Spark MLlib Deep Learning Neural Net(深度学习-神经网络)1.3
Spark MLlib Deep Learning Neural Net(深度学习-神经网络)1.3
http://blog.csdn.net/sunbow0
第一章Neural Net(神经网络)
3 实例
3.1 测试数据
3.1.1 测试函数
采用智能优化算法的经典测试函数,如下:
(1)Sphere Model
函数表达式

搜索范围
![]()
全局最优值
函数简介:此函数为非线性的对称单峰函数,不同维之间是不可分离的。此函数相对比较简单,大多数算法都能够轻松地达到优化效果,其主要用于测试算法的寻优精度。下图给出了此函数维数为2时的图形。
(2)Generalized Rosenbrock
函数表达式
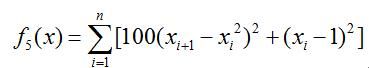
搜索范围

全局最优值
函数简介:此函数是很难极小化的典型病态二次函数,其全局最优与可到达的局部最优之间有一道狭窄的山谷,曲面山谷中的点的最速下降方向几乎与到函数最小值的最好方向垂直。由于此函数对搜索提供很少信息,使算法很难辨别搜索方向。下图给出了此函数维数为2时的图形。

(3)Generalized Rastrigin
函数表达式
搜索范围
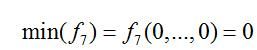
全局最优值
函数简介:此函数基于Sphere函数的基础上,使用了余弦函数来产生大量的局部最小值。它是一个典型的具有大量局部最优点的复杂多峰函数,此函数很容易使算法陷入局部最优,而不能得到全局最优解。下图给出了此函数维数为2时的图形。
3.1.2 测试函数代码
/**
* 测试函数: Rosenbrock,Rastrigin
* 随机生成n2维数据,并根据测试函数计算Y
* n1 行,n2 列,b1上限,b2下限,function计算函数
*/
def RandM(
n1: Int,
n2: Int,
b1: Double,
b2: Double,
function: String): BDM[Double] = {
// val n1 = 2
// val n2 = 3
// val b1 = -30
// val b2 = 30
valbdm1 = BDM.rand(n1, n2) * (b2 - b1).toDouble + b1.toDouble
valbdm_y = functionmatch {
case"rosenbrock" =>
valxi0 = bdm1(::,0 to (bdm1.cols -2))
valxi1 = bdm1(::,1 to (bdm1.cols -1))
valxi2 = (xi0 :*xi0)
valm1 = ((xi1 -xi2) :* (xi1 -xi2)) *100.0 + ((xi0 -1.0) :* (xi0 -1.0))
valm2 =m1 * BDM.ones[Double](m1.cols,1)
m2
case"rastrigin" =>
valxi0 =bdm1
valxi2 = (xi0 :*xi0)
valsicos = Bcos(xi0 *2.0 * Pi) * 10.0
valm1 =xi2 -sicos + 10.0
valm2 =m1 * BDM.ones[Double](m1.cols,1)
m2
case"sphere" =>
valxi0 =bdm1
valxi2 = (xi0 :*xi0)
valm1 =xi2
valm2 =m1 * BDM.ones[Double](m1.cols,1)
m2
}
valrandm = BDM.horzcat(bdm_y,bdm1)
randm
}
}
3.2 NN实例
//*******************例1(基于经典优化算法测试函数随机生成样本)*****************//
//2 随机生成测试数据
// 随机数生成
Logger.getRootLogger.setLevel(Level.WARN)
valsample_n1 =1000
valsample_n2 =5
valrandsamp1 = RandSampleData.RandM(sample_n1,sample_n2, -10,10,"sphere")
// 归一化[0 1]
valnormmax = Bmax(randsamp1(::, breeze.linalg.*))
valnormmin = Bmin(randsamp1(::, breeze.linalg.*))
valnorm1 =randsamp1 - (BDM.ones[Double](randsamp1.rows,1)) * normmin
valnorm2 =norm1 :/ ((BDM.ones[Double](norm1.rows,1)) * (normmax -normmin))
// 转换样本train_d
valrandsamp2 = ArrayBuffer[BDM[Double]]()
for (i <-0 tosample_n1 - 1) {
valmi =norm2(i,::)
valmi1 =mi.inner
valmi2 =mi1.toArray
valmi3 =new BDM(1,mi2.length,mi2)
randsamp2 += mi3
}
valrandsamp3 =sc.parallelize(randsamp2,10)
sc.setCheckpointDir("/user/checkpoint")
randsamp3.checkpoint()
valtrain_d =randsamp3.map(f => (new BDM(1,1, f(::,0).data), f(::,1 to -1)))
//3 设置训练参数,建立模型
// opts:迭代步长,迭代次数,交叉验证比例
valopts = Array(100.0,20.0,0.2)
train_d.cache
valnumExamples =train_d.count()
println(s"numExamples = $numExamples.")
valNNmodel =new NeuralNet().
setSize(Array(5, 7, 1)).
setLayer(3).
setActivation_function("tanh_opt").
setLearningRate(2.0).
setScaling_learningRate(1.0).
setWeightPenaltyL2(0.0).
setNonSparsityPenalty(0.0).
setSparsityTarget(0.05).
setInputZeroMaskedFraction(0.0).
setDropoutFraction(0.0).
setOutput_function("sigm").
NNtrain(train_d, opts)
//4 模型测试
valNNforecast =NNmodel.predict(train_d)
valNNerror =NNmodel.Loss(NNforecast)
println(s"NNerror = $NNerror.")
valprintf1 =NNforecast.map(f => (f.label.data(0), f.predict_label.data(0))).take(200)
println("预测结果——实际值:预测值:误差")
for (i <-0 untilprintf1.length)
println(printf1(i)._1 +"\t" +printf1(i)._2 +"\t" + (printf1(i)._2 -printf1(i)._1))
println("权重W{1}")
valtmpw0 =NNmodel.weights(0)
for (i <-0 totmpw0.rows -1) {
for (j <-0 totmpw0.cols -1) {
print(tmpw0(i,j) +"\t")
}
println()
}
println("权重W{2}")
valtmpw1 =NNmodel.weights(1)
for (i <-0 totmpw1.rows -1) {
for (j <-0 totmpw1.cols -1) {
print(tmpw1(i,j) +"\t")
}
println()
}
转载请注明出处:
http://blog.csdn.net/sunbow0