第十四章 高级特性-海纳百川:BIRT报表扩展点(续)
14.2 BIRT数据源的扩展
ODA 之所以能够有如此强的灵活性,是因为:
· 它提供了一套完整的接口,开发者可以自己去实现数据源的访问逻辑,使得数据源对数据使用者变得透明。只要开发者遵循编程规范,就可以对任何数据进行驱动。
· 它基于 Eclipse 的 plugin 框架,可以通过 Eclipse 的扩展点方便地连接数据源并且被数据使用者调用。
· 它提供了 Eclipse RCP(Rich Client Platform)编程接口,用户可以通过这些接口实现 ODA 驱动设计页面,方便在使用时进行参数的设定。
本节将采用至下而上的方式,依次讲解以下几个方面的内容:
· 背景知识:Eclipse 插件(plugin)的基础背景知识,什么是扩展点和扩展。
· 实现:使用 ODA 实现自己的数据驱动,并通过扩展点将数据驱动连接到一个自己实现的运行时虚拟数据源。
· 使用:将数据使用者 BIRT(Business Intelligence and Reporting Tools)连接到自定义的 ODA 数据驱动并生成报表。
OSGI规范和 Eclispe 插件框架
Eclipse 是我们所熟悉的集成开发环境工具之一,它为我们提供一个非常灵活的插件开发框架。而 Eclipse 的插件框架则是基于 OSGi(Open Services Gateway Initiative)规范所开发出来的一个可扩展的开放平台。 OSGi 规范是由 OSGi 联盟组织所制定出来的一个标准的、面向组件的计算环境和服务框架,它提供了一套开放的、面向服务的、易于部署的编程模型。
OSGi bundle 就是 OSGi 的一个插件,它可以是一个功能模块,也可以是一系列的功能组合。OSGi 的 bundle 之间可以共享各有的接口,也可以进行相互调用,并且还可以动态的加载和卸载。所以我们可以通过 OSGi 的bundle 来开发我们所需要的功能插件。
关于 OSGi 规范和 Eclispe 插件框架的详细知识可在 develperworks 网站上搜索到,这里就不再进行详细阐述了。
扩展点与扩展
Eclipse 提供了“扩展点 (extension points)”和“扩展 (extensions)”的概念,扩展点是用来给其它插件提供功能扩展的一种方式。定义了扩展点的插件能够让其它插件对它进行扩展,而这个扩展点定义了其它插件如何来对它进行扩展。扩展点和扩展的定义都是在 plugin.xml 文件里完成的。
总之,如果一个插件定义了扩展点,那么它就允许其它插件以定义好的方式进行功能扩展;反之,如果这个插件提供的是一个扩展,那么它就是对已经存在的扩展点进行的功能扩展。
Data Tools Platform(DTP)是 Eclipse 开源项目之一。其目的是为开发者提供一系列工具和框架,用于针对各类数据(数据库数据、文件类数据以及各种运行时数据)的访问、使用和开发。DTP 是 Eclipse 基本安装的一部分,在 Eclipse 的安装目录中的 plugins 目录中,以“org.eclipse.datatools”开头的插件文件夹均为 DTP 的功能部件。
Open Data Access(ODA)是 DTP 的重要组成部分之一。作为一套灵活的数据访问框架,ODA 面向调用者提供了一套通用的接口,使之可以访问标准的数据源(如 DB2,SQL Server,MySQL 等数据库),也可以访问自定义的数据源(如特定格式的文件类数据或者是运行时数据)。通过这样的方式,ODA 在数据使用者与数据源之间架起了一座桥梁。对于数据使用者而言,得到的数据都是以 ODA 所规定的格式返回,因此不必去关心桥梁那头数据源的具体情况,只需将注意力集中在数据的使用和开发上。
除了开发者可以使用 DTP/ODA 外,Eclipse 的一些功能组件也是基于它们开发的。这其中最有名的莫过于是BIRT(Business Intelligent and Reporting Tools)。在 BIRT 的报表设计过程中,用户可以选择连接到各种数据源,而这一能力,就是 DTP 所提供。在本节后面的章节里,将会介绍如何使用自定义的 ODA 数据驱动连接到自定义数据源,并通过 BIRT 生成报表。
ODA编程接口
读者若打开 Eclipse 的安装目录,在 plugins 目录下会看到前文中所提到的一系列 DTP 插件。其中,org.eclipse.datatools.connectivity.oda 插件中定义了一系列的接口。实现自定义 ODA 数据驱动的工作之一,就是实现这些接口。
ODA 的接口设计与 JDBC 有几分类似。后者的设计初衷是作为数据库的连接驱动。
让我们先来介绍一下这些接口:
1 IDriver:是数据驱动的入口,使用程序通过它获得一个 IConnection 的实例。
2 IConnection:代表了一条建立在数据使用者和数据源间的连接。通过其可以创建若干 IQuery 实例。
3 IQuery:代表了一条数据查询,通过此查询可以返回若干 IResultSet 实例。
4 IResultSet:代表了一次数据查询的结果,通过它可以获得 IResultSetMetaData。
