Apache Hadoop2.6.2 小集群搭建
50070###1. 拓扑结构图
4台机器,搭建图如下
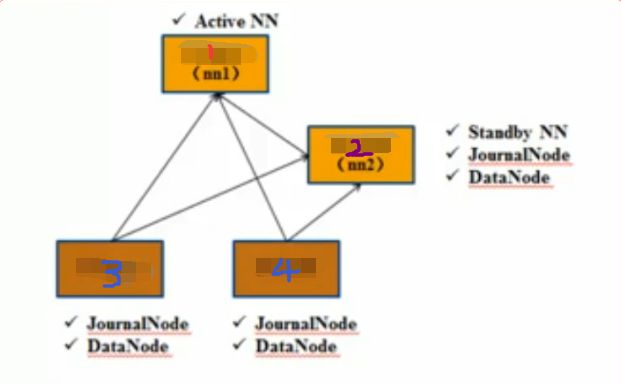
1,2,3,4 分别记做 Hagrid01,Hagrid02,Hagrid03,Hagrid04
NN指的是 Namenode
JN指的是JournalNode
DN指的是DataNode
生产环境下,Active NN 和 Standby NN 都应该单独占用一台机器,这里为了节省资源,StandbyNN上也做了 JN 和 DN
2. 对每台机器创建普通用户
我们一般不在root用户下跑hadoop,因此每台机器都需要创建普通用户
注意,为了方便ssh免密码登录,每台机器的用户名要一样,都为Hagrid01
使得每个机器的存放hadoop解压包的路径一样,
同时配置java的安装目录也要一样!
for 01,02,03,04
useradd -d /Hagrid/ Hagrid01
passwd Hagrid013 对每台机器添加每个机器的hosts 并设置ssh免密码登录
注意!同一个IP只能配置一个域名,不然后面运行命运时会出错!
设置hosts可以方便各个机器访问,后面的配置文件也写些
注意,hosts中本机的host的名字应该和hostname一致 不然后边会报错
注意要永久修改hostname:
要永久修改RedHat的hostname,就修改/etc/sysconfig/network文件,将里面的HOSTNAME这一行修改成HOSTNAME=NEWNAME
然后重启 sudo reboot10.174.xxx.xxx Hagrid01
10.174.xxx.xxx Hagrid02
10.174.xxx.xxx Hagrid03
10.174..xxx.xxx Hagrid04ssh免密码登录,在启动和关闭服务时极大的提升效率
本地Linux用ssh-keygen创建密钥对。
然后使用ssh-copy-id -i /xxx/.ssh/id_rsa.pub xxx@
ssh-kengen
ssh-copy-id -i /xxx/.ssh/id_rsa.pub xxx@<aliyun机器ip>对于本机可以同样设置,但是要注意本机对 /xxx/.ssh的权限需要是700,如果是777则不会成功。
这样在Hagrid01@Hagrid01 上 通过
SSH Hagrid01
SSH Hagrid02
SSH Hagrid03
SSH Hagrid04就可以切换到其他机器,原因是我设置的其他机器的用户名还是Hagrid01,因此ssh默认的用户名是登录登录用户的用户名,所以直接ssh + 域名 即可登录其他机器!
4 将安装包分别放到各个用户的家目录,并解压
测试版本:2.6.2
http://hadoop.apache.org/releases.html
wget http://apache.fayea.com/hadoop/common/hadoop-2.6.2/hadoop-2.6.2.tar.gz
tar -zxf hadoop-2.6.2.tar.gz5 配置
所有的配置文件都在etc/hadoop 下,我们只需在一个节点上配置,然后将配置文件分发到各个机器就行了
5.1 首先修改:
./etc/hadoop/hadoop-env.sh
默认:
export JAVA_HOME=${JAVA_HOME}
修改为绝对路径:
# The java implementation to use.
export JAVA_HOME=/usr/java/jdk1.7.0_45-cloudera5.2 修改core-site.xml
这里的Active NN ,需要手动指定,因为我们没有搭建zookeeper
<property>
<name>fs.defaultFS</name>
<value>hdfs://Hagird01:8020</value>
</property>5.3 修改mapred-site.xml,如果没有则直接创建!
