K-means算法
1. 聚类问题
1.1. 相异度
设X={x_1,x_2,…,x_n },Y={y_1,y_2,…,y_n },其中X,Y是两个元素项,各自具有n个可度量特征属性,那么X和Y的相异度可定义为:

相异度是两个元素对实数域的一个映射,所映射的实数定量表示两个元素的相异度。当元素的所有特征属性都是标量时,可以用距离来作为相异度,最常用距离有欧式距离:
![]()
曼哈顿距离:
闵可夫斯基距离:
1.2. 聚类问题
聚类问题定义:给定一个元素集合D,其中每个元素具有n个可观察属性,使用某种算法将D划分成k个子集,要求每个子集内部的元素之间相异度尽可能低,而不同子集的元素相异度尽可能高。其中每个子集叫做一个簇。聚类是观察式学习,在聚类前可以不知道类别甚至不给定类别数量,是无监督学习的一种。目前聚类广泛应用于统计学、生物学、数据库技术和市场营销等领域。K-means算法是一种最简单的聚类算法。
2. K-means算法
2.1. 问题提出
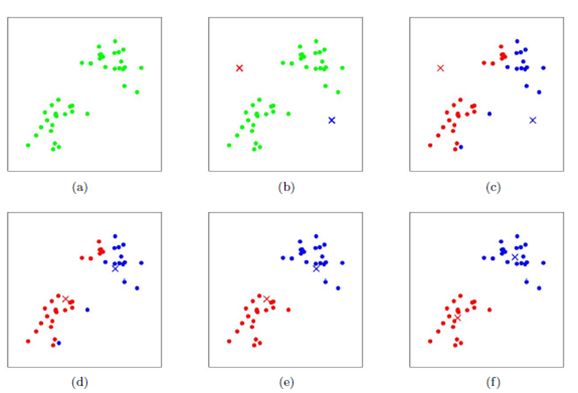
上图中有七个样本点,将其分为两类(K=2),如何聚类?
- 随机在图中取K(这里K=2)个种子点(图中的灰色点)。
- 对图中的所有点求到这K个种子点的距离,假如点Pi离种子点Si最近,那么Pi属于Si点群。(上图中,我们可以看到A,B属于上面的种子点,C,D,E属于下面中部的种子点)。
- 移动种子点到属于他的“点群”的中心。(见图上的第三步)。
- 然后重复第2和第3步,直到,种子点没有移动(图中的第四步上面的种子点聚合了A,B,C,下面的种子点聚合了D,E)。
2.2. 算法步骤
- 从D中随机取k个元素,作为k个簇的各自的中心。
- 分别计算剩下的元素到k个簇中心的相异度,将这些元素分别划归到相异度最低的簇。
- 根据聚类结果,重新计算k个簇各自的中心,计算方法是取簇中所有元素各自维度的算术平均数。
- 将D中全部元素按照新的中心重新聚类。
- 重复第4步,直到聚类结果不再变化。
- 将结果输出。
算法求解过程如下图所示:
这里给出算法的一个演示地址:http://home.deib.polimi.it/matteucc/Clustering/tutorial_html/AppletKM.html。
2.3. 算法分析
由上面的算法过程知K-means的结束条件是收敛,而K-means完全可以保证收敛性。定义畸变函数如下:
![]()
J函数表示每个样本点到其质心的距离平方和。K-means是要将J调整到最小。假设当前J没有到最小值,那么首先固定每个类的质心u_j,调整每个样例的所属类别c^((i))来让J函数减小。同样,固定类别调整每个类的质心也可以使J减小。由于J函数是非凸函数,因此不能保证所取的最小值为全局最小值,但一般局部最优已满足要求。若害怕陷入局部最优,可以取不同的初始值多跑几次,取最小的J对应的u和c。
K-means算法优点是简单实用,确定的K 个划分到达平方误差最小。当聚类是密集的,且类与类之间区别明显时,效果较好。对于处理大数据集,这个算法是相对可伸缩和高效的,计算的复杂度为O(NKt)(其中N是数据对象的数目,t是迭代的次数。一般来说,K<<N,t<<N)。
K-means算法缺点主要和K的选取以及初始质心的选取有关:
- K是事先给定的,这个K值的选定是非常难以估计的。很多时候,事先并不知道给定的数据集应该分成多少个类别才最合适。ISODATA算法(较为复杂,此处不介绍)通过类的自动合并和分裂,得到较为合理的类型数目K。