5 IResultSetMetaData:代表了一次数据查询结果的元数据信息。
除了以上这些接口之外,还有 IDataSetMetaData 和 ParameterMetaData。因为在本文的例子中无需实现它们,在此不作赘述。
创建ODA 数据驱动工程
在接下来的例子里,我们将会实现一个自定义的 ODA 数据驱动插件,这个插件需要实现以下功能:
1 实现前文所提及的接口。
2 设计一个或多个驱动参数,并通过实现一个 ODA Designer 提供用户界面。帮助开发者在设计时传入参数。
3 设计一个扩展点,该扩展点被自定义的数据源实现。数据驱动通过扩展点寻找到所有的自定义数据源。
4 设计一些 Java Interface,帮助自定义数据源规范编程接口。
是不是感到有些复杂?好消息是 DTP 提供了 ODA 数据驱动的设计模板,帮助你完成一些通用代码。我们只需要在生成的代码中加入特定的逻辑。
我们开始吧。首先在 Eclipse 中创建一个“ODA Runtime Driver Plug-in Project”:
图表 1 创建项目
在接下来的窗口中输入项目的名字(com.ibm.oda.sample.driver),保持其它选项不变并点击“Next”:
图表 2 输入项目名称
在窗口中输入插件的相关信息并点击“Next”,如下图所示:
图表 3 输入插件相关信息
在窗口中选择“ODA Data Source Runtime Driver”模板,这将在源代码中生成基本的 ODA 数据类型,包括 ODA 接口的实现类。点击“Next”:
图表 4 选择模板
我们假设需要一个 Data Source 参数。按照下图输入后,点击“Finish”。
图表 5 输入数据驱动插件特定参数
这样,一个 ODA 数据驱动工程就生成了。在我们查看工程内容前,先来生成一个 ODA Designer 的 RCP 项目,稍后再回到这个数据驱动工程。
创建 ODA Designer 工程
ODA Designer 和 ODA 数据驱动通常成对出现,ODA Designer 通过实现在 org.eclipse.datatools.connectivity.oda.design 插件中定义的一系列扩展点来提供数据驱动创建过程中的人机交互。在本文前面,数据驱动被定义为接受一个参数。读者可能会问,这个参数在什么时候通过什么方式传入?答案就在 ODA Designer 中。在这一章节中,我们只引导读者创建这个 Designer,至于这个 Designer 是如何被使用的,在后面的 BIRT 报表章节中会做出示范。
创建 ODA Designer 工程的步骤和 ODA 驱动相似,首先选择创建一个“ODA Designer Plug-in Project”,然后输入工程名字、插件名称并选择模板为 ODA Data Source Designer。在最后一步,输入之前创建的数据驱动信息以将两者耦合起来,如下图所示:
图表 6 输入对应数据驱动信息
好了,点击“Finish”之后,这个 ODA Designer 就被创建好了。因为没有特殊的需求,在这里我们使用 ODA Designer 的默认生成代码即可。
到目前为止我们已经创建了两个工程。暂时不要急于看到代码运行的效果。接下来,是时候向 ODA 数据驱动工程里面添加代码了。
数据驱动的参数配置
还记得在建立数据驱动的时候,我们告诉 IDE 这个数据驱动可以接受一个参数吗(“Number of Data Source Properties”输入框)?这会在数据驱动工程的 plugin.xml 中加入一段这样的配置:
清单 1. 参数配置
- <properties>
- <property
- name="provider"
- allowsEmptyValueAsNull="true"
- defaultDisplayName="Provider"
- type="string"
- isEncryptable="false">
- </property>
- </properties>
在这个示例里我们不修改这个默认配置,只需要把 name 和 defaultDisaplayName 属性改成一个易懂的名字,比如说“provider”,稍后我们会通过这个参数来告之数据驱动应该连接哪一个数据源。
数据驱动的数据类型映射
读者可以顺便看一下 plugin.xml 中的其它自动生成的内容:
清单 2. 数据驱动的 plugin.xml
- <?xml version="1.0" encoding="UTF-8"?>
- <?eclipse version="3.4"?>
- <plugin>
- <extension-point id="com.ibm.oda.sample.driver" name="com.ibm.oda.sample.driver"
- schema="schema/com.ibm.oda.sample.driver.exsd"/>
- <extension
- id="%oda.data.source.id"
- point="org.eclipse.datatools.connectivity.oda.dataSource">
