Hadoop 2.5.2 安装
安装环境准备:
1、JDK版本支持
Hadoop 2.7 以后的版本需要 Java 7 支持
Hadoop 2.6 以前支持 Java 6
JDK 测试结果
JDK 安装(rpm 方式):
rpm -ivh jdk-7u79-linux-x64.rpm
配置环境变量
在 ~/.bash_profile 中追加
export JAVA_HOME=/usr/java/jdk1.7.0_79
export PATH=$PATH:$JAVA_HOME/bin
执行 source ~/.bash_profile 命令
2、能进行 ssh 远程连接,安装 rsync 文件同步工具
下载安装包
http://mirrors.cnnic.cn/apache/hadoop/common/
Hadoop安装准备工作
1、解压安装包到安装目录
[root@localhost ~]# cd /usr/local/hadoop
[root@localhost hadoop]# ls
hadoop-2.5.2-src.tar.gz
[root@localhost hadoop]# tar -zxvf hadoop-2.5.2.tar.gz
2、hadoop 环境变量配置
在 ~/.bash_profile 中追加
export HADOOP_HOME=/usr/local/hadoop/hadoop-2.5.2
export PATH=$PATH:$HADOOP_HOME/bin
执行 source ~/.bash_profile 命令
3 、编辑目录下 etc/hadoop/hadoop-env.sh 文件,增加如下配置
# set to the root of your Java installation
export JAVA_HOME=/usr/java/latest
# Assuming your installation directory is /usr/local/hadoop/hadoop-2.5.2
export HADOOP_PREFIX=/usr/local/hadoop/hadoop-2.5.2
Hadoop路径一定要正确,否则会报 Error: Could not find or load main class org.apache.hadoop.util.RunJar
单节点安装方式
Hadoop 默认是无分布式模式,如同一Java进程,这对于调试很有用。
下面的例子用来测试在文档中根据正则表达式匹配进行搜索,并将结果输出到指定目录。
$ mkdir input
$ cp etc/hadoop/*.xml input/
$ bin/hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-examples-2.5.2.jar grep input output 'dfs[a-z.]+'
$ cat output/*
注意:output目录不能先创建,否则会报错。
伪分布式安装
Hadoop也可以在单个节点进行伪分布式安装,相当于每个Hadoop后台程序运行在单独的Java进程中。
1、文件配置:
etc/hadoop/core-site.xml:
<configuration>
<property>
<name>fs.defaultFS</name>
<value>hdfs://localhost:9000</value>
</property>
</configuration>
etc/hadoop/hdfs-site.xml:
<configuration>
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
</configuration>
2、设置ssh免密码登陆
检查是否能ssh免密码连接本地: $ ssh localhost
如果不能,执行下面命令:
$ ssh-keygen -t dsa -P '' -f ~/.ssh/id_dsa 生成一对公钥和密钥
$ cat ~/.ssh/id_dsa.pub >> ~/.ssh/authorized_keys 将公钥添加到认证文件中
3、本地运行 MapReduce job,如果想在Yarn中运行 job,可查看 Yarn 在单节点的安装
3.1 格式化文件系统
$ bin/hdfs namenode -format
3.2 启动 NameNode 和 DataNode 程序
