Spark Streaming调试——NetworkWordCount和KafkaWordCount
1.NetworkWordCount
这是一个最简单的案例,接受socket流数据并进行wordcount。
源代码在spark安装目录下的examples/src/main/scala/org/apache/spark/examples/streaming下,就是NetworkWordCount.scala文件
至于运行方法,源代码的注释中也写的很清楚了:
首先在一个终端里运行
nc -lk 9999
nc是netcat的命令,这是个很好用的小软件。如果你的找不到这个command,就用yum或者apt-get命令下载一个吧。
再在另一个终端里运行
bin/run-example org.apache.spark.examples.streaming.NetworkWordCount localhost 9999
当第二个终端稳定的输出之后:
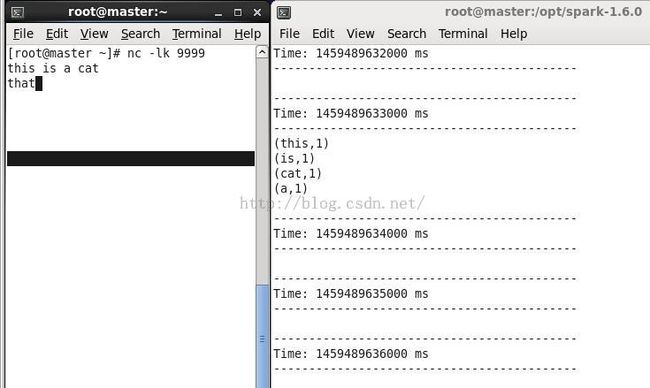
在第一个终端输入句子,就会在第二个终端里显示词频统计了。
下面问题来了:
如果你和笔者一样是在虚拟机中运行的这个例子,并且也遇到了第二个终端卡着不显示结果的问题?
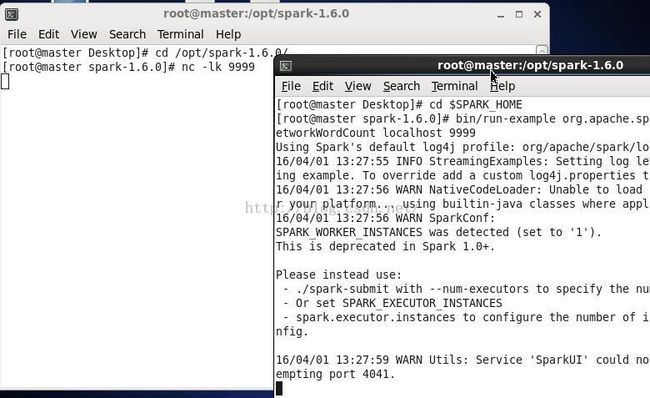
经过各种尝试,笔者找到了一个办法,就是把虚拟机的改成多核的:
修改处理器数量,或者每个处理器的核心数都可以。
这样就可以愉快的运行了:
2.KafkaWordCount
这个例子就比较简单了,中途运行也没出什么岔子,这篇文章也讲的很清楚了
http://www.aboutyun.com/thread-9580-1-1.html
首先下载kafka(http://kafka.apache.org/),下载时注意对应好自己的scala版本
解压之后,可以按照官网的案例运行一些简单的案例(http://kafka.apache.org/documentation.html#quickstart)
下面我们来运行KafkaWordCount,首先运行zookeeper,进入kafka的安装目录
bin/zookeeper-server-start.sh config/zookeeper.properties &
以上的&表示后台运行,这样就算把终端关掉也会继续运行了
host.name=localhost advertised.host.name=localhost
bin/kafka-server-start.sh config/server.properties &
bin/kafka-topics.sh --create --zookeeper localhost:2181 --replication-factor 1 --partitions 1 --topic test这个topic叫test,2181是zookeeper默认的端口号,partition是topic里面的分区数,replication-factor是备份的数量,在kafka集群中使用,这里单机版就不用备份了
列出现有的topic
bin/kafka-topics.sh --list --zookeeper localhost:2181会出现结果test
首先运行KafkaWordCountProducer
bin/run-example org.apache.spark.examples.streaming.KafkaWordCountProducer localhost:9092 test 3 5
再运行 KafkaWordCount
bin/run-example org.apache.spark.examples.streaming.KafkaWordCount localhost:2181 test-consumer-group test 1
就可以顺利的看到结果了