Java进阶学习第六天——DOM4J入门
| 文档版本 | 开发工具 | 测试平台 | 工程名字 | 日期 | 作者 | 备注 |
|---|---|---|---|---|---|---|
| V1.0 | 2016.04.17 | lutianfei | none |
XML约束——schema
XML Schema 也是一种用于定义和描述 XML 文档结构与内容的模式语言,其出现是为了克服 DTD 的局限性。
schema和DTD的对比(面试题):
- Schema符合XML语法结构。
- DOM、SAX等XML API很容易解析出XML Schema文档中的内容。
- XML Schema对
名称空间支持得非常好。 - XML Schema比XML DTD支持更多的数据类型,并支持用户自定义新的数据类型。
- XML Schema定义约束的能力非常强大,可以对XML实例文档作出细致的语义限制。
- XML Schema不能像DTD一样定义实体,比DTD更复杂,但Xml Schema现在已是w3c组织的标准,它正逐步取代DTD。
Schema一些概念
- XML Schema 文件自身就是一个XML文件,但它的扩展名通常为
.xsd 和XML文件一样,一个XML Schema文档也必须有一个根结点,但这个根结点的名称为
schema应用schema约束 开发xml 过程
- 编写了一个XML Schema约束文档后,通常需要把这个文件中声明的元素绑定到一个
URI地址上,这个URI地址叫namespace名称空间,以后XML文件就可以通过这个URI(即名称空间)引用绑定指定名称空间的元素。
Schema开发步骤
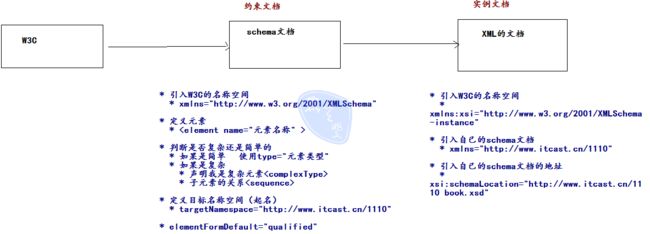
开发schema约束文档
- 引入W3C的名称
- 在
根节点上,使用属性xmlns(xml namespace)
xmlns="http://www.w3.org/2001/XMLSchema"
- 在
- 定义元素
<element name="书架"></element>
- 判断是否是复杂还是简单的元素
- 如果是简单 在element有属性
type="数据的类型" - 如果是复杂
- 声明标签是复杂的元素
<complexType> - 子元素之间的关系 eg:有序
<sequence>
- 声明标签是复杂的元素
- 如果是简单 在element有属性
- 起名:
targetNamespace目标名称空间
- 值是任意的:
http://www.itcast.cn/1110
- 值是任意的:
- elementFormDefault :
- qualified(使用) :质量好的
- unqualified :质量不好的
- 引入W3C的名称
在XML文档中引入自己编写的schema文档
- 引入W3C名称空间,我是实例文档。
xmlns="http://www.w3.org/2001/XMLSchema-instance"
- 引入自己编写的schema的文档
xmlns="http://www.itcast.cn/1110"- 问题:元素上不能有相同的属性名称
- 解决:起别名 eg:aa
- 技巧:在下面出现标签的概率小起别名
- 引入自己编写的schema文档的地址
schemaLocation属性是W3C提供的,如果W3C名称空间要是有别名的话,先把别名写上。xsi:schemaLocation="名称空间 schema文件的地址"
- 编写属性
<attribute name="出版社" type="string" use="required" ></attribute>- name 属性名称
- type 属性类型
- user 属性约束
- 引入W3C名称空间,我是实例文档。
// schema 文件:
<?xml version="1.0" encoding="UTF-8"?>
<schema xmlns="http://www.w3.org/2001/XMLSchema" targetNamespace="http://www.itcast.cn/1110" elementFormDefault="qualified">
<!-- 复杂元素 -->
<element name="书架">
<!-- 复杂元素 -->
<complexType>
<!-- 有顺序的 -->
<sequence maxOccurs="unbounded">
<element name="书">
<!-- 复杂的元素 -->
<complexType>
<!-- 有顺序的 -->
<sequence>
<!-- 简单元素 -->
<element name="书名" type="string"></element>
<element name="作者" type="string"></element>
<element name="售价" type="double"></element>
<element name="简介" type="string"></element>
</sequence>
<!-- 书的属性 -->
<attribute name="出版社" type="string" use="required" ></attribute>
</complexType>
</element>
</sequence>
</complexType>
</element>
</schema>// xml 文件:
<?xml version="1.0" encoding="UTF-8" standalone="no"?>
<书架 xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xmlns="http://www.itcast.cn/1110" xsi:schemaLocation="http://www.itcast.cn/1110 book.xsd" >
<书 出版社="清华出版社">
<书名>javaweb开发大全</书名>
<作者>班长</作者>
<售价>99.8</售价>
<简介>这是不错啊</简介>
</书>
<书 出版社="清华出版社">
<书名>javaweb开发大全</书名>
<作者>班长</作者>
<售价>99.8</售价>
<简介>这是不错啊</简介>
</书>
<书 出版社="清华出版社">
<书名>javaweb开发大全</书名>
<作者>班长</作者>
<售价>99.8</售价>
<简介>这是不错啊</简介>
</书>
</书架>名称空间的概念