$ sbin/start-dfs.sh
hadoop 的日志写入 $HADOOP_LOG_DIR目录(默认是 $HADOOP_HOME/logs目录)
3.3 通过浏览器访问 NameNode,默认访问地址: http://localhost:50070/
注意:这种访问方式,需设置本机Windows的 hosts 文件,并将Linux的防火墙关闭或进行设置

3.4 创建执行 MapReduce 任务所需的目录
$ bin/hdfs dfs -mkdir /user
$ bin/hdfs dfs -mkdir /user/<username>
若本机是64位系统则会产生警告:
WARN util.NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
进入 http://dl.bintray.com/sequenceiq/sequenceiq-bin/ 网址,查看是否有对应版本的文件
下载完文件,将其解压到hadoop的 lib/native 目录下,覆盖原有文件即可
$ tar -zxvf hadoop-native-64-2.5.2.tar -C lib/native/
3.5 复制文件进入分布式文件系统
$ bin/hdfs dfs -put etc/hadoop input
3.6 再次运行测试用例
$ bin/hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-examples-2.5.2.jar grep input output 'dfs[a-z.]+'
3.7 查看运行结果
复制文件进行查看
$ bin/hdfs dfs -get output output
$ cat output/*
或者直接查看
$ bin/hdfs dfs -cat output/*
3.8 完成后可停止hdfs进程
$ sbin/stop-dfs.sh
4、Yarn 单节点安装
通过少量配置就可以在伪分布式下,通过Yarn运行MapReduce任务,另外还需要运行 ResourceManager 和 NodeManager 后台程序
重命名文件
mv etc/hadoop/mapred-site.xml.template etc/hadoop/mapred-site.xml
etc/hadoop/mapred-site.xml:
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
</configuration>
etc/hadoop/yarn-site.xml:
<configuration>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
</configuration>
4.2 启动 ResourceManager 和 NodeManager 后台程序
$ sbin/start-yarn.sh
4.3 通过浏览器查看 ResourceManager 界面,默认访问地址:http://localhost:8088/
4.4 运行 MapReduce 任务
4.5 完成后,可关闭后台程序
$ sbin/stop-yarn.sh
HDFS 高可用集群
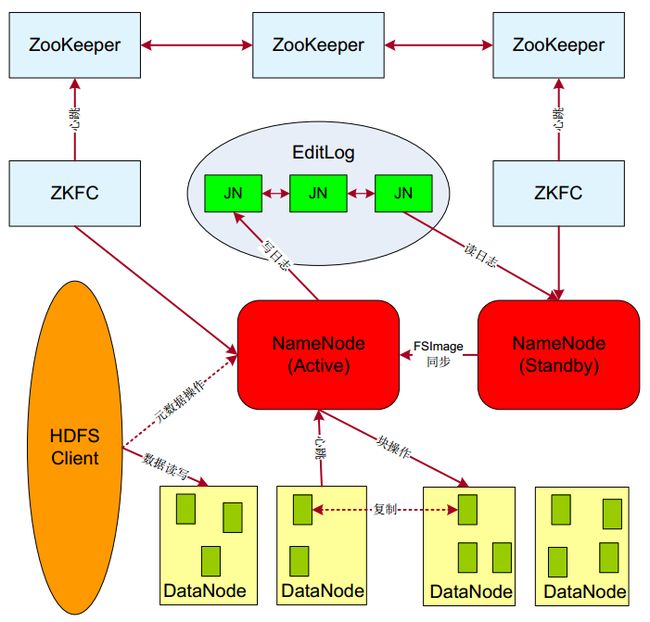
注意: 以下安装均是重新安装,对于已进行伪分布式安装的,请删除已安装的hadoop。
1、安排好集群节点的部署
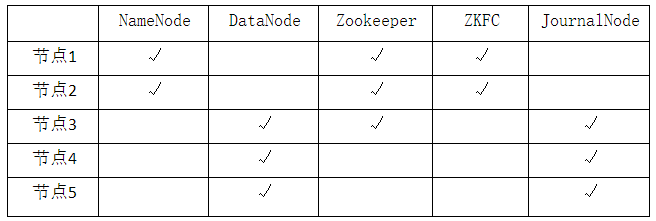
2、考虑开启几个节点,各节点上部署安排
3、每个节点的hosts中配置所有节点的IP和名称
4、所有节点打通SSH,设置免密码登陆
在每个节点上
执行 ssh-keygen -t dsa -P '' -f ~/.ssh/id_dsa 生成一对公钥和密钥
这里选择node01节点,将所有节点公钥均添加到该节点认证文件中
使用命令方式将公钥追加到node01节点
node01节点: $ ssh-copy-id -i ~/.ssh/id_dsa.pub localhost
node02节点: $ ssh-copy-id -i ~/.ssh/id_dsa.pub root@node01
node03节点: $ ssh-copy-id -i ~/.ssh/id_dsa.pub root@node01
.....
