MapReduce教程(二)MapReduce框架Partitioner分区
MapReduce教程(二)MapReduce框架Partitioner分区
1 Partitioner分区
1.1 Partitioner分区描述
在进行MapReduce计算时,有时候需要把最终的输出数据分到不同的文件中,按照手机号码段划分的话,需要把同一手机号码段的数据放到一个文件中;按照省份划分的话,需要把同一省份的数据放到一个文件中;按照性别划分的话,需要把同一性别的数据放到一个文件中。我们知道最终的输出数据是来自于Reducer任务。那么,如果要得到多个文件,意味着有同样数量的Reducer任务在运行。Reducer任务的数据来自于Mapper任务,也就说Mapper任务要划分数据,对于不同的数据分配给不同的Reducer任务运行。Mapper任务划分数据的过程就称作Partition。负责实现划分数据的类称作Partitioner。
1.2 MapReduce运行原理
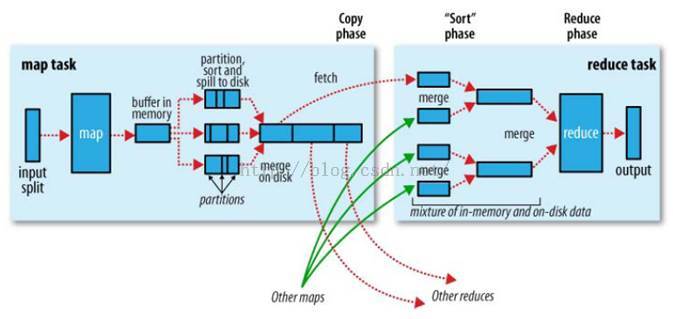
MapReduce流程图 - 1.1
1.3 数据需求
将文件input_data.txt中的用户数据,根据用户的手机号,按照手机号进行分区。
附件地址链接:http://download.csdn.net/detail/yuan_xw/9459721
1.4 实现步骤
1、 编写UserMapper类,分析用户数据信息。
2、 编写UserReducer类,计算用户的年收数据信息。
3、 编写ProviderPartitioner类,Partitioner组件可以让Map对Key进行分区,从而可以根据不同的key来分发到不同的reduce中去处理。
1.5 UserMapper代码编写
UserMapper类,读取和分析用户数据。
package com.hadoop.mapreduce;
import java.io.IOException;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.NullWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper;
import entity.UserEntity;
/*
* 继承Mapper类需要定义四个输出、输出类型泛型:
* 四个泛型类型分别代表:
* KeyIn Mapper的输入数据的Key,这里是每行文字的起始位置(0,11,...)
* ValueIn Mapper的输入数据的Value,这里是每行文字
* KeyOut Mapper的输出数据的Key,这里是序列化对象UserEntity
* ValueOut Mapper的输出数据的Value,不返回任何值
*
* Writable接口是一个实现了序列化协议的序列化对象。
* 在Hadoop中定义一个结构化对象都要实现Writable接口,使得该结构化对象可以序列化为字节流,字节流也可以反序列化为结构化对象。
* LongWritable类型:Hadoop.io对Long类型的封装类型
*/
public class UserMapper extends Mapper<LongWritable, Text, UserEntity, NullWritable> {
private UserEntity userEntity = new UserEntity();
@Override
protected void map(LongWritable key, Text value, Mapper<LongWritable, Text, UserEntity, NullWritable>.Context context)
throws IOException, InterruptedException {
//将每行的数据以空格切分数据,获得每个字段数据 1 135****9365 林*彬 2484 北京市昌平区北七家东三旗村
String[] fields = value.toString().split("\t");
// 赋值userEntity
userEntity.set(Integer.parseInt(fields[0]), fields[1], fields[2],Double.parseDouble(fields[3]), fields[4],0.00);
// 将对象序列化
context.write(userEntity,NullWritable.get());
}
}
1.6 UserReducer代码编写
UserReducer类,计算用户的年收数据信息。
package com.hadoop.mapreduce;
import java.io.IOException;
import org.apache.hadoop.io.NullWritable;
import org.apache.hadoop.mapreduce.Reducer;
import entity.UserEntity;
/*
* Reducer需要定义四个输出、输出类型泛型:
* 四个泛型类型分别代表:
* KeyIn Reducer的输入数据的Key,这里是序列化对象UserEntity
* ValueIn Reducer的输入数据的Value,这里是NullWritable
* KeyOut Reducer的输出数据的Key,这里是序列化对象UserEntity
* ValueOut Reducer的输出数据的Value,NullWritable
*/
