[i].id);
break;
}
}
}
for(int i = 0;i < M;i ++)
{
sort(vec[i].begin(),vec[i].end());
for(int j = 0;j < vec[i].size();j ++)
{
printf("%s%d",(j == 0)?"":" ",vec[i][j]);
}
printf("\n");
}
return 0;
} 1081
题意:给出N个分数,计算各个分数相加后的最终结果。
思路:题目不难,与1088类似,主要求一下gcd和lcm就好。给一些样例,帮忙分析:
1
-11/5
结果:-1/5
1
-0/12
结果:0
#include <iostream>
#include <cstdio>
#include <cmath>
#include <algorithm>
#include <cstring>
#include <string>
#include <vector>
using namespace std;
const int Maxn = 110;
typedef long long LL;
LL numerator[Maxn];
LL denominator[Maxn];
bool op[Maxn];
LL GCD(LL a,LL b)
{
if(b == 0) return a;
return GCD(b,a%b);
}
LL LCM(LL a,LL b)
{
LL gcd = GCD(a,b);
return a / gcd * b;
}
int main()
{
int N;
string s;
LL lcm = 1;
cin>>N;
for(int i = 0;i < N;i ++)
{
cin>>s;
int len = s.length(),j;
LL tmp = 0;
for(j = (s[0]== '-')?1:0;s[j] != '/';j ++)
{
tmp = tmp * 10 + s[j] - '0';
}
numerator[i] = tmp;
for(++j,tmp = 0;j < len;j ++)
{
tmp = tmp * 10 + s[j] - '0';
}
denominator[i] = tmp;
op[i] = (s[0]=='-')?true:false;
lcm = LCM(lcm,tmp);
}
LL num = 0;
for(int i = 0;i < N;i ++)
{
if(!op[i])
num += lcm / denominator[i] * numerator[i];
else
num -= lcm / denominator[i] * numerator[i];
}
if(num % lcm == 0)
{
cout<<num/lcm<<endl;
}
else
{
LL gcd = abs(GCD(num,lcm));
num /= gcd;
lcm /= gcd;
if(num > lcm)
cout<<(num/lcm)<<" "<<abs(num - (num / lcm) * lcm)<<"/"<<lcm<<endl;
else
cout<<(num - (num / lcm) * lcm)<<"/"<<lcm<<endl;
}
return 0;
}
1082
题意:
思路:
1083
题意:给出N个学生的信息,每个学生有姓名,id和成绩。给出成绩达标线[grade1,grade2],强成绩位于达标线之内的学生按成绩降序排列输出姓名和id号。
思路:这种题目出现过很多次了,我发现是PAT最常出现的题,简单的排序即可,题目中没有说明N的范围,试了一下,10^3都能过。
#include <iostream>
#include <cstdio>
#include <cmath>
#include <algorithm>
#include <string>
#include <cstring>
using namespace std;
const int Maxn = 100010;
struct person
{
char name[15];
char id[15];
int grade;
bool operator < (const person &x) const
{
return grade > x.grade;
}
};
person p[Maxn],q[Maxn];
int main()
{
int N,grade1,grade2,cnt = 0;
scanf("%d",&N);
for(int i = 0;i < N;i ++)
scanf("%s%s%d",p[i].name,p[i].id,&p[i].grade);
scanf("%d%d",&grade1,&grade2);
for(int i = 0;i< N;i ++)
{
if(p[i].grade >= grade1 && p[i].grade <= grade2)
q[cnt++] = p[i];
}
sort(q,q + cnt);
if(cnt == 0)
printf("NONE\n");
else
{
for(int i = 0;i < cnt;i ++)
printf("%s %s\n",q[i].name,q[i].id);
}
return 0;
}1084
题意:给出s1,s2,s1是原字符串,先要用键盘敲出s1,结果出现的是s2,求出那些键盘格子坏了。字符串中找回出现[a,z],[A,Z],[0-9],_ 输出若是字母都变成大写输出。
思路:水题
#include <iostream>
#include <cstdio>
#include <cmath>
#include <algorithm>
#include <string>
#include <cstring>
#include <vector>
using namespace std;
vector<char> vec;
int main()
{
string s1,s2;
int len1;
cin>>s1>>s2;
