Spark学习4: RDD详解
1RDD经典定义
package org.apache.spark.rdd
import java.util.Random
import scala.collection.{mutable, Map}
import scala.collection.mutable.ArrayBuffer
import scala.reflect.{classTag, ClassTag}
import com.clearspring.analytics.stream.cardinality.HyperLogLogPlus
import org.apache.hadoop.io.BytesWritable
import org.apache.hadoop.io.compress.CompressionCodec
import org.apache.hadoop.io.NullWritable
import org.apache.hadoop.io.Text
import org.apache.hadoop.mapred.TextOutputFormat
import org.apache.spark._
import org.apache.spark.Partitioner._
import org.apache.spark.SparkContext._
import org.apache.spark.annotation.{DeveloperApi, Experimental}
import org.apache.spark.api.java.JavaRDD
import org.apache.spark.broadcast.Broadcast
import org.apache.spark.partial.BoundedDouble
import org.apache.spark.partial.CountEvaluator
import org.apache.spark.partial.GroupedCountEvaluator
import org.apache.spark.partial.PartialResult
import org.apache.spark.storage.StorageLevel
import org.apache.spark.util.{BoundedPriorityQueue, Utils}
import org.apache.spark.util.collection.OpenHashMap
import org.apache.spark.util.random.{BernoulliSampler, PoissonSampler, SamplingUtils}
/**
* A Resilient Distributed Dataset (RDD), the basic abstraction in Spark. Represents an immutable,
* partitioned collection of elements that can be operated on in parallel. This class contains the
* basic operations available on all RDDs, such as `map`, `filter`, and `persist`. In addition,
* [[org.apache.spark.rdd.PairRDDFunctions]] contains operations available only on RDDs of key-value
* pairs, such as `groupByKey` and `join`;
* [[org.apache.spark.rdd.DoubleRDDFunctions]] contains operations available only on RDDs of
* Doubles; and
* [[org.apache.spark.rdd.SequenceFileRDDFunctions]] contains operations available on RDDs that
* can be saved as SequenceFiles.
* These operations are automatically available on any RDD of the right type (e.g. RDD[(Int, Int)]
* through implicit conversions when you `import org.apache.spark.SparkContext._`.
*
* Internally, each RDD is characterized by five main properties:
*
* - A list of partitions
* - A function for computing each split
* - A list of dependencies on other RDDs
* - Optionally, a Partitioner for key-value RDDs (e.g. to say that the RDD is hash-partitioned)
* - Optionally, a list of preferred locations to compute each split on (e.g. block locations for
* an HDFS file)
*
* All of the scheduling and execution in Spark is done based on these methods, allowing each RDD
* to implement its own way of computing itself. Indeed, users can implement custom RDDs (e.g. for
* reading data from a new storage system) by overriding these functions. Please refer to the
* [[http://www.cs.berkeley.edu/~matei/papers/2012/nsdi_spark.pdf Spark paper]] for more details
* on RDD internals.
*/
abstract class RDD[T: ClassTag](
@transient private var sc: SparkContext,
@transient private var deps: Seq[Dependency[_]]
) extends Serializable with Logging {
/** Construct an RDD with just a one-to-one dependency on one parent */
def this(@transient oneParent: RDD[_]) =
this(oneParent.context , List(new OneToOneDependency(oneParent)))
private[spark] def conf = sc.conf
// =======================================================================
// Methods that should be implemented by subclasses of RDD
// =======================================================================
/**
* :: DeveloperApi ::
* Implemented by subclasses to compute a given partition.
*/
@DeveloperApi
def compute(split: Partition, context: TaskContext): Iterator[T]
/**
* Implemented by subclasses to return the set of partitions in this RDD. This method will only
* be called once, so it is safe to implement a time-consuming computation in it.
*/
protected def getPartitions: Array[Partition]
/**
* Implemented by subclasses to return how this RDD depends on parent RDDs. This method will only
* be called once, so it is safe to implement a time-consuming computation in it.
*/
protected def getDependencies: Seq[Dependency[_]] = deps
/**
* Optionally overridden by subclasses to specify placement preferences.
