机器学习笔记02:多元线性回归、梯度下降和Normal equation
在《机器学习笔记01》中已经讲了关于单变量的线性回归以及梯度下降法。今天这篇文章作为之前的扩展,讨论多变量(特征)的线性回归问题、多变量梯度下降、Normal equation(矩阵方程法),以及其中需要注意的问题。
单元线性回归
首先来回顾一下单变量线性回归的假设函数:
| Size( feet2 ) | Price( $ 1000) |
|---|---|
| 2104 | 460 |
| 1416 | 232 |
| 1534 | 315 |
| 852 | 178 |
| … | … |
我们的假设函数为 hθ(x)=θ0+θ1x
多元线性回归
下面介绍多元线性回归(Linear Regression with Multiple features/variables)。同样以预测房价为例,假设我们对房价的预测涉及到4个因素:Size、Number of bedrooms、Number of floors、Age of house。假设我们的训练集如下:
| Size( feet2 ) | Number of bedrooms | Number of floors | Age of house(years) | Price( $ 1000) |
|---|---|---|---|---|
| 2104 | 5 | 1 | 43 | 460 |
| 1416 | 3 | 2 | 40 | 232 |
| 1534 | 3 | 2 | 30 | 315 |
| 852 | 2 | 1 | 36 | 178 |
| … | … | … | … | … |
符号说明(Notation):
| 符号 | 含义 |
|---|---|
| n | number of features(特征的数量,上表中为4) |
| x(i) | input(features) of ith training example(第 i 组训练数据,比如 x2 表示上表中第二行) |
| xij | value of feature j in ith training example(第 i 组训练接的第 j 个特征值,比如 x32 表示上表中的第三行第二列的值2) |
| m | number of training examples(训练集样本的数量,比如上表为4) |
1、假设函数(Hypothesis function)
既然是线性回归,我们的假设函数当然应该是一条直线:
为了方便,我们记
所以有
其中, θT 是一个规模为 1×(n+1) 的矩阵, X 是一个规模为 (n+1)×1 的矩阵。假设函数的说明就到这里,下面我们来看看多变量的梯度下降法。
2、多变量梯度下降(Gradient descent for Multiple Variables)
1.假设函数(Hypothesis function):
2.误差函数(Cost function):
注意:上面三种形式都是等价的。
在单元线性回归中,我们只对 θ0 和 θ1 使用了梯度下降法,在多元变量的梯度下降中,我们将对每个 θ 都求偏导。其形式如下:
Repeat until convergence:{ //重复直到收敛
注意:在一次迭代过程中,必须同时更新每个 θ 。例如不能在更新了 θ1 之后,就把新的 θ1 用于更新后面的 θ2 ,而应该使用上一次迭代产生的 θ1 来更新这一次迭代中的 θ2 。
上面的
在执行足够次数的迭代 (iteration) 之后,我们就能取得最佳的 θj 的值。但是在特征(features)数量很大的情况下会遇到一个问题,那就是梯度下降算法可能会非常的慢,下面来看看原因与解决办法。
3、特征缩放(Feature scaling)
我们来考虑这样一个实例:还是预测房价,但是假设每个训练样本有两个特征:
| Size( feet2 ) | Number of bedrooms | |
|---|---|---|
| Range | 0-2000 | 1-5 |
如果直接进行梯度下降的话,速度可能会非常的慢。至于为什么我们先来看看 J(θ) 的等高线图(contour):

