GCC-3.4.6源代码学习笔记(142)
5.12.5.2.2.2.1.3.12. 完成派生类RECORD_TYPE – 生成VTT
虚表表( VTT )对于类来说不是必需的,因此下面的 build_vtt 可能生成 VTT ,有可能不产生。注意下面 5188 行的 dump_class_hierarchy ,选项“ –fdump-class-hierarchy ”会促使该函数转储我们前一个看到的内容。
finish_struct_1 (continue)
5174 /* Build the VTT for T. */
5175 build_vtt (t);
5176
5177 if (warn_nonvdtor && TYPE_POLYMORPHIC_P (t) && TYPE_HAS_DESTRUCTOR (t)
5178 && DECL_VINDEX (TREE_VEC_ELT (CLASSTYPE_METHOD_VEC (t), 1)) == NULL_TREE)
5179 warning ("`%#T' has virtual functions but non-virtual destructor", t);
5180
5181 complete_vars (t);
5182
5183 if (warn_overloaded_virtual )
5184 warn_hidden (t);
5185
5186 maybe_suppress_debug_info (t);
5187
5188 dump_class_hierarchy (t);
5189
5190 /* Finish debugging output for this type. */
5191 rest_of_type_compilation (t, ! LOCAL_CLASS_P (t));
5192 }
对于包含虚拟基类的类,上面构建的 vtable 还不是最终成品。它需要虚表表来代替虚表。一个 VTT 包含了:
1. 主虚指针,用于最后派生类( the most derived class )完整对象。
2. 次要 VTT ,用于每个要求 VTT 的最后派生类的直接非虚拟基类( direct non-virtual base )。
3. 次要虚指针,用于包含虚拟基类的最后派生类的直接或间接基类,或在虚拟派生路径上的基类。
4. 次要 VTT ,用于每个最后派生类的直接或间接虚拟基类。
次要 VTT 类似于完整对象的 VTT ,除了没有第四部分。
关于 VTT 及派生类布局, 这里 有一个相当好的笔记,摘录如下(原文是英文)
基础:单继承正如我们在关于类的讨论,单继承引致一个基类数据布置在在派生类数据之前的对象布局。因此如果类 A 及 B 有如此定义: class A { public : int a; }; class B : public A { public : int b; }; 那么类型的对象被布局成这样(其中“ b ”是一个指向这样一个对象的指针):
如果我们有虚函数: class A { public : int a; virtual void v(); }; class B : public A { public : int b; }; 那么我们还将有一个 vtable 指针:
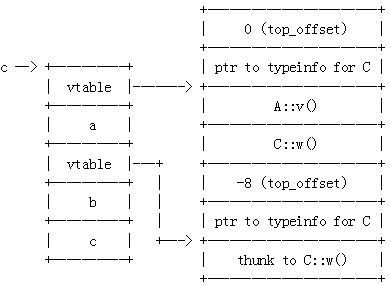
也就是说, top_offset 及 typeinfo 指针位于 vtable 指针指向位置的上方。 简单的多继承现在考虑多继承: class A { public : int a; virtual void v(); }; class B { public : int b; virtual void w(); }; class C : public A, public B { public : int c; }; 在这个情形下,类型 C 的对象被布置成如下: .. 但是为什么? 为什么有两个 vtable ?好吧,考虑类型替代。如果我有一个指向 C 的指针,我可以把它传给一个期望一个指向 A 的指针的函数,或一个期望指向 B 的指针的函数。如果一个函数期望一个指向 A 的指针,并且我想向它传递我的变量 c (指向 C 的类型)的值,我已经设置好了。