*/
protected def getPreferredLocations(split: Partition): Seq[String] = Nil
/** Optionally overridden by subclasses to specify how they are partitioned. */
@transient val partitioner: Option[Partitioner] = None
从上面的定义中抽出最重要的一部分RDD的描述
* Internally, each RDD is characterized by five main properties:
*
* - A list of partitions
* - A function for computing each split
* - A list of dependencies on other RDDs
* - Optionally, a Partitioner for key-value RDDs (e.g. to say that the RDD is hash-partitioned)
* - Optionally, a list of preferred locations to compute each split on (e.g. block locations for
* an HDFS file)
然后我们再分别去看每部分的定义
1.1 返回一个partition的数组
/** * Implemented by subclasses to return the set of partitions in this RDD. This method will only * be called once, so it is safe to implement a time-consuming computation in it. */ protected def getPartitions: Array[Partition]
1.2
/** * Implemented by subclasses to return how this RDD depends on parent RDDs. This method will only * be called once, so it is safe to implement a time-consuming computation in it. */ protected def getDependencies: Seq[Dependency[_]] = deps
/** * :: DeveloperApi :: * Implemented by subclasses to compute a given partition. */ @DeveloperApi def compute(split: Partition, context: TaskContext): Iterator[T]
我们注意到compute的一个参数就是TaskContext,下面我们看看TaskContext的内容。
package org.apache.spark
import scala.collection.mutable.ArrayBuffer
import org.apache.spark.annotation.DeveloperApi
import org.apache.spark.executor.TaskMetrics
import org.apache.spark.util.TaskCompletionListener
/**
* :: DeveloperApi ::
* Contextual information about a task which can be read or mutated during execution.
*
* @param stageId stage id
* @param partitionId index of the partition
* @param attemptId the number of attempts to execute this task
* @param runningLocally whether the task is running locally in the driver JVM
* @param taskMetrics performance metrics of the task
*/
@DeveloperApi
class TaskContext(
val stageId: Int,
val partitionId: Int,
val attemptId: Long,
val runningLocally: Boolean = false,
private[spark] val taskMetrics: TaskMetrics = TaskMetrics.empty)
extends Serializable {
@deprecated("use partitionId", "0.8.1")
def splitId = partitionId
// List of callback functions to execute when the task completes.
@transient private val onCompleteCallbacks = new ArrayBuffer[TaskCompletionListener]
// Whether the corresponding task has been killed.
@volatile private var interrupted: Boolean = false
// Whether the task has completed.
@volatile private var completed: Boolean = false
/** Checks whether the task has completed. */
def isCompleted: Boolean = completed
/** Checks whether the task has been killed. */
def isInterrupted: Boolean = interrupted
// TODO: Also track whether the task has completed successfully or with exception.
/**
* Add a (Java friendly) listener to be executed on task completion.
* This will be called in all situation - success, failure, or cancellation.
*
* An example use is for HadoopRDD to register a callback to close the input stream.
*/
def addTaskCompletionListener(listener: TaskCompletionListener): this.type = {
onCompleteCallbacks += listener
this
}
/**
* Add a listener in the form of a Scala closure to be executed on task completion.
* This will be called in all situation - success, failure, or cancellation.
*
* An example use is for HadoopRDD to register a callback to close the input stream.
*/
def addTaskCompletionListener(f: TaskContext => Unit): this.type = {
onCompleteCallbacks += new TaskCompletionListener {
override def onTaskCompletion(context: TaskContext): Unit = f(context)
}
this
}
/**
* Add a callback function to be executed on task completion. An example use
* is for HadoopRDD to register a callback to close the input stream.
* Will be called in any situation - success, failure, or cancellation.
* @param f Callback function.
*/
@deprecated("use addTaskCompletionListener", "1.1.0")
def addOnCompleteCallback(f: () => Unit) {
onCompleteCallbacks += new TaskCompletionListener {
override def onTaskCompletion(context: TaskContext): Unit = f()
}
}
/** Marks the task as completed and triggers the listeners. */
private[spark] def markTaskCompleted(): Unit = {
completed = true
// Process complete callbacks in the reverse order of registration
onCompleteCallbacks.reverse.foreach { _.onTaskCompletion(this) }
}
/** Marks the task for interruption, i.e. cancellation. */
private[spark] def markInterrupted(): Unit = {
interrupted = true
}
}
1.4 这里getPreferredLocation是针对某个partition的,然后返回结果是一个序列,这里之所以有一个序列的返回结果是因为:如果是hadoop的HDFS情况下的partition的话,每个partition会有3个备份,那么这个3个地点都可以作为preferredlocation,如果是计算结果缓存在内存中,那么如果缓存了2份,那就会有2个preferredlocation作为返回结果。
/** * Optionally overridden by subclasses to specify placement preferences. */ protected def getPreferredLocations(split: Partition): Seq[String] = Nil
/** Optionally overridden by subclasses to specify how they are partitioned. */ @transient val partitioner: Option[Partitioner] = None下面看看Partitioner的具体情况。可见Partitioner针对key-value结构进行partition,把整个结构划分成指定的numPartition个数
package org.apache.spark
import java.io.{IOException, ObjectInputStream, ObjectOutputStream}
import scala.collection.mutable
import scala.collection.mutable.ArrayBuffer
import scala.reflect.{ClassTag, classTag}
import scala.util.hashing.byteswap32
import org.apache.spark.rdd.{PartitionPruningRDD, RDD}
import org.apache.spark.serializer.JavaSerializer
import org.apache.spark.util.{CollectionsUtils, Utils}
import org.apache.spark.util.random.{XORShiftRandom, SamplingUtils}
/**
* An object that defines how the elements in a key-value pair RDD are partitioned by key.