len1 = s1.length();
for(int i = 0,j = 0;i < len1;)
{
char tmp = s1[i];
if(s1[i] >= 'a' && s1[i] <= 'z')
s1[i] -= 32;
if(s2[i] >= 'a' && s2[i] <= 'z')
s2[i] -= 32;
if(s1[i] == s2[j])
i ++,j ++;
else
{
if(find(vec.begin(),vec.end(),s1[i]) == vec.end())
vec.push_back(s1[i]);
i ++;
}
}
for(int i = 0;i < vec.size();i ++)
cout<<vec[i];
cout<<endl;
return 0;
}1085
题意:给出一个长度为N的序列,从中找出一些数组成一个序列,要求序列中最大的值M和最小的值m与给定的p的关系满足 M≤m∗p ,求该序列中最多能保存多少个数。
思路:先将序列从大到小排序,从头遍历每个M,二分查找m。
#include <iostream>
#include <cstdio>
#include <cmath>
#include <algorithm>
#include <string>
#include <cstring>
#include <vector>
using namespace std;
const int Maxn = 100010;
int s[Maxn];
bool cmp(int x,int y)
{
return x > y;
}
int binarySearch(int l,int r,int k)
{
while(l <= r)
{
int mid = (l + r) / 2;
if(s[mid] >= k)
l = mid + 1;
else
r = mid - 1;
}
return r;
}
int main()
{
int N,p;
scanf("%d%d",&N,&p);
for(int i = 0;i < N;i ++)
scanf("%d",&s[i]);
sort(s,s + N,cmp);
int Max = 0,j = 1;
for(int i = 0;i < N;i ++)
{
j = binarySearch(j,N - 1,ceil(s[i] * 1.0 / p));
Max = max(Max,j - i + 1);
if(j >= N - 1)
break;
}
printf("%d\n",Max);
return 0;
}1086
题意:构建一颗二叉树,按先序遍历给出二叉树的节点,push x表示插入一个节点,pop,向上返回一层,构建出来树之后按后序遍历输出树的节点。
思路:构建二叉树即可。
#include <iostream>
#include <cstdio>
#include <cmath>
#include <algorithm>
#include <string>
#include <cstring>
using namespace std;
struct node
{
int val;
node *left,*right;
node(int x = 0)
{
val = x;
left = right = NULL;
}
};
int N,v,cnt = 0;
string s;
node* root = NULL;
node* buildTree(node* p)//构建二叉树
{
if(N <= 0) return p;
N--;
cin>>s;
if(s == "Push")
{
cin>>v;
p = new node(v);
p->left = buildTree(p->left);
p->right = buildTree(p->right);
}
return p;
}
void print(node *root)
{
if(root == NULL) return;
print(root->left);
print(root->right);
cout<<((cnt == 0)?"":" ")<<root->val;
cnt++;
}
int main()
{
cin>>N;
N = N + N;
cnt = 0;
root = buildTree(root);
print(root);
cout<<endl;
return 0;
}1087
题意:给出N( 2≤N≤200 )个城市,M条边和起始出发城市,每个城市由三个字母组成,并且有城市的happy值,终点是”ROM”城市。要求路径最短的走法。当最短路径有多条时,取路径happy值最大的,还相同时,求平均happy值最大的。保证最后有这样一条路径存在。
思路:这种题目碰到好像3,4次了,1018,1030都类似解法,都是可以用dijkstra解决的,PAT貌似比较喜欢出。
#include <iostream>
#include <cstdio>
#include <cmath>
#include <algorithm>
#include <string>
#include <cstring>
#include <vector>
#include <map>
using namespace std;
const int Maxn = 220;
const int Inf = 0x7fffffff;
struct node
{
int dis;
vector<vector<int> > vec;
};
map<string,int> mp;
map<int,string> reversemp;
node p[Maxn];
int dis[Maxn][Maxn],happy[Maxn];
bool flag[Maxn];
int N,e;
void dijkstra()
{
for(int i = 0;i < N;i ++)
{
int Min = Inf,k;
for(int j = 0;j < N;j ++)
if(flag[j] == false && p[j].dis < Min)