- <dataSource
- driverClass="com.ibm.oda.sample.driver.impl.Driver"
- defaultDisplayName="%data.source.name"
- setThreadContextClassLoader="false"
- odaVersion="3.1"
- id="%oda.data.source.id">
- <properties>
- <property
- name="provider"
- allowsEmptyValueAsNull="true"
- defaultDisplayName="Provider"
- type="string"
- isEncryptable="false">
- </property>
- </properties>
- </dataSource>
- <dataSet
- defaultDisplayName="%data.set.name"
- id="com.ibm.oda.sample.driver.dataSet">
- <dataTypeMapping
- nativeDataTypeCode="1"
- odaScalarDataType="String"
- nativeDataType="String">
- </dataTypeMapping>
- <dataTypeMapping
- nativeDataTypeCode="4"
- odaScalarDataType="Integer"
- nativeDataType="Integer">
- </dataTypeMapping>
- <dataTypeMapping
- nativeDataTypeCode="8"
- odaScalarDataType="Double"
- nativeDataType="Double">
- </dataTypeMapping>
- <dataTypeMapping
- nativeDataTypeCode="3"
- odaScalarDataType="Decimal"
- nativeDataType="BigDecimal">
- </dataTypeMapping>
- <dataTypeMapping
- nativeDataTypeCode="91"
- odaScalarDataType="Date"
- nativeDataType="Date">
- </dataTypeMapping>
- <dataTypeMapping
- nativeDataTypeCode="92"
- odaScalarDataType="Time"
- nativeDataType="Time">
- </dataTypeMapping>
- <dataTypeMapping
- nativeDataTypeCode="93"
- odaScalarDataType="Timestamp"
- nativeDataType="Timestamp">
- </dataTypeMapping>
- <dataTypeMapping
- nativeDataTypeCode="16"
- odaScalarDataType="Boolean"
- nativeDataType="Boolean">
- </dataTypeMapping>
- </dataSet>
- </extension>
- <extension
- point="org.eclipse.datatools.connectivity.connectionProfile">
- <category
- name="%data.source.name"
- parentCategory="org.eclipse.datatools.connectivity.oda.profileCategory"
- id="%oda.data.source.id">
- </category>
- <connectionProfile
- pingFactory="org.eclipse.datatools.connectivity.oda.profile.OdaConnectionFactory"
- name="%connection.profile.name"
- category="%oda.data.source.id"
- id="%oda.data.source.id">
- </connectionProfile>
- <connectionFactory
- name="ODA Connection Factory"
- profile="%oda.data.source.id"
- class="org.eclipse.datatools.connectivity.oda.profile.OdaConnectionFactory"
- id="org.eclipse.datatools.connectivity.oda.IConnection">
- </connectionFactory>