public class UserReducer extends Reducer<UserEntity, NullWritable, UserEntity, NullWritable>{
@Override
protected void reduce(UserEntity userEntity, Iterable<NullWritable> values,
Reducer<UserEntity, NullWritable, UserEntity, NullWritable>.Context context)
throws IOException, InterruptedException {
// 年收入 = 月收入 * 12 四舍五入
String yearIncome = String.format("%.2f", userEntity.getMonthIncome() * 12);
userEntity.setYearIncome(Double.parseDouble(yearIncome));
context.write(userEntity, NullWritable.get());
}
}
1.7 ProviderPartitioner代码编写
Partitioner用于划分键值空间(key space)。
Partitioner组件可以让Map对Key进行分区,从而可以根据不同的key来分发到不同的reduce中去处理。分区的数量与一个作业的reduce任务的数量是一样的。它控制将中间过程的key(也就是这条记录)应该发送给m个reduce任务中的哪一个来进行reduce操作。HashPartitioner是默认的Partitioner。
package com.hadoop.mapreduce;
import java.util.HashMap;
import java.util.Map;
import org.apache.hadoop.io.NullWritable;
import org.apache.hadoop.mapreduce.lib.partition.HashPartitioner;
import entity.UserEntity;
/*
* Partitioner用于划分键值空间(key space)。
* Partitioner组件可以让Map对Key进行分区,从而可以根据不同的key来分发到不同的reduce中去处理。
* 分区的数量与一个作业的reduce任务的数量是一样的。
* 它控制将中间过程的key(也就是这条记录)应该发送给m个reduce任务中的哪一个来进行reduce操作。
* HashPartitioner是默认的 Partitioner。
*/
/**
* 继承抽象类Partitioner,实现自定义的getPartition()方法
* 通过job.setPartitionerClass()来设置自定义的Partitioner;
*/
public class ProviderPartitioner extends HashPartitioner<UserEntity, NullWritable> {
// 声明providerMap,并且在static静态块中初始化
private static Map<String, Integer> providerMap = new HashMap<String, Integer>();
static {
providerMap.put("130", 0);
providerMap.put("133", 0);
providerMap.put("134", 0);
providerMap.put("135", 0);
providerMap.put("136", 0);
providerMap.put("137", 0);
providerMap.put("138", 0);
providerMap.put("139", 0);
providerMap.put("150", 1);
providerMap.put("151", 1);
providerMap.put("153", 1);
providerMap.put("158", 1);
providerMap.put("159", 1);
providerMap.put("170", 2);
providerMap.put("180", 3);
providerMap.put("181", 3);
providerMap.put("183", 3);
providerMap.put("185", 3);
providerMap.put("186", 3);
providerMap.put("187", 3);
providerMap.put("188", 3);
providerMap.put("189", 3);
}
/**
* 实现自定义的getPartition()方法,自定义分区规则
*/
@Override
public int getPartition(UserEntity key, NullWritable value, int numPartitions) {
String prefix = key.getMobile().substring(0, 3);
return providerMap.get(prefix);
}
}
1.8 UserAnalysis代码编写
UserAnalysis类,程序执行入口类。
package com.hadoop.mapreduce;
