Kinect v2.0原理介绍之四:人脸跟踪探讨
~~有兴趣的小伙伴,加kinect算法交流群:462964980。
人脸跟踪
对于kinect人脸检测的原理找到一点,然而…没什么用,具体解读没有找到,以下是自己结合代码,总结的一些信息,有不对的地方请给出指正。
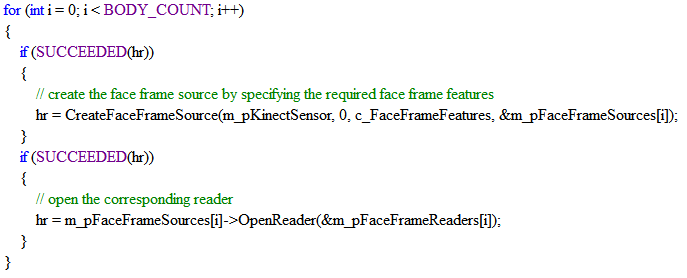
前文已经提到kinect获取数据流接口的步骤:Sensor -> Source -> Reader -> Frame -> Data,在进行人脸检测首先需要获取彩色图像帧,关键实现代码如下:
hr = GetDefaultKinectSensor(&m_pKinectSensor);
hr = m_pKinectSensor->Open();
因为kinect最多可以跟踪六个人的骨骼,而在获取人脸帧的阅读器,用到了六个人的ID,所以可以初步判定,在人脸检测时用到了骨骼数据。
之后通过阅读器获取最近的一帧数据:
hr = m_pFaceFrameReaders[iFace]->AcquireLatestFrame(&pFaceFrame);
然后获取有效帧: hr = pFaceFrame->get_IsTrackingIdValid(&bFaceTracked);有效帧的判断是根据检测ID是否有效。
获取最终的脸部有效帧:
hr = pFaceFrame->get_FaceFrameResult(&pFaceFrameResult);
得到pFaceFrameResult,接下来就可以通过微软提供的接口得到更多脸部信息了。
貌似看到这里并没有得到更多需要的信息,而在上面获取到的脸部帧pFaceFrame的数据类型是IFaceFrame; 而IFaceFrame提供的接口包含:

根据提供的接口可以通过脸部帧获取得到深度帧数据,如下:
当然以同样的方式也可以获取骨骼数据,这样是否能够说明人脸的检测与深度数据、骨骼数据存在关系?也就是说在人脸检测的时候用到了深度数据和骨骼数据?
之后,我们是否可以通过做实验的方式得到一些什么?
如图6所示,kinect对图片中的人脸也可以检测到,这只能说明它用到了彩色数据,但是这也并不能说明他没有用到深度信息啊,那对夜间也可以检测到人脸怎么解释?是不是可以理解为kienct是多通道的,既对有深度信息的彩色图像进行人脸检测,也对没有深度信息的彩色图像进行人脸检测?下面,我们再看一下夜间的情况,图7是夜间对人的人脸检测,图8是夜间对图片的人脸检测。夜间太黑的情况下检测的人脸效果不好,图7是检测到的情况,这能够从一定程度上说明用到了深度信息吧?图8显示在偶尔有点光照的情况下,是能够检测到人脸的,如果光照再暗一点就检测不到了,就这样来看微软对于低光照下人脸检测做的可以。如果你仔细看图8,他能够获取到我那的这个图片的角度,我想在获取人脸角度时,用到了深度信息,这个应该毋庸置疑吧。

图6 白天图片人脸检测
 !
!
图7 夜间人脸检测
图8 夜间图片人脸检测
对快速定位人脸,谈一下自己的拙见,如图9、图10所示,个人认为下面程序可以对人脸加框,我感觉通过这种方式可以快速检测到人脸,人脸肯定是在头结点的一定范内这样是是否可以快速的把人脸抠出来,然后进行之后的一系列操作。如果微软是通过整个图像检测人脸,个人感觉这种可能性比较小,何况还要做到实时,一秒钟还要刷新30帧,这数据量可想而知,说不定微软有特别快的算法呢?
图9 人脸加框

图10 头部结点

它是通过骨骼数据,得到头部节点,获取头部的坐标,然后将骨骼坐标系转化到彩色图像坐标系,获取到头结点在彩色图像中的坐标。
Kinect对于人脸的加框采用的是这个函数:
hr = pFaceFrameResult->get_FaceBoundingBoxInColorSpace(&faceBox);
而faceBox包含的信息非常重要,根据它跟的人脸的位置可以对人脸进行抠图,如图11所示,自己开发的对彩色对象的抠图程序,接下来还要完成对深度图像的抠图,抠图完的图片存放到文件夹中可以供给以后使用。
图11 Kinect抠图
下面是网上找到的一些信息:(资料太少)
对于kinect人脸检测的原理网上也看到了一些
依赖于你PC的CPU能力,人脸跟踪引擎使用4~8ms对一帧图像进行人脸跟踪,仅仅只依赖于CPU(没有使用GPU)。
使用了Active Apperance Model作为二维特征跟踪器,然后我们把计算模型扩展到我们的Kinect深度数据上,然后它可以跟踪三维的人脸,这样使得它比二维特征点跟踪器稳健。
具体技术
坐标系统:
使用了Kinect的坐标系统来输出三维跟踪结果(x,y,z)。Z轴是传感器到用户的距离,Y轴是上下指向。数据都是以米为计量单位(这样一般会读出2.xxx,1.xxx之类的浮点数值),角度都是旋转角度(不是弧度)。
下图12是输出的三维面具在kinect的坐标下情况。
图12 Kinect的坐标系
输入图像:彩色图像和深度图像。其实还需要一个人头和脖子的三维坐标。
(3)人脸跟踪简易流程,如图13所示:
图13 Kinect 人脸跟踪流程图
网上还看到了一些论文,是基于kinect开发的人脸检测,如图14所示,只用到2D信息,没有用到深度信息的人脸检测结果。如图15所示,这是将深度信息应用以后的检测结果,在角度较大的情况下,比图14的结果会好很多。

图14 2D人脸检测图

图15 3D人脸检测图
基于以上分析,kinect可以检测有深度信息的人脸和图片中的人脸,还对角度较大时人脸检测效果这么好,我感觉微软是采取的2D和3D相融合的技术,也就是说当kinect采集到图像以后,同时基于2D和3D技术来检测人脸,之后对检测的人脸进行标定。
以上有很大一部分是个人的一些见解,有不对的地方还望指正。