- </extension>
- </plugin>
因为是自动生成的内容,我们在此不一一进行解释。唯一需要提请读者注意的是数据类型映射的部分(dataTypeMapping 标签)。为什么需要数据映射呢?这是因为 ODA 数据驱动所连接的数据源可以是任何形式,因此来自于数据源的数据类型有无数种可能(甚至是自定义的数据类型)。由于这种不可预测性,ODA 数据驱动是无法自行完成数据类型的转换。因此 ODA 本身定义了有限数量的数据类型(见 dataTypeMapping 标签中的 odaScalarDataType 属性),开发者的任务就是通过配置的方式,把数据源中可能出现的各种数据映射到这些有限的 ODA 数据类型上。
除此之外,开发者还需要写少量代码。读者可以参看本文附件中数据驱动的源代码。在 DataTypes 类中有一个工具方法叫做 getTypeCode,这个方法的传入参数是数据源数据类型的名字,返回数值是映射后的 ODA 数据类型。该方法使用 ODA 提供的 API,从 plugin.xml 读取数据类型映射关系。读者如果搜索这个方法的引用,会发现 ResultSetMetaData 类就是通过这个工具方法来返回数据的 ODA 类型。而这个返回类型会直接决定 ODA 框架使用 ResultSet 中的哪一个方法(如 getInt,getDouble 等)来获得列数据。
清单 3. 数据类型的映射
- public static int getTypeCode(String typeName) throws OdaException {
- if ((typeName == null) || (typeName.trim().length() == 0)) {
- return 12;
- }
- String preparedTypeName = typeName.trim();
- if (preparedTypeName == "NULL") {
- return 0;
- }
- DataTypeMapping typeMapping = getManifest().getDataSetType(null)
- .getDataTypeMapping(preparedTypeName);
- if (typeMapping != null) {
- return typeMapping.getNativeTypeCode();
- }
- throw new OdaException("dataTypes_TYPE_NAME_INVALID " + typeName);
- }
- private static ExtensionManifest getManifest() throws OdaException {
- return ManifestExplorer.getInstance()
- .getExtensionManifest("com.ibm.oda.sample.driver");
- }
为数据驱动添加扩展点
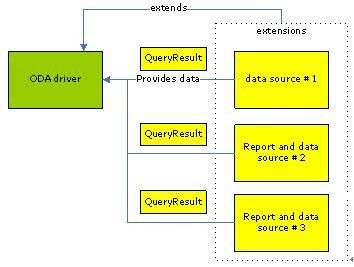
为什么这个示例数据驱动需要扩展点呢?因为它所连接的数据源既不是一个数据库,也不是一个文件,而是一个运行于 Eclipse 环境下的插件。因此我们通过扩展点的方式来在数据驱动与数据源之间建立联系:
1 数据驱动定义一个扩展点,扩展点需要的参数之一就是数据驱动的名字(还记得刚才提到的数据驱动参数吗,用户在定义 BIRT 报表时传入这个参数,数据驱动使用这个参数与所有数据源名进行比对,找到需要连接的数据源)。
2 数据源实现这个扩展点,以此将相关调用的入口暴露给数据驱动。
这样的结构如下图所示:
图表 7 数据源与数据驱动的关系
扩展点的设计如下图所示,读者也可以参看附件源码中数据驱动项目的 com.ibm.oda.sample.driver.exsd 文件来了解细节。
图表 8 扩展点定义
定义编程接口
在本文的例子中,ODA 数据驱动是用来连接一个运行时的数据源。因此数据驱动需要定义适当的编程接口供数据源实现,以保证返回自数据源的结果是可以辨识的。请参看附件源码中“com.ibm.oda.sample.driver.data”包中的类,我们来对这些类做一个简单的说明。
1 DataProvider: 抽象类是每个数据源的抽象表示。也是 ODA 数据驱动对数据源的调用入口。每个希望被数据驱动使用数据源都必须继承这个类,并将继承类的暴露给数据驱动(请参看前面的扩展点定义,扩展点的参数之一就是继承类的完整类路径)。
2 QueryResult:数据源向数据驱动返回查询结果时应使用的包装类。其中包含了列的名字和类型,并按照行为单位返回数据。
3 RowData:行数据的封装。
以上就是 ODA 数据驱动暴露给数据源的编程接口。数据源只要遵循这些接口,其返回的数据就能被 ODA 数据驱动识别。关于这些类的具体实现,请参看附件代码。在接下来对数据源的讲解中,我们还会接触到这些类。
ODA 编程接口的实现
还记得前面提到的 ODA 编程接口吗(如果不记得了,请回到“ODA 编程接口”节,温习一下里面讲到的几个编程接口)。对于我们的这个 ODA 数据驱动,它需要在运行时通过传入的参数来寻找应该连接的数据源。如何做到呢?需要以下几步:
