隐马尔科夫模型(HMM)
-
- 基本概念
- 1Markov Models
- 2Hidden Markov Models
- 3概率计算算法前向后向算法
- 1-3-1直接计算
- 1-3-2前向算法
- 1-3-3后向算法
- 4学习问题Baum-Welch算法也就是EM算法
- 5预测算法
- 基本概念
基本概念
1.1Markov Models
处理顺序数据的最简单的方式是忽略顺序的性质,将观测看做独立同分布,然而这样无法利用观测之间的相关性。例如:预测下明天是否会下雨,所有数据看成独立同分布只能得到雨天的相对频率,而实际中,我们知道天气会呈现持续若干天的趋势,观测今天是否下雨对预测明天是否下雨有很大帮助。引入马尔科夫模型(Markov Models)。
1)假设只与最近的一次观测有关,而独立于其他所有之前的观测,那么我们就得到了 一阶马尔科夫链(first-order Markov chain):
观测 xn 的一阶马尔科夫链,其中,特定的观测 xn 的条件概率分布 p(xn|xn−1) 只以前一次观测 xn−1 为条件。
2)允许预测除了与当前观测有关以外,还与当前观测的前一次观测有关,那么我们就得到了二阶马尔科夫链:

二阶马尔科夫链,其中特定的观测 xn 依赖于前两次观测 xn−1 和 xn−2 的值
3)一阶马尔科夫链中的条件概率分布 p(xn|xn−1) 由K -1个参数指定,每个参数都对应于 xn−1 的K个状态,因此参数的总数为K(K -1)。
M阶,则有参数个数 km(k−1) (M指数增长!!)
如何构造任意阶数的不受马尔科夫假设限制的序列模型,同时能够使用较少数量的参数确定??
对于每个观测 xn ,我们引入一个对应的潜在变量 zn (类型或维度可能与观测变量不同)。假设潜在变量构成了马尔科夫链,得到的图结构被称为状态空间模型(state space model):
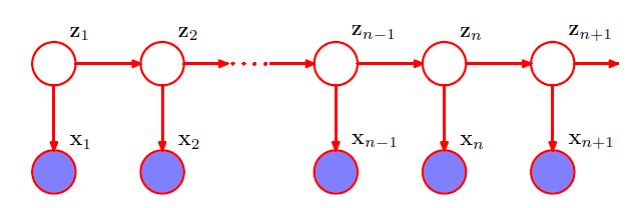
隐马尔科夫模型可以被看成上图所示的状态空间模型的一个具体实例,其中潜在变量是离散的。
1.2Hidden Markov Models
定义:
隐马尔可夫模型是关于时序的概率模型,描述由一个隐藏的马儿可夫链随机生成不可观察的状态随机序列,再由各个状态生成一个观测而产生随机序列的过程。
- 状态序列:隐藏的马尔可夫链随机生成的状态序列,称为状态序列(state sequence);
- 观测序列:每个状态生成一个观测,而由此产生的观测的随机序列,称为观测序列(observation sequence)。
- 时刻:序列的每一个位置又看作是一个时刻。
设
Q:所有可能的状态的集合 Q={q1,q2,...q,N} ;N是可能的状态数
V:所有可能的观测的集合 V={v1v2,...,vn} ;M是可能的观测数
I:长度为T的状态序列 I=(i1,...,iT)
O:对应的观测序列 O=(o1,oT)
A:状态转移概率矩阵 A=[aij]NXN ;其中 aij=p(it+1=qj|it=qi) ,i=1,2,…,N;j=1,2,…N;
在时刻t处于状态 qi 的条件下在时刻t+1转移到状态 qj 的概率。
B:观测概率矩阵 B=[bj(k)]NXN ;其中 bj(k)=p(ot=vk|it=qj) ,k=1,2,…M; j=1,2,…N;
是在时刻t处于状态 qj 的条件下生产观测 vk 的概率
π:初始状态概率向量 π=(πi) ,其中, πi=p(i1=qi) ,i=1,2,…N
是时刻t=1处于状态 qi 的概率。
隐马尔可夫模型由初始状态概率向量π、状态转移概率矩阵A和观测概率矩阵B决定,λ=(A,B,π)
下图是一个三个状态的隐马尔可夫模型状态转移图,其中x 表示隐含状态,y 表示可观察的输出,a 表示状态转换概率,b 表示输出概率。
下图显示了天气的例子中隐藏的状态和可以观察到的状态之间的关系。我们假设隐藏的状态是一个简单的一阶马尔科夫过程,并且他们两两之间都可以相互转换。
状态转移矩阵来表示,其表示形式如下:

对该矩阵有如下约束条件:
隐马尔可夫模型有3个基本问题:
(1)概率计算问题.给定模型λ=(A,B,π)和观测序列 O=(o1,...,oT) ,计算在模型λ下观测序列O出现的概率P(O|λ)。 前向后向算法
(2)学习问题.己知观测序列 O=(o1,...,oT) ,估计模型λ=(A,B,π)参数,使得在该模型下观测序列概率P(O|λ)最大。即用极大似然估计的方法估计参数 。Baum-Welch算法(EM算法)
(3)预测问题,也称为解码(decoding)问题.己知模型λ=(A,B,π)和观测序列 O=(o1,oT) ,求对给定观测序列条件概率P(O|λ)最大的状态序列 I=(i1,...,iT) ,即给定观测序列,求最有可能的对应的状态序列。 维特比算法(Viterbi)
下面将逐一介绍这些基本问题的解法.
1.3概率计算算法(前向后向算法!!)
1-3-1直接计算
给定模型λ=(A,B,π)和观测序列 O=(o1,oT) ,计算观测序列0出现的概率P(O|λ)。最直接的方法是按概率公式直接计算。通过列举所有可能的长度为T的状态序列 I=(i1,...,iT) ,求各个状态序列I与观测序列 O=(o1,oT) 的联合概率P(O,I|λ),然后对所有可能的状态序列求和,得到P(O|λ)。
状态序列 I=(i1,...,iT) 的概率是
P(I│λ)=πi1ai1i2ai2i3...aiT−1iT
对固定的状态序列 I=(i1,...,iT) ,观测序列 O=(o1,oT) 的概率是
P(O,I|λ), P(O│I,λ)=bi1(o1)bi2(o2)...biT(oT)
O和I同时出现的联合概率为
P(O,I│λ)=P(O│I,λ)P(I│λ)=πi1bi1(o1)ai1i2bi2(o2)...aiT−1iTbiT(oT)
然后,对所有可能的状态序列I求和,得到观测序列O的概率P(O|λ),即
P(O│λ)=∑Ip(o|I,λ)p(I|λ)=∑i1i2...iTπi1bi1(o1)ai1i2bi2(o2)...aiT−1iTbiT(oT)
但是,利用上述公式计算量很大,是 O(TNT) 阶的,这种算法不可行。
下面介绍计算观测序列概率P(O|λ)的有效算法:前向一后向算法(forward-backward algorithm)
1-3-2前向算法
首先定义前向概率.
定义(前向概率):给定隐马尔可夫模型λ,定义到时刻t部分观侧序列为 o1,…,ot 且状态为 qi 的概率为前向概率,记作
at(i)=p(o1,...ot,t=qi|λ)
可以递推地求得前向概率 at(i) 及观测序列概率P(O|λ)
算法:(观测序列概率的前向算法)
输入:隐马尔可夫模型λ,观测序列O
输出:观测序列概率P(O|λ)
(1)初始化前向概率, a1(i)=πibi(o1) ,i=1,…,N
(2)递推,对t=1,…T-1,

(3)终止,
(1)是初始时刻的状态 i1=qi 和观测 o1 的联合概率
(2)计算到时刻t+1部分观测序列为 o1,…ot,ot+1 且在时刻t+1处于状态 qi 的前向概率。
公式方括弧里,既然 at(j) 是到时刻t观测到 o1,…ot 并在时刻t处于状态 qj 的前向概率,那么乘积 at(j)aji 就是到时刻t观测到 o1,…ot 并在时刻t处于状态 qj ,而在时刻t+1到达状态 qi 的联合概率.
对这个乘积在时刻t的所有可能的N个状态 qj 求和,其结果就是到时刻t观测为 o1,…ot 并在时刻t+I处于状态 qi 的联合概率.
方括弧里的值与观测概率 bi(ot+1) 的乘积恰好是到时刻t+1观测到 o1,...,ot,ot+1 并在时刻t+1处于状态 qi 的前向概率 at+1(i) .
步骤(3)给出P(O|λ)的计算公式.因为
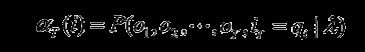
所以
1-3-3后向算法
定义 (后向概率):给定隐马尔可夫模型λ,定义在时刻t状态为 qi 的条件下,从t+1到T的部分观测序列为 oi+1,oi+2,...,oT 的概率为后向概率,记作
![]()
用递推的方法求得后向概率 βt(i) 及观测序列概率P(O|λ).
算法:(观测序列概率的后向算法)
输入:隐马尔可夫模型λ,观测序列O
输出:观测序列概率P(O|λ)
(1) βT(i) =1 i=1,2,….,N
(2)对t=T-1,T-2,…,1
(3)
利用前向概率和后向概率的定义可以将观测序列概率P(O|λ)统一写成:
1.4学习问题[Baum-Welch算法(也就是EM算法)]
给定输出序列O=O1O2…..OT,学习模型参数λ=(A,B,π),其中状态序列数据是不可观测的隐数据I,隐马尔可夫模型变成一个含有隐变量的概率模型。参数学习可由EM算法实现。
给定模型λ和观测O,在时刻t处于状态 qi 且在时刻t+1处于状态 qj 的概率,记