对 A::v() 的调用可以通过(第一个) vtable 实现,并且被调用的函数可以通过我传入的指针访问成员,与通过指向 A 的指针那样。 不过,如果我向一个期望指向 B 的指针的函数传入我的指向 c 的指针变量的值,为了引用它,我们也需要在我们的 C 里有一个类型 B 的子对象。这就是为什么我们具有第二个 vtable 指针。我们可以向期望指向 B 的指针的函数传入该指针的值( c + 8 bytes ),并且它是所需的设置:它可以通过这个(第二个) vtable 指针进行调用 B::w() ,并且访问通过我们传入的指针访问成员 b ,与通过指向 B 的指针那样。 注意到被调用函数也需要这个“指针更正“( pointer-correction )。类 C 继承类 B::w() 属于这个情况。当通过指向 C 的指针调用 w() 时,这个指针(在 w() 内部它变成 this 指针)需要调整。这通常称作 this 指针调整。 在某些情况下,编译器将参数一个 thunk 来修正这个地址。考虑象上面那样的代码,不过这次 C 重载了 B 的成员函数 w() : class A { public : int a; virtual void v(); }; class B { public : int b; virtual void w(); }; class C : public A, public B { public : int c; void w(); }; C 的对象布局及 vtable 现在看起来象这样:
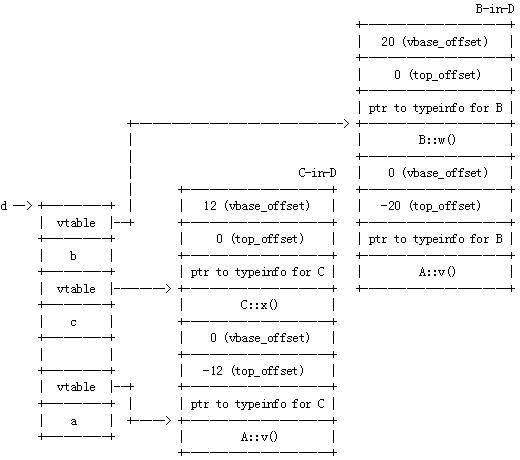
现在,当通过指向 B 的指针在一个 C 实例上调用 w() 时,这个 thunk 被调用。这个 thunk 起什么作用呢?让我们反汇编它(这里,用 gdb ): 0x0804860c <_ZThn8_N1C1wEv+0>: addl $0xfffffff8,0x4(%esp) 0x08048611 <_ZThn8_N1C1wEv+5>: jmp 0x804853c <_ZN1C1wEv> 那么它仅调整这个 this 指针并跳到 C::w() 。一切都没问题。 但上面不是意味着 B 的 vtable 总是指向这个 C::w() thunk 吗?我是说,如果我们有一个 B 的指针指向 B (而不是 C ),我们不想调用这个 thunk ,对吧? 对的。上面 C 中嵌入的用于 B 的 vtable 是特定于这个 C 中的 B 的情况。 B 的正常 vtable 是通常形式的,并且直接指向 B::w() 。 菱形层次:基类的多个拷贝(非虚拟继承)OK 。现在要解决真正麻烦的东西。回忆当形成继承菱形时,基类多个拷贝通常遇到的问题: class A { public : int a; virtual void v(); }; class B : public A { public : int b; virtual void w(); }; class C : public A { public : int c; virtual void x(); }; class D : public B, public C { public : int d; virtual void y(); };
注意到 D 从 B 及 C 继承。而 B 及 C 都从 A 继承。这意味着 D 具有 A 的两个 拷贝。对象的布局及嵌入的 vtable ,我们可以依据前一节推导出:
显然,我们期望 A 的数据(成员 a )在 D 的对象布局中出现两次(它就是如此),并且我们期望 A 的虚拟成员函数在 vtable 表示两次( A::v() 确实如此)。 OK ,这里没有什么新玩意。 菱形层次:虚拟基类的单个拷贝但是如果我们虚拟继承会怎样呢? C++ 的虚拟继承允许我们指定一个菱形的层次,但要保证虚拟继承的基类仅有一份拷贝。因此让我们按这样的方式写代码: class A { public : int a; virtual void v(); }; class B : public virtual A { public : int b; virtual void w(); }; class C : public virtual A { public : int c; virtual void x(); }; class D : public B, public C { public : int d; virtual void y(); }; 一下子事情变得复杂多了。