Hadoop学习四:hadoop分布式环境搭建
Hadoop学习四:hadoop分布式环境搭建
标签(空格分隔): hadoop
- Hadoop学习四hadoop分布式环境搭建
- 一环境准备
- 二分布式环境搭建针对克隆
- 三角色分配
- 四安装配置
一,环境准备
1,删除/opt/app/hadoop-2.5.0/share/doc目录(该目录很占空间)
rm -rf doc/2,关闭虚拟机
[root@hadoop001 hadoop-2.5.0]# halt3,克隆虚拟机(hadoop002 hadoop003)


4,IP和主机名的关系
hadoop001.com.cn—-192.168.44.100
hadoop002.com.cn—-192.168.44.102
hadoop003.com.cn—-192.168.44.103
二,分布式环境搭建(针对克隆)
1,修改主机名称
[root@hadoop001 Desktop]# vi /etc/sysconfig/network2,修改mac地址
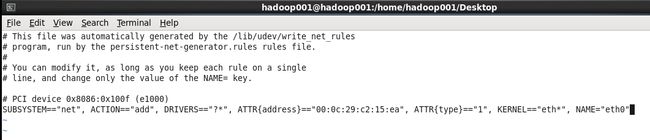
[root@hadoop001 Desktop]# vi /etc/udev/rules.d/70-persistent-net.rules 修改后的文件如下:
3,修改IP地址
[root@hadoop001 Desktop]# setup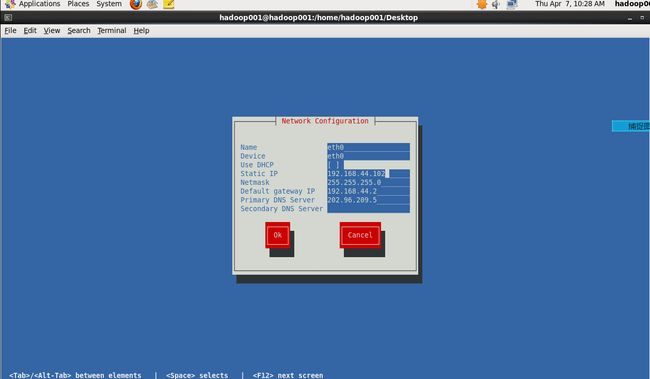
4, 修改网卡文件配置
[root@hadoop001 Desktop]# vi /etc/sysconfig/network-scripts/ifcfg-eth0删除UUID和HWADDR后如下:

5,重启机器生效
三,角色分配
namenode
secondarynamenode
datanode
resourcemanager
nodemanager
historyserver
hadoop001.com.cn (namenode datanode nodemanage)
hadoop002.com.cn (datanode nodemanage resourcemanage)
hadoop003.com.cn (datanode nodemanage secondarynamenode historyserver)
四,安装配置
1,修改本地hosts文件
vi /etc/hosts192.168.44.100 hadoop001.com.cn hadoop001
192.168.44.102 hadoop002.com.cn hadoop002
192.168.44.103 hadoop003.com.cn hadoop0032,配置无秘钥登陆
hadoop001—>hadoop001,hadoop002,hadoop003
hadoop002—>hadoop001,hadoop002,hadoop003
ssh-keygen -t rsa //生成秘钥
cd
cd .ssh/
ssh-copy-id hadoop001.com.cn //将秘钥拷贝到其他服务器上3,配置NTP服务器—用于保持各个服务器之间的时间同步
hadoop001.com.cn
[root@hadoop001 .ssh]# rpm -qa|grep ntp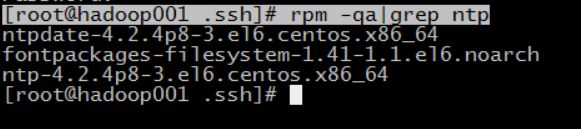
vi /etc/ntp.conf
vi /etc/sysconfig/ntpd 添加 SYNC_HWCLOCK=yes

修改系统的时间和当前时间一致
ntpdate 0.centos.pool.ntp.org启动服务
service ntpd start chkconfig ntpd on //开机自动启动配置其他服务器和hadoop001.com.cn的时间一致
crontab -e ---------
*/10 * * * * /usr/sbin/ntpdate hadoop001.com.cn ---------
service crond restart4,配置namenode和secondarynamenode
在hadoop001.com.cn服务器上修改hdfs-site.xml文件
<configuration>
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
<property>
<name>dfs.namenode.http-address</name>
<value>hadoop001.com.cn:50070</value>
</property>
<property>
<name>dfs.namenode.secondary.http-address</name>
<value>hadoop003.com.cn:50090</value>
</property>
</configuration>5,配置datanode
在hadoop001.com.cn服务器上修改slaves文件
hadoop001.com.cn
hadoop002.com.cn
hadoop003.com.cn
6,配置resourcemanager
修改yarn-site.xml文件
<configuration>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.log-aggregation-enable</name>
<value>true</value>
</property>
<property>
<name>yarn.log-aggregation.retain-seconds</name>
<value>604800</value>
</property>
<property>
<name>yarn.resourcemanager.hostname</name>
<value>hadoop002.com.cn</value>
</property>
</configuration>7,配置historyserver
修改mapred-site.xml文件
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
<property>
<name>mapreduce.jobhistory.webapp.address</name>
<value>hadoop003.com.cn:19888</value>
</property>
</configuration>8,将hadoop001.com.cn服务器上的hadoop安装包复制到hadoop002.com.cn和hadoop003.com.cn上面
[hadoop001@hadoop001 app]$ scp -r hadoop-2.5.0/ hadoop002.com.cn:/opt/app/
[hadoop001@hadoop001 app]$ scp -r hadoop-2.5.0/ hadoop003.com.cn:/opt/app/9,启动集群
bin/hdfs namenode -format
sbin/start-all.sh
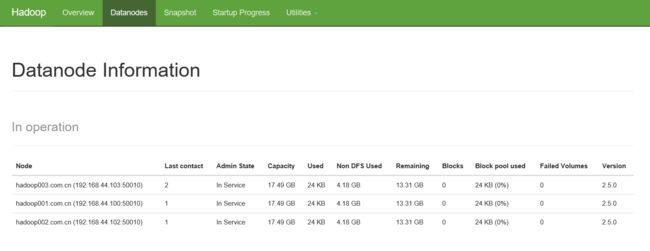
10,查看集群
http://hadoop001.com.cn:50070/dfshealth.html#tab-overview
bin/hdfs dfs -put etc/hadoop/core-site.xml /
bin/hdfs dfs -ls /