4 获得传入参数(这个参数通常是在用户选择一个数据驱动时就会输入。在稍后的 BIRT 报表范例中,读者会看到参数输入界面。该界面由 ODA Designer 提供)。
5 遍历 ODA 数据驱动所有扩展点的实现,检查它们的“provider”属性是否和参数相匹配。如果是,则说明实现这个扩展点的插件即为需要使用的数据源。
6 从这个数据源中获得调用入口(DataProvider 的实现类)。进一步就可以查询数据了。
以上逻辑的实现在 com.ibm.oda.sample.driver 工程中的 Connection 类中,代码如下所示:
清单 4. Connection 类的部分实现
- public void open( Properties connProperties ) throws OdaException {
- m_isOpen = true;
- String category = (String)connProperties.get(PROP_PRIVIDER);
- try {
- initDataProvider(category);
- } catch (CoreException e) {
- e.printStackTrace();
- }
- }
- private void initDataProvider(String category) throws CoreException {
- IExtension[] extensions = Platform.getExtensionRegistry().
- getExtensionPoint("com.ibm.oda.sample.driver").getExtensions();
- for(IExtension extension : extensions) {
- IConfigurationElement[] configElems = extension.getConfigurationElements();
- for(IConfigurationElement configElem : configElems) {
- if("DataProvider".equalsIgnoreCase(configElem.getName())) {
- if(null!= category && category.equalsIgnoreCase(
- configElem.getAttribute(PROP_PRIVIDER))) {
- dataProvider = (DataProvider)configElem.
- createExecutableExtension("class");
- return;
- }
- }
- }
- }
- }
在 Connection 类获得了 DataProvider 实例后,就可以将它传给 Query,供后者进行数据查询。为此,Query 类的默认实现也需要进行修改:
1 接受 DataProvider 作为其构造函数的参数。
2 使用 DataProvider 来获得数据(QueryResult)。
3 解析 QueryResult,生成 ResultSet 和 ResultSetMetaData 实例并返回。
代码如下所示:
清单 5. Query 类的部分实现
- public IResultSet executeQuery() throws OdaException {
- QueryResult result = this.dataProvider.executeQuery(this.queryText);
- if(null != result) {
- IResultSetMetaData metaData = createMetaData(result);
- this.resultSet = new ResultSet(result.getData(), metaData);
- return this.resultSet;
- } else {
- return null;
- }
- }
- private IResultSetMetaData createMetaData(QueryResult result) {
- return new ResultSetMetaData(result.getColumnNames(),
- result.getColumnLabels(), result.getColumnTypes());
- }
到目前为止,ODA 数据驱动的主要调用顺序已经说明完毕。请读者自己阅读 ResultSet 和 ResultSetMetaData 的实现。他们主要是对查询数据进行了包装,逻辑相对简单。
接下来,我们来讲解 ODA 数据源的实现。
实现一个运行时的 ODA 数据源
在前面的 ODA 数据驱动中,我们为数据源的实现做了很多准备工作,包括:
1 定义了供数据源实现的扩展点
2 定义了一系列编程接口
很明显,数据源需要做的事情就是实现扩展点和接口。作为示例,我们会实现一个非常简单的数据源,这个数据源返回一个数据表,表里面包含了顾客的名字和所属公司。