- K-Means算法需要初始随机种子点,这个随机种子点太重要,不同的随机种子点会有得到完全不同的结果。K-Means++算法可以用来解决这个问题,其可以有效地选择初始点。
- K-means算法对噪声数据敏感。K-medoids算法在类中选取中心点而不是求类所有点的均值,某种程度上解决了噪声敏感问题。
3. K-means++算法
- 从数据库随机挑一个随机点当“种子点”。
- 对于每个点,我们都计算其和最近的一个“种子点”的距离D(x)并保存在一个数组里,然后把这些距离加起来得到Sum(D(x))。
- 再取一个随机值,用权重的方式来取计算下一个“种子点”。这个算法的实现是先取一个能落在Sum(D(x))中的随机值Random,然后用Random -= D(x),直到其<=0,此时的点就是下一个“种子点”。
- 重复第(2)和第(3)步直到所有的K个种子点都被选出来。
- 进行K-Means算法。
K-means++算法挑选种子点的基本思想是随机挑选并尽量使各种子点间的距离比较远。D(x)数组存储了每个点到离它最近的种子点的距离,若我们在x轴的正轴方向依次表示数组中的元素,则最后的点表示的值就是sum,Random值会落在区间[0,sum]中,并且对于数组元素值大的对应的线段,Random落在其中的概率也越大,即新选出的“种子点”距离已有种子点远的概率也越大。
k-means和k-means++对于初始点选取的差异如下图所示:
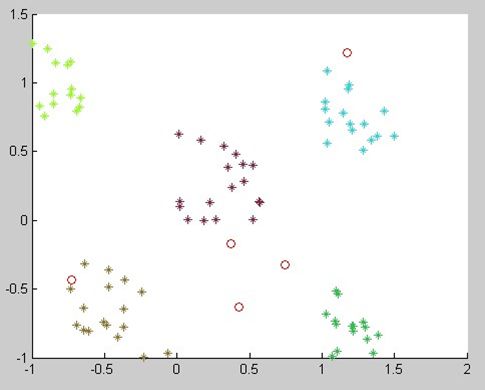
k-means初始点选取
k-means++算法初始点选取
4. K-medoids算法
K-means对噪声很敏感。K-means寻找新的类簇中心点时是对某类簇中所有的样本点维度求平均值。当聚类的样本点中有“噪声”(离群点)时,在计算类簇质点的过程中会受到噪声异常维度的干扰,造成所得质点和实际质点位置偏差过大,从而使类簇发生“畸变“。如:类簇C1中已经包含点A(1,1)、B(2,2)、C(1,2)、D(2,1), 假设N(100,100)为异常点,当它纳入类簇C1时,计算质Centroid((1+2+1+2+100)/5,(1+2+2+1+100)/5)=centroid(21,21),此时可能造成了类簇C1质点的偏移,在下一轮迭代重新划分样本点的时候,将大量不属于类簇C1的样本点纳入,因此得到不准确的聚类结果。K-medoids提出了新的类簇中心点选取方式,改善了噪声的影响。
在K-medoids算法中,每次迭代后的质点都是从聚类的样本点中选取,而选取的标准就是当该样本点成为新的质点后能提高类簇的聚类质量,使得类簇更紧凑。该算法使用绝对误差标准来定义一个类簇的紧凑程度:
![]() (p是空间中的样本点,o_j是类簇 ,c_j的质点)
(p是空间中的样本点,o_j是类簇 ,c_j的质点)
如果某样本点成为质点后,绝对误差能小于原质点所造成的绝对误差,那么K-medoids算法认为该样本点是可以取代原质点的,在一次迭代重计算类簇质点的时候,我们选择绝对误差最小的那个样本点成为新的质点。
K-medoids能有效地处理数据集中的噪声数据,聚类结果优于K-means。但是由于每次选取中心点都要计算样本点到中心点的距离,时间复杂度增高为O(k(n-k)^2 )。因此,K-medoids只适用于有噪声数据的小数据集。