最后将node01节点认证文件到其它节点
$ scp ~/.ssh/authorized_keys root@node02:~/.ssh/
$ scp ~/.ssh/authorized_keys root@node03:~/.ssh/
.....
5、所有节点均安装 Hadoop,并进行Hadoop安装准备工作,并使用单节点方式测试。
修改Hadoop配置
hdfs-site.xml
命名服务的逻辑名称,将会作为HDFS集群中路径的绝对组成部分
<property>
<name>dfs.nameservices</name>
<value>mycluster</value>
</property>
每个NameNode在命名服务中唯一标识
<property>
<name>dfs.ha.namenodes.mycluster</name>
<value>nn1,nn2</value>
</property>
监听每个NameNode的RPC地址
<property>
<name>dfs.namenode.rpc-address.mycluster.nn1</name>
<value>machine1.example.com:8020</value>
</property>
<property>
<name>dfs.namenode.rpc-address.mycluster.nn2</name>
<value>machine2.example.com:8020</value>
</property>
machine.example.com 可填该NameNode主机的 host 地址
监听每个NameNode的HTTP地址
<property>
<name>dfs.namenode.http-address.mycluster.nn1</name>
<value>machine1.example.com:50070</value>
</property>
<property>
<name>dfs.namenode.http-address.mycluster.nn2</name>
<value>machine2.example.com:50070</value>
</property>
NameNode读写edits文件的 JournalNodes URI地址
<property>
<name>dfs.namenode.shared.edits.dir</name>
<value>qjournal://node01:8485;node020:8485;node030:8485/mycluster</value>
</property>
HDFS客户端 联系活跃NameNode节点的Java类
<property>
<name>dfs.client.failover.proxy.provider.mycluster</name>
<value>org.apache.hadoop.hdfs.server.namenode.ha.ConfiguredFailoverProxyProvider</value>
</property>
在故障转移中保护活动NameNode节点的脚本或Java类
<property>
<name>dfs.ha.fencing.methods</name>
<value>sshfence</value>
</property>
sshfence SSH到活动NameNode节点并关掉其进程
SSH私钥文件的路径
<property>
<name>dfs.ha.fencing.ssh.private-key-files</name>
<value>/home/exampleuser/.ssh/id_dsa</value>
</property>
上面生成的私钥文件路径 /root/.ssh/id_dsa
journalnode 存储edits文件的本地路径
<property>
<name>dfs.journalnode.edits.dir</name>
<value>/path/to/journal/node/local/data</value>
</property>
如 /opt/hadoop/journal/data 目录
是否启用自动故障转移
<property>
<name>dfs.ha.automatic-failover.enabled</name>
<value>true</value>
</property>
core-site.xml
Hadoop FS 客户端默认路径前缀,最好使用命名服务的逻辑名
<property>
<name>fs.defaultFS</name>