{
Min = p[j].dis;
k = j;
}
flag[k] = true;
for(int j = 0;j < N;j ++)
{
if(k == j) continue;
if(dis[k][j] != Inf && p[k].dis + dis[k][j] < p[j].dis)
{
p[j].dis = p[k].dis + dis[k][j];
p[j].vec.clear();
p[j].vec = p[k].vec;
for(int z = 0;z < p[j].vec.size();z ++)
p[j].vec[z].push_back(j);
}
else if(dis[k][j] != Inf && p[k].dis + dis[k][j] == p[j].dis)
{
for(int z = 0;z < p[k].vec.size();z ++)
{
vector<int> v = p[k].vec[z];
v.push_back(j);
p[j].vec.push_back(v);
}
}
}
}
cout<<p[e].vec.size()<<" "<<p[e].dis<<" ";
int total = 0,avg = 0,ans = 0;
for(int i = 0;i < p[e].vec.size();i ++)
{
int sum = 0;
for(int j = 0;j < p[e].vec[i].size();j ++)
sum += happy[p[e].vec[i][j]];
if(sum > total)
{
total = sum;
avg = total / (p[e].vec[i].size() - 1);
ans = i;
}
else if(sum / p[e].vec[i].size() > avg)
{
avg = sum / (p[e].vec[i].size() - 1);
ans = i;
}
}
cout<<total<<" "<<avg<<endl;
for(int i = 0;i < p[e].vec[ans].size();i ++)
{
if(i != 0) cout<<"->";
cout<<reversemp[p[e].vec[ans][i]];
}
cout<<endl;
}
int main()
{
int M,cnt = 1,d;
string x,y;
cin>>N>>M>>x;
for(int i = 0;i < N;i ++)
{
for(int j = 0;j < N;j ++)
{
if(i == j) dis[i][j] = 0;
else dis[i][j] = dis[j][i] = Inf;
}
}
if(x == "ROM") e = 0;
mp[x] = 0;
reversemp[0] = x;
for(int i = 1;i < N;i ++)
{
cin>>x>>happy[i];
mp[x] = cnt;
reversemp[cnt++] = x;
p[i].dis = Inf;
if(x == "ROM") e = i;
}
for(int i = 0;i < M;i ++)
{
cin>>x>>y>>d;
dis[mp[x]][mp[y]] = dis[mp[y]][mp[x]] = d;
}
p[0].dis = 0;
p[0].vec.push_back(vector<int>(1));
dijkstra();
return 0;
} 1088
题意:给出分子形式的两个数,要求+,-,*,/后的结果,按要求输出
思路:与1081类似,仔细一点就行,我觉得我的代码不够简洁。
#include <iostream>
#include <cstdio>
#include <cmath>
#include <algorithm>
#include <string>
#include <cstring>
using namespace std;
typedef long long LL;
LL GCD(LL x,LL y)
{
if(y == 0) return x;
return GCD(y,x%y);
}
void print(LL f,LL x,LL y)//输出格式
{
if(f == -1)
cout<<"(-";
if(x % y == 0)
cout<<x/y;
else
{
if(x > y)
cout<<(x/y)<<" "<<(x - (x / y) * y)<<"/"<<y;
else
cout<<x<<"/"<<y;
}
if(f == -1)
cout<<")";
}
void solved(string s1,LL &x,LL &y,LL &f)//根据字符串获得分子分母和符号
{
x = 0,y = 0,f = 1;
int i;
if(s1[0] == '-') f = -1;
for(i = (s1[0] == '-')?1:0;s1[i] != '/';i ++)
x = x * 10 + (s1[i] - '0');
for(++i;i < s1.length();i ++)
y = y * 10 + (s1[i] - '0');
if(x != 0 && y != 0)
{
LL gcd = GCD(abs(x),abs(y));
x /= gcd;
y /= gcd;
}
}
void getAns(char c,LL f1,LL x1,LL y1,LL f2,LL x2,LL y2)//最终结果
{
print(f1,x1,y1);
cout<<" "<<c<<" ";
print(f2,x2,y2);
cout<<" = ";
if(c == '/' && x2 == 0)
cout<<"Inf"<<endl;
else
{
LL x,y,f = 1;
if(c == '+')
{
x = f1 * x1 * y2 + f2 * x2 * y1;
y = y1 * y2;
}
else if(c == '-')
{
