中断浅析
intel x86支持256种向量中断
中断分为屏蔽中断与非屏蔽中断,而异常分为故障和陷阱
0~31对应异常和非屏蔽中断
32~47对应屏蔽中断(即I/O设备引起的中断)
47~255对应软中断,软中断? 其中128号即0x80用于实现系统调用
中断描述符表IDT
实地址模式下原来的中断向量表被由于具体位数的变化,名称也变为中断描述符表,变化后每个表项称为门描述符,由8个字节组成。
这些门描述符的类型分为3类:
1、中断门:类型码为110,其中包含了一个中断或异常处理程序所在段的选择符和段内偏移量
通过此中断门进入中断处理程序时,清除IF标志,即关中断,用户态进程不能访问Intel的中断门,所有的中断处理程序都由中断门激活,并限制在内核态中
2、陷阱门:类型码为111,与中断门唯一的区别在于进入处理程序时不会清除IF标志即不会关中断
3、系统门:Linux特别设置,用来让用户态的进程访问Intel的陷阱门,所以它的DPL是3,系统调用就是通过此门进入内核
3种门描述符的插入方式:
中断门:
static inline void set_intr_gate(unsigned int n, void *addr) /*设置中断门的代码*/
{
BUG_ON((unsigned)n > 0xFF);/*检查n是否大于8位2进制数的最大值,即255,大于则超过中断编号的限制,出错*/
_set_gate(n, GATE_INTERRUPT, addr, 0/*dpl域*/, 0, __KERNEL_CS);/*设置中断门*/
}陷阱门:
static inline void set_trap_gate(unsigned int n, void *addr) /*插入一个陷阱门*/
{
BUG_ON((unsigned)n > 0xFF);/*检查n是否大于8位2进制数的最大值,即255,大于则超过中断编号的限制,出错*/
_set_gate(n, GATE_TRAP, addr, 0, 0, __KERNEL_CS);/*设置陷阱门*/
}系统门:
static inline void set_system_trap_gate(unsigned int n, void *addr)/*插入一个系统门*/
{
BUG_ON((unsigned)n > 0xFF);/*检查n是否大于8位2进制数的最大值,即255,大于则超过中断编号的限制,出错*/
_set_gate(n, GATE_TRAP, addr, 0x3/*dpl为3*/, 0, __KERNEL_CS);/*设置dpl为3的陷阱门,即系统门*/
}系统门的插入语句和陷阱门几乎一样,只是DPL处的值变为了3,因此系统门是一个特殊的陷阱门。
门描述符的初始化:
系统中的trap_init()函数用于设置中断描述符表开头的19个陷阱门和系统门,这里的19个陷阱门是用于异常的处理,那么剩下的13个应该是非屏蔽中断的门描述符
源码:
void __init trap_init(void) /*初始化陷阱门与系统门*/
{
...
set_intr_gate(0, ÷_error); /*总计19个陷阱门,但为什么代码是set_intr_gate,这是中断门啊*/
set_intr_gate_ist(1, &debug, DEBUG_STACK);
set_intr_gate_ist(2, &nmi, NMI_STACK);
/* int3 can be called from all */
set_system_intr_gate_ist(3, &int3, DEBUG_STACK);
/* int4 can be called from all */
set_system_intr_gate(4, &overflow);
set_intr_gate(5, &bounds);
set_intr_gate(6, &invalid_op);
set_intr_gate(7, &device_not_available);
#ifdef CONFIG_X86_32
set_task_gate(8, GDT_ENTRY_DOUBLEFAULT_TSS);
#else
set_intr_gate_ist(8, &double_fault, DOUBLEFAULT_STACK);
#endif
set_intr_gate(9, &coprocessor_segment_overrun);
set_intr_gate(10, &invalid_TSS);
set_intr_gate(11, &segment_not_present);
set_intr_gate_ist(12, &stack_segment, STACKFAULT_STACK);
set_intr_gate(13, &general_protection);
set_intr_gate(14, &page_fault);
set_intr_gate(15, &spurious_interrupt_bug);
set_intr_gate(16, &coprocessor_error);
set_intr_gate(17, &alignment_check);
#ifdef CONFIG_X86_MCE
set_intr_gate_ist(18, &machine_check, MCE_STACK);
#endif
set_intr_gate(19, &simd_coprocessor_error);
...