<value>hdfs://mycluster</value>
</property>
Hadoop其他临时目录的基础,NameNode命名文件会保存在其中
<property>
<name>hadoop.tmp.dir</name>
<value>/tmp/hadoop-${user.name}</value>
</property>
也可自定义 /opt/hadoop/temp
zookeeper 集群列表
<property>
<name>ha.zookeeper.quorum</name>
<value>zk1:2181,zk2:2181,zk3:2181</value>
</property>
以上配置文件所有节点均相同
相应节点上安装配置Zookeeper
1、这里选用 3.4.6 版本,安装位置为 /usr/local/zookeeper
2、将conf/zoo_sample.cfg重命名为zoo.cfg,编辑zoo.cfg文件:
a. 修改dataDir=/usr/local/zookeeper
b. server.1=zk1.example.com:2888:3888
server.2=zk2.example.com:2888:3888
server.3=zk3.example.com:2888:3888
3、分别在每台机器下面的dataDir目录中创建一个myid的文件,
文件内容分别为:1,2,3
配置hadoop中的DataNode节点
$ vi etc/hadoop/slaves
加入所有DataNode节点
启动所有zookeeper
$ bin/zkServer.sh start
查看ZK是否启动正确
$ bin/zkServer.sh status
如果有一个leader和多个flower,则说明启动正确
启动三个JournalNode
$ sbin/hadoop-daemon.sh start journalnode
在其中一个NameNode上格式化
$ hdfs namenode -format
格式化提示时,请输入 Y 即可
注意:关闭防火墙或进行设置,不然会报连接错误
service iptables stop
chkconfig iptables off
启动刚格式化的namenode
$ sbin/hadoop-daemon.sh start namenode
格式化第二个namenode,不然会无法启动该NameNode
将第一个NameNode格式化后的元数据拷贝到第二个namenode上
在第二个namenode上执行: $ hdfs namenode -bootstrapStandby
该操作会自动创建相应 hadoop.tmp.dir 目录
执行过程中可能会提示是否格式化,输入 Y 就可以同步并覆盖之前文件
启动第二个namenode
$ sbin/hadoop-daemon.sh start namenode
选择其中一个zkfc节点初始化ZKFC
$ hdfs zkfc -formatZK
在其中一个节点上执行
$ sbin/stop-dfs.sh
手动启动所有 jqurnalnode
$ sbin/hadoop.daemon.sh start journalnode
在其中一个节点上执行
$ sbin/start-dfs.sh
使用 jps 命令查看,如果出现有节点没有起来,删除所有节点hadoop.tmp.dir中文件,重新格式化
保证节点时间一致
测试:
1、通过网页访问NameNode
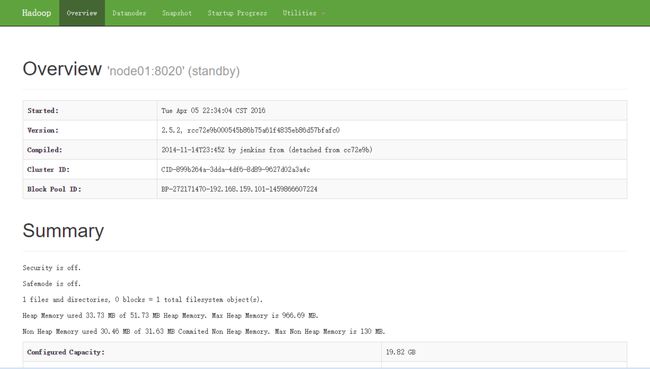
2、通过 Utilities/Browse the file system 访问 hdfs

3、测试 zookeeper 是否能接管
关闭 node02 namenode
$ sbin/hadoop-daemon.sh stop namenode
若不能自动切换,查看zkfc和NameNode日志
4、运行伪分布式下的MapReduce测试程序
查看运行结果
[root@node02 hadoop-2.5.2]# bin/hdfs dfs -cat output/*
6 dfs.audit.logger
4 dfs.class
3 dfs.server.namenode.
2 dfs.audit.log.maxfilesize
2 dfs.period
2 dfs.namenode.rpc
2 dfs.namenode.http
2 dfs.audit.log.maxbackupindex
1 dfsmetrics.log
1 dfsadmin
1 dfs.servers
1 dfs.server.namenode.ha.