x = f1 * x1 * y2 - f2 * x2 * y1;
y = y1 * y2;
}
else if(c == '*')
{
x = f1 * f2 * x1 * x2;
y = y1 * y2;
}
else
{
x = f1 * x1 * y2;
y = f2 * x2 * y1;
if(y < 0) x = -x,y = -y;
}
if(x < 0) f = -1,x = -x;
if(x != 0)
{
LL gcd = GCD(x,y);
x /= gcd;
y /= gcd;
}
print(f,x,y);
cout<<endl;
}
}
int main()
{
string s1,s2;
LL x1,y1,f1,x2,y2,f2;
cin>>s1>>s2;
solved(s1,x1,y1,f1);
solved(s2,x2,y2,f2);
getAns('+',f1,x1,y1,f2,x2,y2);
getAns('-',f1,x1,y1,f2,x2,y2);
getAns('*',f1,x1,y1,f2,x2,y2);
getAns('/',f1,x1,y1,f2,x2,y2);
return 0;
}
1089
题意:给出一个原序列和一个经过几步变化的序列,现有两种操作,插入排序还“归并”排序(按2个数,4个数。。这样排),问变化的序列属于插入排序还是归并排序。
思路:按插入排序的算法模拟一下,如果某次得到的序列与给出的序列相同,则属于插入排序,否则就是归并排序。
#include <iostream>
#include <cstdio>
#include <algorithm>
#include <cmath>
#include <string>
#include <cstring>
using namespace std;
const int Maxn = 110;
int a[Maxn],b[Maxn],c[Maxn],N;
bool check()
{
for(int i = 0;i < N;i ++)
if(a[i] != b[i])
return false;
return true;
}
int main()
{
bool flag = false;
cin>>N;
for(int i = 0;i < N;i ++)
{
cin>>a[i];
c[i] = a[i];
}
for(int i = 0;i < N;i ++)
cin>>b[i];
for(int i = 1;i < N;i ++)
{
for(int j = i ;j >=0;j --)
{
if(a[j] < a[j - 1])
swap(a[j],a[j - 1]);
else
break;
}
if(check())//属于插入排序
{
flag = true;
cout<<"Insertion Sort"<<endl;
for(int j = i+1 ;j >=0;j --)
{
if(a[j] < a[j - 1])
swap(a[j],a[j - 1]);
else
break;
}
for(int j = 0;j < N;j ++)
{
if(j != 0) cout<<" ";
cout<<a[j];
}
cout<<endl;
break;
}
}
if(!flag)//属于归并排序
{
cout<<"Merge Sort"<<endl;
for(int i = 0;i < N;i ++)//原来a已经变掉了,返回一开始的a
a[i] = c[i];
for(int i = 1;i < N;i += i)
{
for(int z = 0; z < N;z += i * 2)
{
int j,k,minj,mink,cnt = 0;
minj = min(z + i,N);
mink = min(z + 2 * i,N);
for(j = z,k = j + i;j < minj && k < mink;)
{
if(a[j] < a[k])
c[cnt++] = a[j++];
else
c[cnt++] = a[k++];
}
if(j < minj)
{
for(;j < minj;j ++)
c[cnt++] = a[j];
}
if(k < mink)
{
for(;k <mink;k ++)
c[cnt++] = a[k];
}
for(j = 0;j < cnt;j ++)
a[z + j] = c[j];
}
if(flag)
{
for(int z = 0;z < N; z ++)
{
if(z != 0) cout<<" ";
cout<<a[z];
}
cout<<endl;
break;
}
if(check())
{
flag = true;
}
}
}
return 0;
}1090
题意:有向无环图,求从根节点到子节点最远的距离m,输出这种路径有几条,若有n条,再输出p*(1+r%)^m
思路:dfs一下,计算根节点到每个节点的距离,在统计最远距离就行。
#include <iostream>
#include <cstdio>
#include <algorithm>
#include <cmath>
#include <string>
#include <cstring>
#include <vector>
using namespace std;
const int Maxn = 100010;
vector<int> vec[Maxn];
int dis[Maxn];
void dfs(int x)
{
for(int i = 0;i < vec[x].size();i ++)
{
dis[vec[x][i]] = dis[x] + 1;
dfs(vec[x][i]);
}
}
int main()
{
int N,x,root;
double p,r;
cin>>N>>p>>r;
for(int i = 0;i < N;i ++)
{
cin>>x;
if(x == -1)
{
root = i;
dis[i] = 0;
}
else
vec[x].push_back(i);