#ifdef CONFIG_X86_32
if (cpu_has_fxsr) {
printk(KERN_INFO "Enabling fast FPU save and restore... ");
set_in_cr4(X86_CR4_OSFXSR);
printk("done.\n");
}
if (cpu_has_xmm) {
printk(KERN_INFO
"Enabling unmasked SIMD FPU exception support... ");
set_in_cr4(X86_CR4_OSXMMEXCPT);
printk("done.\n");
}
set_system_trap_gate(SYSCALL_VECTOR, &system_call); /*设置系统门*/
set_bit(SYSCALL_VECTOR, used_vectors);
#endif
...
}
这里有一个疑问,可以看到19个陷阱门的语句基本都是set_intr_gate,这是设置中断门的语句啊,而这里应该是陷阱门的设置,不理解原因
中断门的设置中总计设置了224个中断门,这里是256个中断数量减去了一开始0~31个异常和非屏蔽中断这些留给CPU后的数量
对于这224个中断门所对应的中断处理程序IRQn_interrupt是如何形成的呢,系统中利用BULID_IRQ来建立中断处理程序,这个BUILD_IRQ是一段汇编代码
其主要完成的就是将中断号-256的值压入堆栈(因为每个中断处理程序的中断号不同,所以每个中断处理程序唯一不同的就是压入栈中的这个数),接着跳向了common_interrupt,这个也是一段汇编语句,主要完成了将中断处理程序所要使用的所有CPU寄存器都保存在栈中,之后调用do_IRQ函数继续操作。
总结下来就是IRQn_interrupt的功能是将相应的值压栈,保存寄存器值,调用do_IRQ。
中断相关数据结构
在中断中最重要的数据结构有三个:
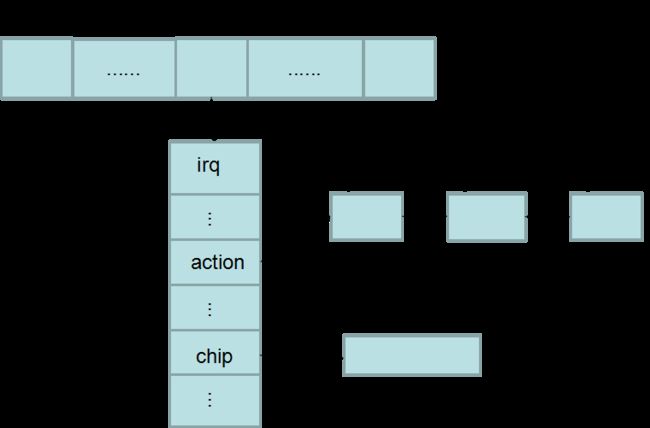
首先是中断向量的结构体irq_desc,在中断向量表中,每个中断向量都有与其对应的此结构体,用它来描述一个中断向量,对于外设中就可以理解为一条中断线的描述结构体
struct irq_desc {
unsigned int irq; /*中断号*/
struct timer_rand_state *timer_rand_state;
unsigned int *kstat_irqs;
#ifdef CONFIG_INTR_REMAP
struct irq_2_iommu *irq_2_iommu;
#endif
irq_flow_handler_t handle_irq; /*这条中断线的中断处理程序,对于外设中断线就是IRQn_interrupt*/
struct irq_chip *chip; /*是中断控制器的描述符,和不同的硬件相关*/
struct msi_desc *msi_desc;
void *handler_data; /*中断处理程序的参数*/
void *chip_data; /*chip的参数*/
struct irqaction *action; /* IRQ action list */ /*指向了一个单链表,链表中的元素是irqaction结构体,是每个中断服务例程的对应结构体*/
unsigned int status; /* IRQ status */ /*中断线当前状态*/
unsigned int depth; /* nested irq disables */ /*值为0时表示中断线激活,为正数时是指中断线被禁止的次数*/
unsigned int wake_depth; /* nested wake enables */
unsigned int irq_count; /* For detecting broken IRQs */ /*中断线发生中断的次数*/
unsigned long last_unhandled; /* Aging timer for unhandled count */
unsigned int irqs_unhandled; /*此条中断线上未处理中断发生的次数*/
spinlock_t lock;
#ifdef CONFIG_SMP
cpumask_var_t affinity;
unsigned int node;
#ifdef CONFIG_GENERIC_PENDING_IRQ
cpumask_var_t pending_mask;
#endif
#endif
atomic_t threads_active;
wait_queue_head_t wait_for_threads;
#ifdef CONFIG_PROC_FS
struct proc_dir_entry *dir;
#endif
const char *name; /*在/proc/interrupts中显示的中断名称*/
} ____cacheline_internodealigned
#ifndef CONFIG_SPARSE_IRQ
extern struct irq_desc irq_desc[NR_IRQS];
#endif其中记录了一个中断向量的所有信息,另外可以看到所有的irq_desc组成了irq_desc[NR_IRQS]数组
接下来是其中提到的irqaction结构体,这个结构体是用来描述具体的中断服务例程的,例如一条中断线如果是多个外设在共享,那么这条中断线的action字段就会是一个单链表,其中链接了所有的外设各自的中断服务例程
struct irqaction { /*为了让多个设备共享一条中断线而设置的数据结构*/