假如只考虑假设函数的 θ1 和 θ2 ,令
特征缩放(feature scaling),顾名思义,就是将特征的取值范围进行缩放,我们采用如下公式对特征进行缩放(还是以上面那个例子来解释):
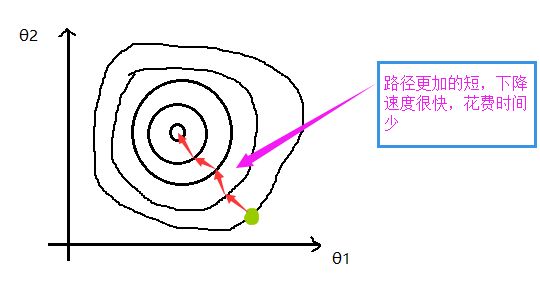
由此可见,缩放之后的等高线图更接近一个圆,而不是一个很扁的椭圆,这样梯度下降法将运行得更加快速。
另外需要说的是,我们一般会希望将每个特征的范围都缩放到 -1 与 1 之间,并且对于偏离这个范围不太大的特征不进行缩放(当然也可以按自己喜好进行缩放)。例如:
| Origin range | Need feature scaling? |
|---|---|
| 0≤x1≤3 | not need |
| −2≤x2≤0.5 | not need |
| −100≤x3≤100 | need |
| −0,0001≤x4≤0.0001 | need |
上面的need和not need并没有一个准确的界限,大可酌情而定。
3、均值归一化(Mean normalization)
正如上面提到的,我们希望将每个特征的范围都缩放到 -1 与 1 之间,并且对于偏离这个范围不太大的特征不进行缩放。
Mean normalization的具体方法是用 x(i)j−μj 来代替 x(i)j 以将特征的范围大致的约束在0的附近(一般为-1到1),注意我们不必对 x(i)0=1 进行归一化。其中 μj 表示特征 xj 的平均值。我们可将均值归一化公式总结为:
4、学习速率 α (Learning rate α )
关于学习速率 α 我们需要注意两点:
1.确保梯度下降(gradient descent)能够正确地工作:
一方面,我们先来思考一下梯度下降的速率,先来看一个关于梯度下降的图:
注意到,在100次迭代之后,误差还是很大的,在200次迭代之后误差任然很可观,但是在300次迭代之后,误差算是比较小了,在400次迭代之后,误差也比较令人满意。但这里我们的关注点在300和400这两个阶段上,300次迭代之后,我们发现误差还比较令人满意,而却需要花费额外的100次才能使得误差好那么一点点,所以我们可以声明一个低度下降的下界,比如将 10−3 作为一个下降的下界来避免不必要的额外计算花费。但是,这个下界通常是很难选取的。
另一方面,来看看,梯度下降无法正常工作的情况,看图:

出现这三种情况的原因都是因为学习速率 α 过大,只要逐渐减小学习速率 α 直到正常工作即可。至于为什么是学习速率 α 过大,参考 《机器学习笔记01》。可以明确的一点是,只要 α 足够小, J(θ) 会在每次迭代中都减小,但是如果 α 太小的话,梯度下降将会变得很慢。所以我么可以总结如下:
| Causes | Results |
|---|---|
| If α is too small | Slow convergence |
| If α is too large | J(θ) may not decrease on every iteration; may not converge |
2.如何选取一个合适的 α :
如何选取一个合适的 α 关乎到 Gradient descent 的速率。一般的方法如下:
在自己选定的一个大致范围内进行debug。一般间隔为三倍的关系:
5、特征和多项式回归(Features and Polynomial Regression)
这部分只是额外的一些关于选择假设函数的东西。下面看个例子,还是房价预测。

假设函数为:
假设训练数据的分布如下:
我们可能选则次数更高的函数比如二次函数(红色)
再来看看三次函数(绿色)
以上就是关于这个例子的一些候选函数。
另外,我们需要注意一下特征缩放。加入有一个假设函数为:
| features | range |
|---|---|
| x1=(size) | 1−1,000 |
| x2=(size)2 | 1−1,000,000 |
| x3=(size)3 | 1−109 |
在进行feature scaling的时候一定要注意除以对应的正确的range。
5、Normal equation(矩阵方程法)
由于篇幅限制,而且normal equation内容较多,所以暂时留个位置在这里,或者会新开一篇。
上面就是多元变量线性回归的大概内容,希望能帮助到大家。如有错误,期望您能纠正,留言或者是e-mail:[email protected]
——– 转载请注明出处——–