<?xml version="1.0" encoding="UTF-8"?>
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
<property>
<name>mapreduce.jobhistory.address</name>
<value>Hagrid02:10020</value>
</property>
<property>
<name>mapreduce.jobhistory.webapp.address</name>
<value>Hagrid02:19888</value>
</property>
<property>
<name>yarn.app.mapreduce.am.resource.mb</name>
<value>200</value>
</property>
</configuration>jobhistory配置的这两项使得可以启动一个jobhistory server 这样可以在上面看到已经启动的app的历史信息
在 yarn-site.xml 中
yarn.nodemanager.resource.memory-mb配置的是1024mb
而yarn.app.mapreduce.am.resource.mb默认值比较大2048mb
所以这里配置了200mb
5.4 修改 hdfs-site.xml
dfs.nameservices: 命名空间
dfs.ha.namenodes.Hagrid_Hadoop:给两个NN起名字
dfs.namenode.rpc-address:配置RPC地址
dfs.namenode.http-address:配置NN的http地址
dfs.namenode.name.dir:配置元信息存放的目录,可以写多个,逗号分隔, 格式为URI标准格式
dfs.namenode.shared.edits.dir:配置JA的目录,
dfs.ha.automatic-failover.enabled:是否自动切换?
<?xml version="1.0" encoding="UTF-8"?>
<!--Autogenerated by Cloudera Manager-->
<configuration>
<property>
<name>dfs.nameservices</name>
<value>Hagrid_Hadoop</value>
<description>Logical name for this new nameservice</description>
</property>
<property>
<name>dfs.ha.namenodes.Hagrid_Hadoop</name>
<value>nn1,nn2</value>
<description>Unique identifiers for each NameNode in the nameservice</description>
</property>
<property>
<name>dfs.namenode.rpc-address.Hagrid_Hadoop.nn1</name>
<value>Hagrid01:8020</value>
</property>
<property>
<name>dfs.namenode.rpc-address.Hagrid_Hadoop.nn2</name>
<value>Hagrid02:8020</value>
</property>
<property>
<name>dfs.namenode.http-address.Hagrid_Hadoop.nn1</name>
<value>Hagrid01:50070</value>
</property>
<property>
<name>dfs.namenode.http-address.Hagrid_Hadoop.nn2</name>
<value>Hagrid02:50070</value>
</property>
<property>
<name>dfs.namenode.name.dir</name>
<value>/Hagrid/dfs_name,</value>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>/Hagrid/dfs_data,</value>
</property>
<property>
<name>dfs.namenode.shared.edits.dir</name>
<value>qjournal://Hagrid02:8485;Hagrid03:8485;Hagrid04:8485/hadoop_test</value>
</property>
<property>
<name>dfs.replication</name>
<value>3</value>
</property>
<property>
<name>dfs.blocksize</name>
<value>128000000</value>
</property>
<property>
<name>dfs.ha.automatic-failover.enabled</name>
<value>false</value>
</property>
<property>
<name>dfs.journalnode.edits.dir</name>
<value>/Hagrid/journal/</value>
</property>
</configuration>5.5 配置 yarn-site.xml
resourcemanager相关配置
fairscheduler 配置
<?xml version="1.0" encoding="UTF-8"?>
<!--Autogenerated by Cloudera Manager-->
<configuration>
<property>
<name>yarn.resourcemanager.address</name>
<value>Hagrid01:8032</value>
</property>
<property>
<name>yarn.resourcemanager.scheduler.address</name>
<value>Hagrid01:8030</value>
</property>
<property>
<name>yarn.resourcemanager.webapp.address</name>
<value>Hagrid01:8088</value>
</property>
<property>
<name>yarn.resourcemanager.webapp.https.address</name>
<value>Hagrid01:8090</value>
</property>
<property>
<name>yarn.resourcemanager.resource-tracker.address</name>
<value>Hagrid01:8031</value>
</property>
<property>
<name>yarn.resourcemanager.admin.address</name>
<value>Hagrid01:8033</value>
</property>
<property>
<name>yarn.resourcemanager.scheduler.class</name>