irq_handler_t handler; /*钩子函数,指向一个具体I/O设备的中断服务程序,2个参数int是中断号IRQ,空指针是传入dev_id*/
unsigned long flags; /*描述中断线与I/O设备之间的关系*/
const char *name; /*I/O设备名*/ /*表示这个数据结构是每个设备都有的一个结构体*/
void *dev_id; /*唯一表示设备的设备id(主次设备号?)*/
struct irqaction *next; /*指向irqaction描述符表的下一个元素,前提是flags有IRQ_SHARED标志,即一条中断线多个设备共享才有此链表*/
int irq; /*中断号*/
struct proc_dir_entry *dir;
irq_handler_t thread_fn;
struct task_struct *thread; /*线程级中断的指针*/
unsigned long thread_flags;
};最后的是关于中断控制器的描述符irq_chip,对于中断控制器来说有着不同的体系结构,每个都有着自己的中断处理方式,内核为了统一管理于是提供了中断处理的接口,这就是irq_chip
struct irq_chip {
const char *name; /*中断控制器名称*/
unsigned int (*startup)(unsigned int irq); /*启动中断线的函数*/
void (*shutdown)(unsigned int irq); /*关闭中断线的函数*/
void (*enable)(unsigned int irq); /*允许中断的函数*/
void (*disable)(unsigned int irq); /*禁止中断的函数*/
void (*ack)(unsigned int irq);
void (*mask)(unsigned int irq);
void (*mask_ack)(unsigned int irq);
void (*unmask)(unsigned int irq);
void (*eoi)(unsigned int irq);
void (*end)(unsigned int irq);
int (*set_affinity)(unsigned int irq,
const struct cpumask *dest);
int (*retrigger)(unsigned int irq);
int (*set_type)(unsigned int irq, unsigned int flow_type);
int (*set_wake)(unsigned int irq, unsigned int on);
void (*bus_lock)(unsigned int irq);
void (*bus_sync_unlock)(unsigned int irq);
/* Currently used only by UML, might disappear one day.*/
#ifdef CONFIG_IRQ_RELEASE_METHOD
void (*release)(unsigned int irq, void *dev_id);
#endif
/* * For compatibility, ->typename is copied into ->name. * Will disappear. */
const char *typename;
};可以看到其中大部分是钩子函数,即内核提供的统一的接口,对于中断控制器最经典的就是2片级联的8259A,即总计有15个irq_desc描述符,其中每个的chip字段都指向了8259A的irq_chip结构体
struct irq_chip i8259a_irq_type = {
.name = "XT-PIC",
.startup = i8259a_startup_irq,
.shutdown = i8259a_disable_irq,
.enable = i8259a_enable_irq,
.disable = i8259a_disable_irq,
.ack = i8259a_mask_and_ack_irq,
.end = i8259a_end_irq,
};可以看到8259A的irq_chip中将接口中挂上了自己的实现函数,这个就是8259A针对irq_chip的具体实现。
中断和异常的处理过程
每次当CPU执行完当前命令后,都会先判断执行当前命令的过程中是否发生了中断与异常,如果没有发生则继续执行CS:EIP指向的下一个命令
而如果发生了就要对其进行相应的操作:
首先确定发生中断或异常的向量,在IDTR寄存器中找到IDT表并在其中找到相应的门,接下来进行“段”与“门”级的检查(即比较CPU的特权级与门描述符中的特权级以判断是否能够通过这道门),最后需要检查特权级是否发生变化以决定是否需要进行堆栈的更换,确保能够在处理完中断或异常后能够回到原来的位置继续执行下一条指令。
对于外设来说,linux为其提供了15条中断线(8259A),即32~47号的中断描述符,而每一个中断线都有着其自己的中断处理程序IRQn_interrupt,而在每条中断线上linux允许多个外设对中断线进行分享,每个外设又有着自己的中断服务例程
因此对于外设中断处理程序的执行过程是:接着上面判断完特权级是否发生变化,通过中断门获得了中断处理程序IRQn_interrupt,由于这里进入的是中断门(那么这条中断线会被禁用),接下来,对于IRQn_interrupt是指32~47这15条中断线中任意一条线的中断处理程序,这15个里面每个中断处理程序都需要调用do_IRQ函数来对所接受的中断进行应答,并且会禁止这条中断线。