- 在XML Schema中,每个约束模式文档都可以被赋以一个唯一的名称空间,名称空间用一个唯一的
URI(Uniform Resource Identifier,统一资源标识符)表示。 - 在Xml文件中书写标签时,可以通过名称空间声明(xmlns),来声明当前编写的标签来自哪个Schema约束文档。如:
<itcast:书架 xmlns:itcast=“http://www.itcast.cn”>
<itcast:书>……</itcast:书>
</itcast:书架>此处使用itcast来指向声明的名称,以便于后面对名称空间的引用。
注意:名称空间的名字语法容易让人混淆,尽管以 http:// 开始,那个 URL** 并不指向一个包含模式定义的文件**。事实上,这个
URL:http://www.itcast.cn根本没有指向任何文件,只是一个分配的名字。
使用名称空间引入Schema
- 为了在一个XML文档中声明它所遵循的Schema文件的具体位置,通常需要在Xml文档中的根结点中使用
schemaLocation属性来指定,例如:
<itcast:书架 xmlns:itcast="http://www.itcast.cn"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation=“http://www.itcast.cn book.xsd">- schemaLocation此属性有两个值。
- 第一个值是需要使用的命名空间。
- 第二个值是供命名空间使用的 XML schema 的位置,两者之间用空格分隔。
- 注意,在使用schemaLocation属性时,也需要指定该属性来自哪里。
XML的编程
在使用 DOM 解析 XML 文档时,需要读取整个 XML 文档,在内存中构架代表整个 DOM 树的Doucment对象,从而再对XML文档进行操作。此种情况下,如果 XML 文档特别大,就会消耗计算机的大量内存,并且容易导致内存溢出。
SAX解析允许在读取文档的时候,即对文档进行处理,而不必等到整个文档装载完才会文档进行操作。
JAXP的SAX解析
只能做查询,不能做增删改。
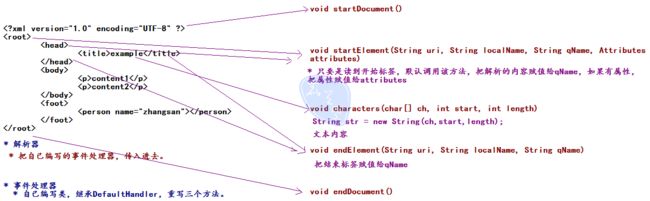
SAX解析过程
- 解析器
- 获取解析器的工厂
- 获取解析器对象
- 解析XML(XML的文件的地址,事件处理器)
- 事件处理器
- 自己编写的类,需要继承DefalutHandler类,重写三个方法。
- startElement()
- characters()
- endElement()
- 解析器
SAX的解析原理:
- 解析器采用SAX方式在解析某个XML文档时,它只要解析到XML文档的一个组成部分,都会去调用事件处理器的一个方法,解析器在调用事件处理器的方法时,会把当前解析到的xml文件内容作为方法的参数传递给事件处理器。
- 事件处理器由程序员编写,程序员通过事件处理器中方法的参数,就可以很轻松地得到sax解析器解析到的数据,从而可以决定如何对数据进行处理
- JAXP 的SAX解析案例
package cn.itcast.jaxp.sax;
import javax.xml.parsers.ParserConfigurationException;
import javax.xml.parsers.SAXParser;
import javax.xml.parsers.SAXParserFactory;
import org.xml.sax.Attributes;
import org.xml.sax.SAXException;
import org.xml.sax.helpers.DefaultHandler;
/** * SAX的入门 * @author Administrator * */
public class JaxpSaxTest {
public static void main(String[] args) {
try {
run1();
} catch (Exception e) {
e.printStackTrace();
}
}
/** * 获取所有的解析的内容 * @throws Exception * @throws ParserConfigurationException */
public static void run1() throws Exception{
// 获取SAX的解析器工厂
SAXParserFactory factory = SAXParserFactory.newInstance();
// 获取解析器
SAXParser parser = factory.newSAXParser();
// 解析
parser.parse("src/book2.xml", new MyHandler2());
}
}
/** * 获取作者标签的文本内容 * */
class MyHandler2 extends DefaultHandler{
// 如果解析到作者标签的时候,flag设置成true
private boolean flag = false;
private int count = 0;
/** * 默认解析开始标签,默认调用该方法 */
public void startElement(String uri, String localName, String qName,
Attributes attributes) throws SAXException {
// 如果要是作者标签,flag设置成true
if("作者".equals(qName)){
flag = true;
count++;
}
}
/** * 能控制characters的输出,我只在解析作者标签的时候,才打印 */
public void characters(char[] ch, int start, int length)
throws SAXException {
// 如果flag是true,就打印
// 每一次都打印
if(flag && count == 1){
String str = new String(ch,start,length);
System.out.println(str);
}
}
/** * */
public void endElement(String uri, String localName, String qName)
throws SAXException {
// flag恢复成false
flag = false;
}
}
/** * 自己事件处理器 * 重写三方法 * @author Administrator * */