import java.io.IOException;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.NullWritable;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import entity.UserEntity;
public class UserAnalysis {
public static void main(String[] args) throws IOException, ClassNotFoundException, InterruptedException {
// 创建job对象
Job job = Job.getInstance(new Configuration());
// 指定程序的入口
job.setJarByClass(UserAnalysis.class);
// 指定自定义的Mapper阶段的任务处理类
job.setMapperClass(UserMapper.class);
job.setMapOutputKeyClass(UserEntity.class);
job.setMapOutputValueClass(NullWritable.class);
// 数据HDFS文件服务器读取数据路径
FileInputFormat.setInputPaths(job, new Path("/mapreduce/partitioner/input_data.txt"));
// 指定自定义的Reducer阶段的任务处理类
job.setReducerClass(UserReducer.class);
// 设置最后输出结果的Key和Value的类型
job.setOutputKeyClass(UserEntity.class);
job.setOutputValueClass(NullWritable.class);
// 设置定义分区的处理类
job.setPartitionerClass(ProviderPartitioner.class);
// 默认ReduceTasks数是1
// 我们对手机号分成4类,所以应该设置为4
job.setNumReduceTasks(4);
// 将计算的结果上传到HDFS服务
FileOutputFormat.setOutputPath(job, new Path("/mapreduce/partitioner/output_data"));
// 执行提交job方法,直到完成,参数true打印进度和详情
job.waitForCompletion(true);
System.out.println("Finished");
}
}
2 安装部署
2.1 生成JAR包
1、 选择hdfs项目->右击菜单->Export…,在弹出的提示框中选择Java下的JAR file:
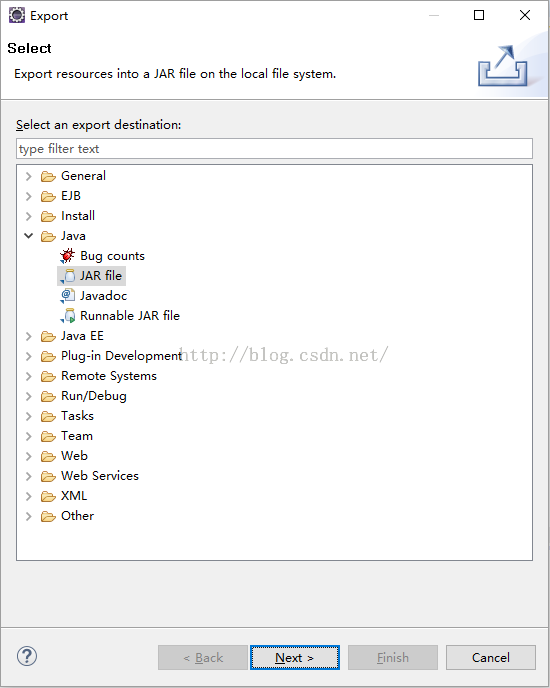
2、 选择hdfs项目->右击菜单->Export…,在弹出的提示框中选择Java下的JAR file:
3、 设置程序的入口,设置完成后,点击Finish:
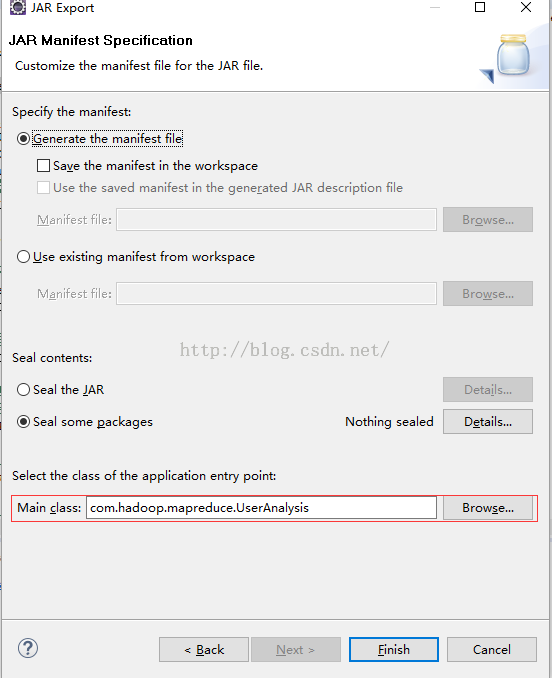
4、 成生UserAnalysis.jar如下文件,如下图:

2.2 执行JAR运行结果
1、 打开Xft软件,将E:盘的UserAnalysis.jar、input_data.txt文件上传到Linux/home路径下:
2、 执行命令:
创建两个文件夹:
hadoop fs -mkdir /mapreduce/
hadoop fs -mkdir /mapreduce/partitioner
上传input_data.txt文件:
hadoop fs -put /home/input_data.txt /mapreduce/partitioner
3、 执行JAR包:
切换目录命令:cd /home/
运行JAR包:hadoop jar UserAnalysis.jar
4、 查看执行结果:
查看目录命令:hadoop fs -ls R/mapreduce/partitioner/output_data
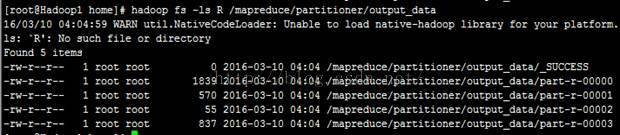
5、 查看文件
查看part-r-00000文件命令:hadoop fs -cat/mapreduce/partitioner/output_data/part-r-00000
查看part-r-00001文件命令:hadoop fs -cat/mapreduce/partitioner/output_data/part-r-00001
查看part-r-00002文件命令:hadoop fs -cat/mapreduce/partitioner/output_data/part-r-00002
查看part-r-00003文件命令:hadoop fs -cat/mapreduce/partitioner/output_data/part-r-00003
2.3 相关下载
1、 UserAnalysis.jar包下载地址:http://download.csdn.net/detail/yuan_xw/9459711
2、 input_data.txt文件下载地址:http://download.csdn.net/detail/yuan_xw/9459721
3、 源代码下载地址:http://download.csdn.net/detail/yuan_xw/9459707
——厚积薄发(yuanxw)