unsigned int __irq_entry do_IRQ(struct pt_regs *regs) /*处理所有中断的请求*/
{
struct pt_regs *old_regs = set_irq_regs(regs);
/* high bit used in ret_from_code */
unsigned vector = ~regs->orig_ax;
unsigned irq;
exit_idle(); /*由中断调用,预示着线程结束?*/
irq_enter(); /*进入中断上下文*/
irq = __get_cpu_var(vector_irq)[vector]; /*获取中断号*/
if (!handle_irq(irq, regs)) { /*调用handle_irq来完成调用请求队列中的每个中断服务例程*/
ack_APIC_irq();
if (printk_ratelimit())
pr_emerg("%s: %d.%d No irq handler for vector (irq %d)\n",
__func__, smp_processor_id(), vector, irq);
}
irq_exit();
set_irq_regs(old_regs);
return 1;
}很多地方还不怎么懂,不过可以看出主要是进入了中断上下文且获取中断号,并且会执行handle_irq来调用中断服务例程
bool handle_irq(unsigned irq, struct pt_regs *regs)
{
struct irq_desc *desc;
stack_overflow_check(regs);
desc = irq_to_desc(irq); /*根据中断号在数组irq_desc中找到对应的一项*/
if (unlikely(!desc)) /*判断desc是否为空*/
return false; /*为空则返回出错*/
generic_handle_irq_desc(irq, desc);
return true;
}此函数中通过irq获取了中断线的描述结构体desc,下面的过程可以想到,通过desc可以获得这条中断线的中断处理程序,于是进入不同中断线的处理程序,进行不同中断的处理
对于15条外设中断线都是调用了handle_IRQ_event来对irq_desc的action字段指向的单链表中所有的中断服务例程进行遍历,但是并不是所有都会执行,一般硬件设备会提供一个状态寄存器,于是可以使中断服务例程来检查是否要为硬件服务,所以基本上在整个队列中只会有一个中断服务例程会执行,就是发生中断的那个外设,而如果没有找到需要服务的外设的话,那么中断不会进行处理,于是irq_desc中的irqs_handle这个用来记录中断线上未处理中断次数的字段就会加1.
中断上、下部分:
上半部分只执行中断处理程序
对于为什么要分上下部分执行,有些中断的操作比如某条中断线,如果它正在处理中断处理程序时,会屏蔽同一条中断线上的中断请求。这是就会需要这个程序尽快执行完毕,而由于外设中断是异步的,那么随时都有可能会发生,如果在程序处理过程中产生了中断,此时这条中断线正好屏蔽,那么就造成了中断丢失,因此系统需要能够尽快对中断做出应答,而处理的过程尽量拖后,将应答和处理分为两部分,那么就可以在处理的过程中使中断线不被屏蔽,而只是应答的工作执行的时间会很短,因此不会造成中断的丢失等情况。(中断处理程序至少会导致同级的中断请求被屏蔽)
上半部分:中断处理程序
下半部分:小任务(tasklet)、工作队列、软中断(其中tasklet和工作队列都是基于软中断)
产生中断时,先交给中断处理程序执行,进行应答等操作,然后会调用下半部分的机制来对这个中断请求进行具体操作,而下半部分什么时候来执行呢,这是内核来决定的
tasklet
是中断处理下半部分最常用的方法,其由中断处理程序调用
首先关于tasklet有一个tasklet结构体
struct tasklet_struct /*tasklet结构体,每一个结构体代表了一个tasklet*/
{
struct tasklet_struct *next; /*链表中下一个tasklet*/
unsigned long state; /*这个tasklet此刻的状态,一般是TASKLET_STATE_SCHED即tasklet已经被调度且准备运行,而TASKLET_STATE_RUN表示正在运行,而这个只能用在多处理器的情况下*/
atomic_t count; /*引用计数,只有当为0时,tasklet才会被激活,否则是禁止的,不可以执行*/
void (*func)(unsigned long); /*一个钩子函数,指向了tasklet的处理函数*/
unsigned long data; /*即传给func函数的参数,无符号长整形*/
};每个个tasklet_struct都代表了一个tasklet即一个小任务。小任务不能睡眠所以小任务中不能使用信号量或者其他产生阻塞的函数
每一个小任务都需要先声明一个对应其的tasklet_struct
对于tasklet_struct有着两种声明方法:静态和动态
其中静态的操作是
#define DECLARE_TASKLET(name, func, data) \ /*创建处于激活状态的tasklet,即创建后可以通过调度函数进行调度来被内核执行*/
struct tasklet_struct name = { NULL, 0, ATOMIC_INIT(0), func, data }