<value>org.apache.hadoop.yarn.server.resourcemanager.scheduler.fair.FairScheduler</value>
</property>
<property>
<name>yarn.scheduler.fair.allocation.file</name>
<value>${yarn.home.dir}/etc/hadoop/fairscheduler.xml</value>
</property>
<property>
<name>yarn.nodemanager.local-dirs</name>
<value>/Hagrid/yarn/nm_local</value>
</property>
<property>
<name>yarn.log-aggregation-enable</name>
<value>true</value>
</property>
<property>
<name>yarn.nodemanager.remote-app-log-dir</name>
<value>/tmp/yarn-log</value>
</property>
<property>
<name>yarn.nodemanager.resource.memory-mb</name>
<value>1024</value>
</property>
<property>
<name>yarn.nodemanager.resource.cpu-vcores</name>
<value>1</value>
</property>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
</configuration>
5.5.1 在你配置的这个目录上建立这个文件
etc/hadoop/fairscheduler.xml
<?xml version="1.0"?>
<allocations>
<queue name="queue1">
<minResources>500 mb, 1 vcores </minResources>
<maxResources>1024 mb, 1 vcores </maxResources>
<maxRunningApps>5</maxRunningApps>
<minSharePreemptionTimeout>300</minSharePreemptionTimeout>
<weight>1.0</weight>
<aclSubmitApps>root,yarn,search,hdfs</aclSubmitApps>
</queue>
<queue name="queue2">
<minResources>800 mb, 1 vcores</minResources>
<maxResources>1024 mb, 1 vcores</maxResources>
</queue>
<queue name="queue3">
<minResources>1500 mb, 1 vcores</minResources>
<maxResources>2048 mb, 1 vcores</maxResources>
</queue>
</allocations>5.6 配置slaves
Hagrid02
Hagrid03
Hagrid04slaves的作用:slaves中配置DN的域名,被hadoop-daemons.sh 中调用slaves.sh 脚本的时候使用,这样在使用脚本 sbin/hadoops-daemons.sh start datanode 的时候可以批量的启动datanode。
6 将所有配置文件同步到各个节点上
例如:
scp etc/hadoop/* Hagrid01@Hagrid02:/Hagrid/hadoop-2.6.2/etc/hadoop
scp etc/hadoop/* Hagrid01@Hagrid03:/Hagrid/hadoop-2.6.2/etc/hadoop
scp etc/hadoop/* Hagrid01@Hagrid04:/Hagrid/hadoop-2.6.2/etc/hadoop
7 启动服务
以下操作均在Hadoop部署目录下运行!
7.1 启动Hadoop集群:
在配置的各个JN上启动journalnode服务,并用jps查看是否启动成功
sbin/hadoop-daemon.sh start journalnode为什么会有JN?
hdfs的文件系统的目录是由 fsimage这个文件唯一确定的,在HA方式下这个文件存放在两个NN上,为了在用户更改时及时处理,系统维护了很多 edites log 文件,记录用户对fsimage的修改,两个NN根据edites log 记录,来更新本地的fsimage,这样就能够防止一台NN挂掉之后系统就不可用了。因为是分布式系统,因此,edites log 也是分布式存储(多个备份),因此设计为只要有大部分JN存活,系统就继续能够提供服务,因此,一般JN有至少3个,且为奇数个。
7.2 在nn1 上格式化hdfs
bin/hdfs namenode -format并且启动namenode
sbin/hadoop-daemon.sh start namenode7.3 在nn2 上同步nn1的元数据并启动
bin/hdfs namenode -bootstrapStandby
sbin/hadoop-daemon.sh start namenode此时,在nn1上查看
http://Hagrid01:50070
和
http://Hagrid02:50070
都是standby状态
standby状态下的NN是不能对外提供服务的。
7.4 将nn1切换为active状态
在nn1 或者nn2 上
bin/hdfs haadmin -transitionToActive nn1此时,在nn1上查看
http://Hagrid01:50070 发现已经变为Action
7.5 启动DN
sbin/hadoop-daemons.sh start datanode这个命令可以从主节点启动其他所有节点的datanode
如果使用
sbin/hadoop-daemon.sh start datanode那么只启动本机的这个节点的DN,需要手动启动其他机器的DN
7.5.1 玩玩dfs
创建文件:
bin/hadoop fs -mkdir /home上传文件:
bin/hadoop fs -put README.txt /home
查看上传结果
bin/hadoop fs -ls /home7.6 启动yarn ,不分步做了,直接启动全部
sbin/start-yarn.shjps 可以看到 Resourcemanager 已经启动成功
查看Web的yarn server
http://Hagrid01:8088
7.7 玩玩yarn
让hadoop计算π值!
bin/hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-examples-2.6.2.jar pi 2 1000这是使用蒙托卡罗模拟采样算法计算π值,有兴趣的可以找找相关资料!
8 停止集群
sbin/stop-yarn.sh
sbin/stop-dfs.sh
9 再次启动
只做7中除了格式化数据的命令之外的命令即可!