}
dfs(root);
int cnt = 0,Max = 0;
for(int i = 0;i < N;i ++)
{
if(dis[i] > Max)
{
cnt = 1;
Max = dis[i];
}
else if(dis[i] == Max)
cnt ++;
}
printf("%.2lf %d\n",p*pow((1 + r / 100),Max),cnt);
return 0;
} 1091
题意:
思路:
1092
题意:给出字符串s1和s2,要求s1中拥有的字母是否能覆盖s2中拥有的,如果有,输出Yes和s1.length() - s2.length(),否则,输出No和不能覆盖的个数
思路:水题。hash一下就好
#include <iostream>
#include <cstdio>
#include <cmath>
#include <algorithm>
#include <string>
#include <cstring>
using namespace std;
int Hash[300];
int main()
{
string s1,s2;
int ans = 0;
int len;
cin>>s1>>s2;
len = s1.length();
for(int i = 0;i < len;i ++)
Hash[s1[i]] ++;
len = s2.length();
for(int i = 0;i < len;i ++)
{
if(Hash[s2[i]] > 0)
Hash[s2[i]] --;
else
ans ++;
}
if(ans == 0)
cout<<"Yes "<<s1.length() - s2.length()<<endl;
else
cout<<"No "<<ans<<endl;
return 0;
}1093
题意:字符串s只包含P,A,T三种字符,现要求s中出现PAT的情况有几种,例如APPAPT,出现2个PAT
思路:从后往前计算,T表示从当前位置到字符串结束出现了多少个’T’,A表示从当前位置到字符串结束出现了多少个’AT’,如果s[i] = ‘T’,T++;如果s[i] =’A’,A = A + T;
eg:
P A T A T
T: 2 2 2 1 1
A: 3 3 1 1 1
#include <iostream>
#include <cstdio>
#include <algorithm>
#include <cmath>
#include <string>
#include <cstring>
#include <vector>
using namespace std;
const int Mod = 1000000007;
int main()
{
string s;
cin>>s;
int A = 0,T = 0,ans =0;
for(int i = s.length() - 1;i >= 0;i --)
{
if(s[i] == 'T')
T++;
else if(s[i] == 'A')
A = (A + T) % Mod;
else
{
ans = (ans + A) % Mod;
if(ans < 0)
ans += Mod;
}
}
cout<<ans<<endl;
return 0;
}1094
题意:一棵树,要求那一层几点最多。
思路:dfs一下就可以了
#include <iostream>
#include <cstdio>
#include <algorithm>
#include <cmath>
#include <string>
#include <cstring>
#include <vector>
using namespace std;
const int Maxn = 110;
int num[Maxn],Max = 1,gen[Maxn],flr = 1;//gen:当前是第几层。num:当前层有几个数
vector<int> vec[Maxn];
void dfs(int x)
{
for(int i = 0;i < vec[x].size();i ++)
{
gen[vec[x][i]] = gen[x] + 1;
num[gen[x] + 1] ++;
if(num[gen[x] + 1] > Max)
{
Max = num[gen[x] + 1];
flr = gen[x] + 1;
}
dfs(vec[x][i]);
}
}
int main()
{
int N,M,x,k,y;
cin>>N>>M;
for(int i = 0;i < M;i ++)
{
cin>>x>>k;
while(k --)
{
cin>>y;
vec[x].push_back(y);
}
}
gen[1] = 1;
num[1] = 1;
dfs(1);
cout<<Max<<" "<<flr<<endl;
return 0;
}1095
题意:校园里停车,每次有个记录,车牌号,时间,进入/驶出(in/out)状态,只有in或只有out的那些数据都不算。有M次询问,每次给出一个时间,要求该时间及之前一共停了多少车,最后,把停车时间最长的车的车牌号输出,并输出最长的停车时间。
思路:模拟。
对于这种数据:
JH007BD 05:09:59 in
JH007BD 05:10:33 in
JH007BD 12:23:42 out
JH007BD 12:24:23 out
有效的时间是
JH007BD 05:10:33 in
JH007BD 12:23:42 out
#include <iostream>
#include <cstdio>
#include <vector>
#include <algorithm>
#include <cstring>
#include <string>
#include <map>
using namespace std;
const int Maxn = 10010;
struct node
{
string id;
string time;
string statue;