class MyHandler extends DefaultHandler{
/** * 只要一解析到开始标签的时候,默认调用该方法,把解析的内容赋值给参数。 */
public void startElement(String uri, String localName, String qName,
Attributes attributes) throws SAXException {
System.out.println("开始标签:"+qName);
}
/** * 只要解析到文本的内容,默认调用该方法 */
public void characters(char[] ch, int start, int length)
throws SAXException {
String str = new String(ch,start,length);
System.out.println(str);
}
/** * 解析到结束标签的时候,默认调用方法,把解析的内容赋值给参数。 */
public void endElement(String uri, String localName, String qName)
throws SAXException {
System.out.println("结束标签:"+qName);
}
}
DOM4J的解析
- Dom4j是一个简单、灵活的开放源代码的库。Dom4j是由早期开发JDOM的人分离出来而后独立开发的。与JDOM不同的是,dom4j使用接口和抽象基类,虽然Dom4j的API相对要复杂一些,但它提供了比JDOM更好的灵活性。
- Dom4j是一个非常优秀的Java XML API,具有性能优异、功能强大和极易使用的特点。现在很多软件采用的Dom4j,例如Hibernate,包括sun公司自己的JAXM也用了Dom4j。
- 使用Dom4j开发,需下载dom4j相应的jar文件。
- 把
dom4j-1.6.1.jar导入到工程中。 - WEB项目:复制dom4j-1.6.1.jar到 WebRoot – WEB-INF – lib里面。就ok。
- 非WEB项目 导入后如果未出现
奶瓶标志,点中jar包右键选择:Build path –> Add to Build Path。
查找标签文本
- 想要查找内容,需要一层一层去查找内容,通过根节点去查找字节点,再查找子节点的子节点)
- 具体实现
- 创建解析器 new SAXReader()
- 解析xml read()
- 获取根节点 getRootElement()
- 获取所有的指定标签的集合 root.elements(标签名)
- 返回List集合,可以遍历集合或者getIndex()获取Element对象
- 获取文本 getText()
添加子节点
- 在指定的节点中新增节点
- 具体实现
- 创建解析器 new SAXReader()
- 解析xml read()
- 获取根节点 getRootElement()
- 获取所有的指定标签的集合 root.elements(标签名)
- 直接调用addElement()设置子节点。
- 使用setText()设置文本
- 回写xml文件
在指定位置添加子节点
- 创建元素标签节点 DocumentHelper.createElement()
- 设置文本 setText()
- 获取某个标签下的所有子节点 elements(),返回list集合
- 通过 list.add(index, element)方法在内存中加入子元素
- 回写xml文件
修改节点文本和删除节点
修改指定节点的文本内容
- 找到指定的节点 elements()
- 修改文本内容 setText()
删除节点
- 找到要删除的节点
- 通过父节点调用 remove()方法删除
DOM4J对XPATH的支持
- 导入包:
jaxen-1.1-beta-6.jar 使用方式:
selectNodes("/AAA")返回集合selectSingleNode()一个Node对象- 参数就是xpath的语法
/AAA/BBB获取BBB的节点//BBB无论层级关系,找到BBB的节点*代表是所有/AAA/BBB[1]找到BBB的第一个/AAA/BBB[last()]最后一个@属性
DOM4J练习
package cn.itcast.dom4j;
import java.io.FileOutputStream;
import java.util.List;
import org.dom4j.Document;
import org.dom4j.DocumentHelper;
import org.dom4j.Element;
import org.dom4j.Node;
import org.dom4j.io.OutputFormat;
import org.dom4j.io.SAXReader;
import org.dom4j.io.XMLWriter;
/** * DOM4J的解析XML * @author Administrator * */
public class Dom4jTest {
public static void main(String[] args) {
try {
run6();
} catch (Exception e) {
e.printStackTrace();
}
}
/** * 对XPATH的支持 * @throws Exception */
public static void run6() throws Exception{
// 获取解析器对象
SAXReader reader = new SAXReader();
// 解析XML
Document document = reader.read("src/book2.xml");
// List<Node> list = document.selectNodes("/书架/书/作者");
List<Node> list = document.selectNodes("//作者");
Node author2 = list.get(1);
System.out.println(author2.getText());
}
/** * 修改文本内容 * @throws Exception */
public static void run5() throws Exception{
// 获取解析器对象
SAXReader reader = new SAXReader();
// 解析XML
Document document = reader.read("src/book2.xml");