如果我们可以在我们的 D 的表达中仅拥有 A 的一份拷贝,那么我们可以不再依赖我们的“小技巧”把 C 嵌入到一个 D 中(并且在 D 的 vtable 中嵌入一个用于 D 的 C 部分的 vtable )。不过如果我们不能做到这一点,我们怎样可以处理普通的类型替代呢? 让我们尝试把布局画出来: OK 。你看到 A 现在嵌入在 D 中,基本上就像其它基类那样。不过它被嵌入在 D 中,而不是在它的直接派生类中。 多继承情况下的构造与析构当上面的对象被构造时,对象如何在内存中被构造?并且我们如何确保构造函数在一个部分构造的对象(及它的 vtable )上的操作是安全的? 幸运的是,这些都得到了非常小心的处理。比如说我们正在构建类型 D 的一个新对象(通过比如, new D )。首先,用于该对象的内存在堆上分配并且返回一个指针。 D 的构造函数被调用,但在执行任何 D 特定的构造前,在对象上调用 A 的构造函数(当然,在调整了 this 指针之后)。 A 的构造函数填充类 D 对象的 A 部分,就像它是 A 的一个实例。 控制权交还给 D 的构造函数,它调用 B 的构造函数( 在这里指针调整是不需要的)。当 B 的构造函数做完后,该对象看起来就像这样:
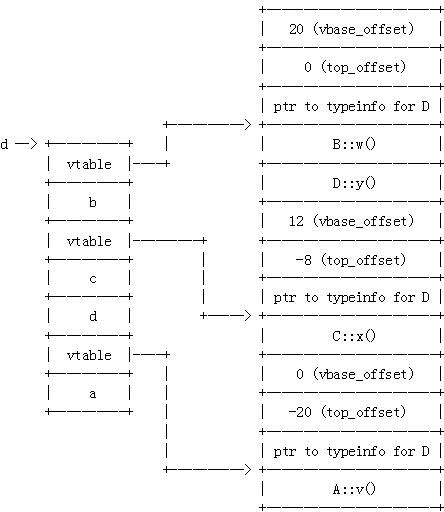
但等一下 ... B 的构造函数修改了该对象中的 A 部分,它改变 A 的 vtable 指针!怎么能把这种的 B-in-D 与其他中的 B (或者一个单独的 B )区分开来呢?简单。虚表表告诉它这样做。这个结构,缩写为 VTT ,是一个 vtable 的表,在构造中使用。在我们的案例中,用于 D 的 VTT 看起来就像这样: D 的构造函数把 D 的 VTT 中的一个指针传入 B 的构造函数(在这种情况下,它传入了第一个 B-in-D 项的地址)。确实,这个用于具有上面布局的对象的 vtable 是仅用于构造这个 B-in-D 的特殊 vtable 。 控制权返回给 D 的构造函数,接着它调用 C 的构造函数(连同一个指向 VTT 项“ C-in-D+12 ”地址的参数)。当 C 的构造函数完成时,该对象看起来就像这样:
正如你所见, C 的构造函数再一次修改了嵌入的 A 的 vtable 指针。这个嵌入的 C 及 A 对象现在使用这个 C-in-D vtable 的特殊构造,并且嵌入的 B 对象使用这个 B-in-D vtable 的特殊构造。最后, D 的构造函数完成了这个工作,我们得到与之前相同的图:
析构函数以相同的方式但反序执行。 D 的析构函数被调用。用户的析构代码运行后,该析构函数调用 C 的析构函数,并且指导它使用 D 的 VTT 的相关部分。 C 的析构函数,以在构造过程中相同的方式,操纵这个 vtable 指针;就是说,这个 vtable 指针现在指向 C-in-D 的构造 vtable ( construction vtable )。然后运行用户的用于 C 的析构代码,并且把控制权返回给 D 的析构函数,它接着调用 B 的析构函数连同 D 中的 VTT 的一个引用。 B 的析构函数设置对象的相关部分来引用 B-in-D 的构造 vtable ( construction vtable )。运行用户用于 B 的析构代码,并且把控制权返回给 D 的析构函数,它最后调用 A 的析构函数。 A 的析构函数改变用于对象 A 部分的 vtable 来引用用于 A 的 vtable 。最后,控制权返回给 D 的析构函数,对象的析构完成。曾用于该对象的内存返回给系统。 现在,事实上,事情还要更复杂些。你是否曾经看到那些“ in-charge ”及“ not-in-charge ”规格的构造函数及析构函数,在 GCC 产生的警告及错误消息或 GCC 生成的 2 进制文件中?是的,事实是可以有 2 个构造函数的实现,以及多达 3 个的析构函数的实现。 