1 dfs.nameservices
1 dfs.namenode.shared.edits.dir
1 dfs.ha.namenodes.mycluster
1 dfs.ha.fencing.ssh.private
1 dfs.ha.fencing.methods
1 dfs.ha.automatic
1 dfs.file
1 dfs.client.failover.proxy.provider.mycluster
1 dfs.journalnode.edits.dir
关闭HDFS HA 集群:
在其中一个节点上执行
$ sbin/stop-dfs.sh
分别关闭所有Zookeeper
$ bin/zkServer.sh stop
注意: 千万不要直接关机,容易造成数据损失,引起集群故障
再次启动HDFS HA 集群:
分别启动所有Zookeeper
$ bin/zkServer.sh start
为避免网络延时造成的连接超时,手动启动所有journalnode
$ sbin/hadoop.daemon.sh start journalnode
其中一个节点上执行
$ sbin/start-dfs.sh
MapReduce 和 Yarn
Yarn 与 MapReduce、HDFS关系图
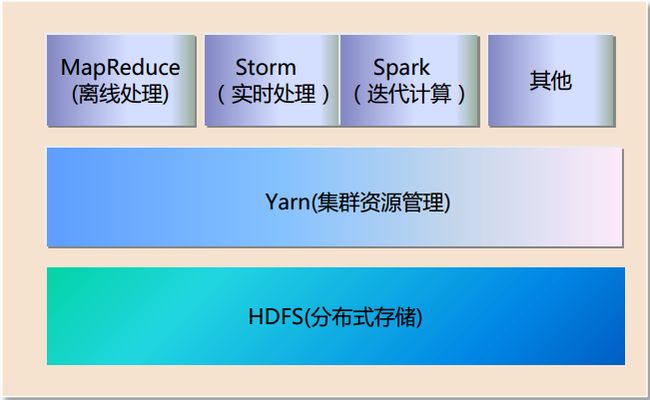
Yarn 组件介绍

安排好集群节点的部署
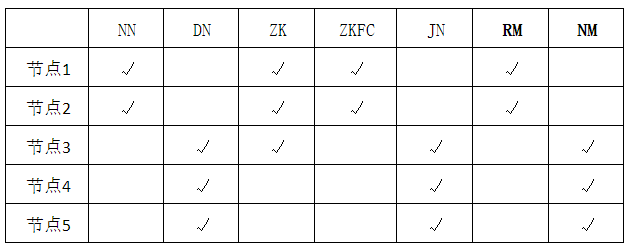
Hadoop配置文件:
mapred-site.xml
执行MapReduce任务的运行框架
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
yarn-site.xml
NodeManager服务名称
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
ResourceManager 配置
<property>
<name>yarn.resourcemanager.ha.enabled</name>
<value>true</value>
</property>
<property>
<name>yarn.resourcemanager.cluster-id</name>
<value>cluster1</value>
</property>
<property>
<name>yarn.resourcemanager.ha.rm-ids</name>
<value>rm1,rm2</value>
</property>
<property>
<name>yarn.resourcemanager.hostname.rm1</name>
<value>rm1的host名称</value>
</property>
<property>
<name>yarn.resourcemanager.hostname.rm2</name>
<value>rm2的host名称</value>
</property>
<property>
<name>yarn.resourcemanager.zk-address</name>
<value>zk1_host:2181,zk2_host:2181,zk3_host:2181</value>
</property>
整个集群启动
启动 Zookeeper集群
启动 HDFS HA 集群
在相应节点上启动 ResourceManager
$ sbin/yarn-daemon.sh start resourcemanager
在其中一个节点上启动 Yarn
$ sbin/start-yarn.sh
通过浏览器查看 ResourceManager 界面
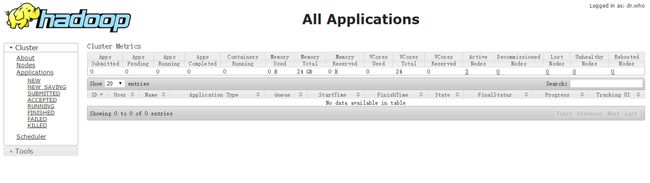
运行伪分布式下的MapReduce测试程序
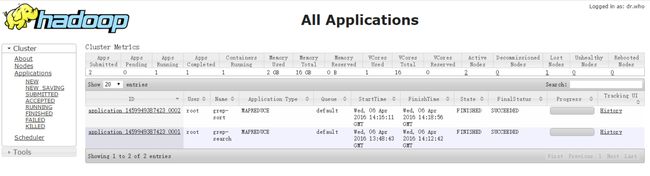
关闭整个集群
在其中一个节点上关闭 Yarn
$ sbin/stop-yarn.sh
在另一个节点上关闭 ResourceManager
$ sbin/yarn-daemon.sh stop resourcemanager
关闭 HDFS HA 集群
关闭 Zookeeper 集群