#define DECLARE_TASKLET_DISABLED(name, func, data) \ /*创建处于禁止态的tasklet,创建后还不能立刻被调度执行*/
struct tasklet_struct name = { NULL, 0, ATOMIC_INIT(1), func, data }
#define ATOMIC_INIT(i) { (i) }从静态操作中可以看出tasklet结构体中count字段的作用,对于创建的tasklet是否可以直接调度执行取决于它
动态的操作是
void tasklet_init(struct tasklet_struct *t, /*动态创建一个tasklet*/
void (*func)(unsigned long), unsigned long data)
{
t->next = NULL;
t->state = 0;
atomic_set(&t->count, 0);
t->func = func;
t->data = data;
}这两种操作并没有什么不同之处,所以都可以使用
对于上面的tasklet中的func字段,是针对此种tasklet的处理函数,因此需要视具体情况而定,即这个函数由我们自己实现它的具体功能
这样我们就声明好了一个tasklet,那么剩下的就是对其进行调度从而让它被执行
tasklet的调度函数是tasklet_schedule
static inline void tasklet_schedule(struct tasklet_struct *t) /*tasklet调度函数*/
{
if (!test_and_set_bit(TASKLET_STATE_SCHED, &t->state)) /*检查tasklet的状态是否是TASKLET_STATE_SCHED,如果是的话那么表示已经被调度过不需再次调度*/
__tasklet_schedule(t);
}
void __tasklet_schedule(struct tasklet_struct *t) /*tasklet调度的内部实现*/
{
unsigned long flags;
local_irq_save(flags); /*保存中断状态,同时禁止本地中断*/
t->next = NULL;
*__get_cpu_var(tasklet_vec).tail = t;
__get_cpu_var(tasklet_vec).tail = &(t->next); /*将要调度的tasklet添加到每一个cpu唯一的tasklet_vec链表的表头上*/
raise_softirq_irqoff(TASKLET_SOFTIRQ); /*唤醒TASKLET_SOFTIRQ,在下一次调用do_softirq时会执行此tasklet*/
local_irq_restore(flags); /*恢复中断状态并返回*/
}工作队列
为什么还需要工作队列这种机制呢?tasklet有一个问题就是其不能睡眠,而工作队列最大的特点就是其能解决睡眠的问题。
为什么其能睡眠呢?因为工作队列将推后的工作交给一个内核线程(内核能够感知,也可以称为工作者线程)去执行,即其在进程的上下文环境中执行,于是工作队列执行的中断代码中有了进程的特性即能够睡眠以及重新调度。tasklet不能进行睡眠其原因就是它的执行程序是运行在中断上下文中的。
所谓的进程上下文,就是一个进程在执行的时候,CPU的所有寄存器中的值、进程的状态以及堆栈中的内容
这里关于为何不能睡眠还不怎么理解
与tasklet一样工作队列也有其自己的结构体:
struct work_struct { /*工作队列结构体,这里在2.6.20版本后发生了变化*/
atomic_long_t data; /*原子级操作的长整形参数data,它并不是指之前老版本中的data了,而是pending和wq_data的结合体,起到了其二者的作用*/
struct list_head entry; /*链接所有工作的链表*/
work_func_t func; /*对于工作的处理函数,参数是一个指向work_struct的指针*/
};这里针对之前版本的结构体对比,少了两个参数,一个是用来传递用户数据的参数data,而第二个是timer,这是用来实现延迟工作的参数
第一个是在2.6.20版本后使用工作队列需要将work_struct定义在用户的数据结构中,于是通过container_of来得到用户数据,就不再需要data这个参数来进行用户数据的传递
而第二个则是为了使得work_struct更加简洁单纯,于是将timer这个参数拿了出来,单独定义一个新的结构体delayed_work来处理延迟
struct delayed_work {
struct work_struct work;
struct timer_list timer; /*延迟的工作队列所用到的定时器*/
};工作队列也有其自己的创建方式:分为静态与动态
静态:
#define DECLARE_WORK(n, f) \
struct work_struct n = __WORK_INITIALIZER(n, f)动态:
#define INIT_WORK(_work, _func) \
do { \
(_work)->data = (atomic_long_t) WORK_DATA_INIT(); \
INIT_LIST_HEAD(&(_work)->entry); \
PREPARE_WORK((_work), (_func)); \
} while (0)
工作队列的调度函数为
int schedule_work(struct work_struct *work)
{
return queue_work(keventd_wq, work);
}