bool operator <(const node&x) const
{
return time < x.time;
}
};
node p[Maxn],q[Maxn];
map<string,string> mp;
map<string,string>::iterator it;
map<string,int> res;
int Max;
int num[Maxn];
int cal(string s)
{
return ((s[0] - '0') * 10 + s[1] - '0') * 3600 +
((s[3] - '0') * 10 + s[4] - '0') * 60 +
((s[6] - '0') * 10 + s[7] - '0');
}
int binarySearch(int l,int r, string k)//二分查找
{
while(l <= r)
{
int mid = l + (r - l) / 2;
if(q[mid].time <= k)
l = mid + 1;
else
r = mid - 1;
}
return r;
}
int main()
{
int N,M;
string t;
scanf("%d%d",&N,&M);
for(int i = 0;i < N;i ++)
{
cin>>p[i].id>>p[i].time>>p[i].statue;
}
sort(p,p + N);
int cnt = 0;
for(int i = 0;i < N;i ++)
{
if(p[i].statue[0] == 'i')//in,同一辆车多个in,覆盖,最后一次in为准
{
mp[p[i].id]= p[i].time;
}
else//out
{
it = mp.find(p[i].id);
if(it == mp.end())//只有out没有in,忽略
continue;
q[cnt].id = p[i].id;
q[cnt].time= mp[p[i].id];
q[cnt++].statue = "in";
q[cnt++] = p[i];
if(res.find(p[i].id) == res.end())
res[p[i].id] = cal(p[i].time) - cal(mp[p[i].id]);
else
res[p[i].id] += cal(p[i].time) - cal(mp[p[i].id]);
Max = max(Max,res[p[i].id]);
mp.erase(it);
}
}
N = cnt;
sort(q,q + N);//有效的数据,存在q中
num[0] = 1;
for(int i = 1;i < N;i ++)
{
if(q[i].statue[0] == 'i')
num[i] = num[i - 1] + 1;
else
num[i] = num[i - 1] - 1;
}
for(int i = 0;i < M;i ++)
{
cin>>t;
int pos = binarySearch(0, N - 1,t);
cout<<num[pos]<<endl;
}
for(map<string,int>::iterator iter = res.begin();iter != res.end();iter++)
{
if(iter->second == Max)
{
cout<<iter->first<<" ";
}
}
int hh = Max / 3600;
int mm = (Max - hh * 3600) / 60;
int ss = Max - hh * 3600 - mm * 60;
printf("%02d:%02d:%02d\n",hh,mm,ss);
return 0;
}1096
题意:给出N( 1<N<231 ),求出组成N的因子中连续因子数最大的是多少,有多个输出字典序最小的那个。例如630 = 3*5*6*7,连续的为5*6*7
思路:暴力一下,遍历1—sqrt(N),从当前遍历到的数开始一共能连续多少位。
#include <iostream>
#include <cstdio>
#include <algorithm>
#include <cmath>
#include <string>
#include <cstring>
#include <vector>
using namespace std;
int main()
{
int n,s = 1,Max = 0;
cin>>n;
for(int i = 2;i <= ceil(sqrt(n));i++)
{
if(n % i != 0)
continue;
int j;
int tmp = n;
for(j = i;j <= tmp;j ++)
{
if(tmp % j != 0) break;
tmp /= j;
}
if(j - i > Max)
{
Max = j - i;
s = i;
}
}
if(Max == 0)//输出本身,例如n=5
{
cout<<1<<endl<<n<<endl;
}
else
{
cout<<Max<<endl;
for(int i = s;i < s + Max;i ++)
{
if(i != s) cout<<"*";
cout<<i;
}
cout<<endl;
}
return 0;
} 1097
题意:给出一个链表,每个节点包括地址,val,和指向的下一个节点的地址。现在遍历这个链表,分离出出现重复值的节点(值为加绝对值之后的值,-15,15,出现15时15也是重复的)。输出去掉重复值后的链表以及由重复值组成的链表。
思路:此题类型也出现过至少3次了。。暴力ok
#include <iostream>
#include <cstdio>
#include <algorithm>
#include <cmath>
#include <string>
#include <cstring>
#include <vector>
using namespace std;
const int Maxn = 100010;