* Maps each key to a partition ID, from 0 to `numPartitions - 1`.
*/
abstract class Partitioner extends Serializable {
def numPartitions: Int
def getPartition(key: Any): Int
}
/**
* A [[org.apache.spark.Partitioner]] that implements hash-based partitioning using
* Java's `Object.hashCode`.
*
* Java arrays have hashCodes that are based on the arrays' identities rather than their contents,
* so attempting to partition an RDD[Array[_]] or RDD[(Array[_], _)] using a HashPartitioner will
* produce an unexpected or incorrect result.
*/
class HashPartitioner(partitions: Int) extends Partitioner {另外一个系统提供的Partitioner是下面的
RangePartitioner,比如进行wordcount的时候最后sortByKey方法就会调用这个partitioner
/**
* A [[org.apache.spark.Partitioner]] that partitions sortable records by range into roughly
* equal ranges. The ranges are determined by sampling the content of the RDD passed in.
*
* Note that the actual number of partitions created by the RangePartitioner might not be the same
* as the `partitions` parameter, in the case where the number of sampled records is less than
* the value of `partitions`.
*/
class RangePartitioner[K : Ordering : ClassTag, V](
@transient partitions: Int,
@transient rdd: RDD[_ <: Product2[K,V]],
private var ascending: Boolean = true)
extends Partitioner {
2 常见RDD
2.1 HadoopRDD
每个block可能会存储3份。sc.textFile("HDFS://xxxxxx/ssss")可以得到HadoopRDD
分区: 每个HDFS block,对hadoop的inputSplit进行了包装,成为了hadoopPartition,个数一致
依赖:无,因为这里是读取数据源,没有依赖
函数:这里的compute本质上是定义了如何读取HDFS的数据,使用了Hadoop的API
最佳位置:HDFS block所在位置
分区策略:无
2.2 FilteredRDD, 这是一个典型的窄依赖关系,它所具有的特点也是窄依赖关系中的普遍特性
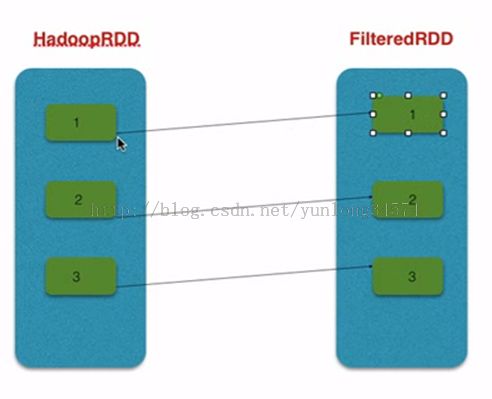
• 分区: 与父RDD一致
• 依赖: 与父RDD一对一
• 函数: 计算父RDD的每个分区并过滤
• 最佳位置: 无(与父RDD一致)
• 分区策略: 无
package org.apache.spark.rdd
import scala.reflect.ClassTag
import org.apache.spark.{Partition, TaskContext}
private[spark] class FilteredRDD[T: ClassTag](
prev: RDD[T],
f: T => Boolean)
extends RDD[T](prev) {
override def getPartitions: Array[Partition] = firstParent[T].partitions
override val partitioner = prev.partitioner // Since filter cannot change a partition's keys
override def compute(split: Partition, context: TaskContext) =
firstParent[T].iterator(split, context).filter(f)
}
FilteredRDD的代码相当的简洁。
只是这里觉得有点奇怪,prev应该是和firstParent是同一个RDD的吧,暂时不明白这里有什么区别没有
2.3 JoinedRDD