// 获取根节点
Element root = document.getRootElement();
// 获取狗的节点
Element book2 = (Element) root.elements("书").get(1);
Element dog = book2.element("狗");
dog.setText("小狗");
// 回写
// 回写
OutputFormat format = OutputFormat.createPrettyPrint();
// 回写
XMLWriter writer = new XMLWriter(new FileOutputStream("src/book2.xml"),format);
writer.write(document);
writer.close();
}
/** * 删除子节点 * 删除第二本书下的猫节点 */
public static void run4() throws Exception{
// 获取解析器对象
SAXReader reader = new SAXReader();
// 解析XML
Document document = reader.read("src/book2.xml");
// 获取根节点
Element root = document.getRootElement();
// 获取猫
Element book2 = (Element) root.elements("书").get(1);
Element cat = book2.element("猫");
// 通过猫获取猫的父节点
// cat.getParent();
// 通过父节点删除猫
book2.remove(cat);
// 回写
OutputFormat format = OutputFormat.createPrettyPrint();
// 回写
XMLWriter writer = new XMLWriter(new FileOutputStream("src/book2.xml"),format);
writer.write(document);
writer.close();
}
/** * 在第二本书的作者标签之前添加团购价的标签 * @throws Exception */
public static void run3() throws Exception{
// List
// 获取解析器对象
SAXReader reader = new SAXReader();
// 解析XML
Document document = reader.read("src/book2.xml");
// 获取根节点
Element root = document.getRootElement();
// 获取第二本书
Element book2 = (Element) root.elements("书").get(1);
// 获取书下的所有子节点,返回List集合
List<Element> list = book2.elements();
// 创建元素对象 DocumentHelper.createElement("狗")
Element dog = DocumentHelper.createElement("狗");
dog.setText("大狗");
// list.add(index,Element);
list.add(1, dog);
OutputFormat format = OutputFormat.createPrettyPrint();
// 回写
XMLWriter writer = new XMLWriter(new FileOutputStream("src/book2.xml"),format);
writer.write(document);
writer.close();
}
/** * 在第二本书下添加子节点 */
public static void run2() throws Exception{
// 获取解析器对象
SAXReader reader = new SAXReader();
// 解析XML,返回Document对象
Document document = reader.read("src/book2.xml");
// 获取根节点
Element root = document.getRootElement();
// 获取第二本书
Element book2 = (Element) root.elements("书").get(1);
// 可以直接在第二本书下添加子节点,设置文本内容
book2.addElement("猫").setText("我是猫");
// 回写
// 创建漂亮的格式
OutputFormat format = OutputFormat.createPrettyPrint();
//OutputFormat format = OutputFormat.createCompactFormat();
// 设置编码
format.setEncoding("UTF-8");
// 回写类
XMLWriter writer = new XMLWriter(new FileOutputStream("src/book2.xml"),format);
// 回写了文档对象
writer.write(document);
// 关闭流
writer.close();
}
/** * 获取第二本书作者的文本内容 * @throws Exception */
public static void run1() throws Exception{
// 获取解析器对象
SAXReader reader = new SAXReader();
// 解析XML,返回Document对象
Document document = reader.read("src/book2.xml");
// 获取根节点(书架标签)
Element root = document.getRootElement();
// 获取书的节点,获取第二本书
List<Element> books = root.elements("书");
Element book2 = books.get(1);
// 获取作者的标签
Element author2 = book2.element("作者");
// 获取文本内容
System.out.println(author2.getText());
}
}
扩展练习
- 通过XML管理学生的信息