struct node
{
int val;
int next;
};
node p[Maxn];
vector<int> vec,oth;
bool flag[10010];
int main()
{
int s,x,N;
scanf("%d%d",&s,&N);
for(int i = 0;i < N;i ++)
{
scanf("%d",&x);
scanf("%d%d",&p[x].val,&p[x].next);
}
while(s != -1)
{
if(flag[abs(p[s].val)])
{
oth.push_back(s);
}
else
{
flag[abs(p[s].val)] = true;
vec.push_back(s);
}
s = p[s].next;
}
for(int i = 0;i < vec.size();i ++)
{
printf("%05d %d ",vec[i],p[vec[i]].val);
if(i == vec.size() - 1)
printf("-1\n");
else
printf("%05d\n",vec[i + 1]);
}
for(int i = 0;i < oth.size();i ++)
{
printf("%05d %d ",oth[i],p[oth[i]].val);
if(i == oth.size() - 1)
printf("-1\n");
else
printf("%05d\n",oth[i + 1]);
}
return 0;
} 1098
题意:
思路:
1099
题意:给出N个节点的信息,每个节点包括当前节点的index和左右节点的index,构建一棵二叉搜索树,将给出的序列值放入相应的位置。
思路:建树,中序遍历来填充当前位置所对应的值。
#include <iostream>
#include <cstdio>
#include <vector>
#include <algorithm>
using namespace std;
const int Maxn = 110;
int a[Maxn];
int b[Maxn][2];
int g[Maxn];
int cnt = 0;
vector<int> vec;
void getRank(int n)
{
if(n == -1) return ;
getRank(b[n][0]);
g[n] = ++cnt;
getRank(b[n][1]);
}
int main()
{
int N;
cin>>N;
for(int i = 0;i < N;i++)
cin>>b[i][0]>>b[i][1];
for(int i = 0;i < N;i++)
cin>>a[i];
sort(a,a+N);
getRank(0);
vec.push_back(0);
while(!vec.empty())
{
int tmp = vec[0];
vec.erase(vec.begin());
if(b[tmp][0] != -1)
vec.push_back(b[tmp][0]);
if(b[tmp][1] != -1)
vec.push_back(b[tmp][1]);
if(tmp != 0) cout<<" ";
cout<<a[g[tmp]-1];
}
cout<<endl;
return 0;
}1100
题意:火星文与地球文之间的转化。地球上的数字为十进制,火星上的数字为13进制,并且各位数都有相应的文字表达,若给出十进制数,首先转化为13进制数,再写出相关的表达,若给出的火星文,转化成十进制数输出。
思路:就是进制间的转化,而且数值不大,直接计算就好。
#include <iostream>
#include <cstdio>
#include <vector>
#include <algorithm>
#include <cstring>
#include <string>
#include <map>
using namespace std;
string high[15]= {"","tam", "hel", "maa", "huh", "tou", "kes", "hei", "elo", "syy", "lok", "mer", "jou"};
string low[15] = {"tret","jan", "feb", "mar", "apr", "may", "jun", "jly", "aug", "sep", "oct", "nov", "dec"};
map<string,int> mp;
void _init()
{
for(int i = 0;i < 13;i ++)
mp[low[i]] = i;
for(int i = 1;i < 13;i ++)
mp[high[i]] = i * 13;
}
int main()
{
_init();
int N;
string str;
cin>>N;
getchar();
for(int i = 0;i < N;i ++)
{
getline(cin,str);
if(str[0] >= '0' && str[0] <= '9')
{
int val = 0,h,l;
for(int j = 0;j < str.length();j ++)
val = val * 10 + str[j] - '0';
h = val / 13;
l = val % 13;
if(h > 0)
{
cout<<high[h];
if(l > 0)
cout<<" "<<low[l];
cout<<endl;
}
else
{
cout<<low[l]<<endl;
}
}
else
{
int val = 0;
int p = str.find(' ');
if(p == -1)
{
cout<<mp[str]<<endl;
}
else
{
cout<<mp[str.substr(0,p)] + mp[str.substr(p + 1,str.length())]<<endl;
}
}
}
return 0;
}