给定模型λ和观测O,在t时刻处于状态 qi 的概率,记

算法:(Baum-Welch算法)
输入:观测数据 O=(q1,...oT) ;
输出:隐马尔可夫模型参数
(1)初始化,随机选定参数 a(0)ij,bj(k)(0),π(0)i , 得到模型 λ(0)=(A(0),B(0),π(0))
(2)EM计算:
E步骤:根据式1和式2计算期望 ξt(ij) 和 γt(i)
M步骤:根据期望 ξt(ij) 和 γt(i) ,带入下来各式中重新得到 πi,aij,bj(k) ,得到新的模型 λ(n)

(3)循环计算:n=n+1,直到 πi,aij,bj(k) 收敛。
1.5预测算法
维特比算法(Viterbi algorithm)
维特比算法实际是用动态规划解隐马尔可夫模型预侧问题,即用动态规划(dynamic programming)求概率最大路径(最优路径).这时一条路径对应着一个状态序列.
给定观测序列O=O1O2…OT,和模型λ=(A,B,π),找出“最优”的状态序列q1q2…qT,使得该状态最好地解释观测序列。

从时刻t=1开始,递推地计算在时刻t状态为i的各条部分路径的最大概率,直至得到时刻t=T状态为i的各条路径的最大概率.时刻t=T的最大概率即为最优路径的概率 p∗
最优路径的终结点 i∗T 也同时得到.之后,为了找出最优路径的各个结点,从终结点 i∗T 开始,由后向前逐步求得结点 i∗T−1 ,…, i∗1 .得到最优路径 I∗=i∗1,...,i∗T) 这就是维特比算法.
首先导入两个变量δ和ψ.定义在时刻t状态为i的所有单个路径 i1,...it 中概率最大值为 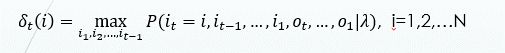
由定义可得变量δ的递推公式:
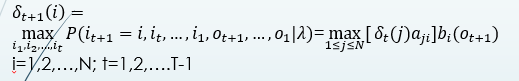
定义在时刻t状态为i的所有单个路径 ![]() 中概率最大的路径的第t-1个(前一个状态)结点为
中概率最大的路径的第t-1个(前一个状态)结点为
上图中,对于从t时刻三个到 t+1时刻的状态1,到底取状态1,2还是3,不是看单独状态1,2还是3的概率,而是看在状态1,2,3各自的维特比变量值乘以相应的状态转换概率,从中选出最大值,假设2时最大,那么记下t+1时刻状态1之前的路径是t时刻的状态2,以此类推。
Viterbi算法(Viterbi algorithm)的一个广泛应用是自然语言处理中的词性标注。在词性标注中,句子中的单词是观察状态,词性(语法类别)是隐藏状态(注意对于许多单 词,如wind,fish拥有不止一个词性)。对于每句话中的单词,通过搜索其最可能的隐藏状态,我们就可以在给定的上下文中找到每个单词最可能的词性标 注。
总结:
隐马尔科夫的适用场景,用来解决什么问题?
存在很多例子,在这些例子中进程的状态(模式)是不能够被直接观察的,但是可以非直接地,或者概率地被观察为模式的另外一种集合——这样我们就可以定义一类隐马尔科夫模型——这些模型已被证明在当前许多研究领域,尤其是语音识别领域具有非常大的价值。
一个语音识别系统检测的声音(可以观察的状态)是人体内部各种物理变化(隐藏的状态、引申一个人真正想表达的意思)产生的。
解决三种问题:
- 评估:给定的隐马尔科夫模型生成一个给定的观察序列的概率是多少。
- 学习:一个给定的观察序列样本,什么样的模型最可能生成该序列——也就是说,该模型的参数是什么。
- 解码:什么样的隐藏(底层)状态序列最有可能生成一个给定的观察序列。
缺点:
过于简化的假设,即一个状态只依赖于前一个状态,并且这种依赖关系是独立于时间之外的(与时间无关)