一个“ in-charge ”(或者完整对象)构造函数是会构造虚拟基类的,而一个“ not-in-charge ”(或基类对象)构造函数则不会。考虑我们上面的例子。如果一个 B 被构造,它的构造函数需要调用 A 的构造函数来。类似的, C 的构造函数需要构造 A 。然而,如果 B 及 C 作为 D 的一个构造的一部分来构造,它们的构造函数不应该构造 A ,因为 A 是一个虚拟基类,并且 D 的构造函数将担负起在 D 的实例中仅构造它一次的责任。考虑这些情况: · 如果你执行“ new A ”, A 的“ in-charge ”构造函数被调用来构造 A 。 · 当你执行“ new B ”, B 的“ in-charge ”构造函数被调用。它将调用 A 的“ not-in-charge ”构造函数。 · “ new C ”类似于“ new B ”。 · “ new D ”调用 D 的“ in-charge ”构造函数。我们浏览这个例子。 D 的“ in-charge ”构造函数调用 A , B 及 C 的 “ not-in-charge ”版本的构造函数(以这个次序)。 一个“ in-charge ”析构函数类似于一个“ in-charge ”构造函数——它负责析构虚拟基类。类似的,有“ not-in-charge ”析构函数产生。但这里还有第三个。一个“ in-charge deleting ”析构函数除了析构对象之外,还负责回收内存。那么什么时候其中一个会被选中使用呢? 首先,有两类对象可以被析构——在栈上分配的,及在堆上分配的。考虑这个代码(假设使用之前我们具有虚拟继承的菱形派生结构): D d; // 在栈上分配一个 D 并构造它 D *pd = new D; // 在堆上分配一个 D 并构造它 /* ... */ delete pd; // 为 D 调用“ in-charge deleting ”析构函数 return ; // 为栈分配的 D 调用“ in-charge ”析构函数 我们看到实际的 delete 操作符没有由执行删除的代码来调用,而是由用于要被删除对象的“ in-charge deleting ”析构函数来调用。为什么要这样做?为什么不让这个调用者调用“ in-charge ”析构函数,然后删除这个对象呢?那样你只需要析构函数的 2 个实现,而不是 3 个 ... 是的,编译器可以这样做,不过出于其他原因事情会更复杂。考虑这个代码(假设一个虚析构函数,你总是这样用,对吧? ... 对?!?): D *pd = new D; // 在堆上分配一个 D 并构造它 C *pc = d; // 我们有一个 C 的指针指向我们堆上分配的 D /* ... */ delete pc; // 通过 vtable 调用析构函数的 thunk ,但对于删除? 如果你没有 D 的析构函数的一个“ in-charge deleting ”形式,那么删除操作将需要调整指针,就像这个析构函数 thunk 做的那样。记住, C 对象嵌入在一个 D 里,因此我们上面的 C 指针被调整指向我们 D 对象的内部。我们不能就这样删除这个指针,因为它不是那个当我们构造 D 时由 malloc() 返回的指针。 因此,如果我们没有一个“ in-charge deleting ”析构函数,我们不得不对删除操作符使用 thunk (并把它们保存在我们的 vtable 中),或其他类似的东西。 多继承,一边具有虚函数OK 。最后一个练习。如果我们有一个具有虚拟继承的菱形继承层次,就像之前那样,但仅在一边有虚函数,会怎样呢?这样: class A { public : int a; }; class B : public virtual A { public : int b; virtual void w(); }; class C : public virtual A { public : int c; }; class D : public B, public C { public : int d; virtual void y(); }; 在这个情形下对象的布局如下:
你可以看到 C 子对象,它没有虚函数,但仍然有一个 vtable (尽管是空的)。事实上,所有 C 的实例都有一个空的 vtable 。 |