实现 ODA 数据源扩展点
范例数据源在附件源码中对应的工程是 com.ibm.oda.sample.datasource,这是一个普通的插件工程,因此包含了 plugin.xml 文件。在 plugin.xml 中,我们需要声明对“com.ibm.oda.sample.driver”扩展点的实现,如下所示:
清单 6. 实现 com.ibm.oda.sample.driver 扩展点
- <plugin>
- <extension
- point="com.ibm.oda.sample.driver">
- <DataProvider
- class="com.ibm.oda.sample.datasource.SampleDataProvider"
- provider="com.ibm.oda.sample.datasource">
- </DataProvider>
- </extension>
- </plugin>
这个扩展点的实现声明了两个要素:
1 该数据源的辨识名是“com.ibm.oda.sample.datasource”(provider 属性)。
2 该数据源的调用入口类是 com.ibm.oda.sample.datasource.SampleDataProvider(class 属性)。
实现调用入口类
数据源的实现很简单,仅包含两个类,一个是每个插件都有的 Activator,跟随项目自动生成,不需要做任何的改动。另外一个就是调用入口类 SampleDataProvider。SampleDataProvider 类继承自 DataProvider,只有一个公有方法 executeQuery。这个接口接受一个字符串类型的参数,用作查询语句。在本范例中,我们并不检查这个查询语句,直接返回查询结果。我们将查询结果的生成逻辑放在一个方法中:
清单 7. 生成查询结果
- private QueryResult queryAll() {
- List<RowData> resultList = new ArrayList<RowData>();
- for(int i = 0; i < 10; i++) {
- Object[] cols = new Object[3];
- cols[0] = i;
- cols[1] = "User_" + i;
- cols[2] = "Company_" + i;
- RowData r = new RowData(cols);
- resultList.add(r);
- }
- String[] columnNames = new String[3];
- columnNames[0] = "id";
- columnNames[1] = "name";
- columnNames[2] = "company";
- String[] columnTypes = new String[3];
- columnTypes[0] = DataTypes.INTEGER;
- columnTypes[1] = DataTypes.STRING;
- columnTypes[2] = DataTypes.STRING;
- return new QueryResult(resultList, columnNames, columnTypes);
- }
相信我们不用对以上代码做出太多的解释,读者就能明白它所实现的功能。改代码的唯一作用就是生成一系列数据和数据类型信息,将它们包装到 QueryResult 中并返回。在代码中,我们也用到了 RowData 类,这些类都是在 ODA 数据驱动中实现的。虽然数据源不知道自己的方法何时调用,被谁调用,只要它遵照编程协议,就不会有问题。Eclipse 框架下的编程就是这样。
好了,到此为止,我们已经完成了所有需要编写的代码。终于可以来看看代码运行的结果了。在接下来的章节中,我们会带领读者创建一个 BIRT 的报表工程,在工程中使用 ODA 数据驱动、数据源及 Designer。
ODA 数据驱动及数据源的使用
在创建好了自定义的 ODA 数据驱动和数据源以及 ODA Designer 之后,这里要介绍一下如何使用 BIRT(Business Intelligent and Reporting Tools)工具以及自定义的 ODA 数据驱动连接到自定义的数据源上并生成自定义的 BIRT 报表。
BIRT 是一个基于 Eclipse 工具插件的开源报表系统。它主要是用在基于 Java 与 J2EE 的 Web 应用程序上。BIRT 主要由两部分组成:一个是基于 Eclipse 的报表设计和一个可以加到应用服务的运行期组件。BIRT 同时也提供一个图形报表制作引擎等。这里我们主要使用 BIRT 的报表设计功能。我们大概需要以下五个步骤来生成这个自定义的报表以及报表模板:
1 先创建一个基于 ODA 数据驱动的报表工程(Report Project);
2 创建并初始化一个新的报表(Report);
3 添加一个自定义的数据源到报表模板上;
4 选择数据源上的数据集并输入查询数据集的查询条件;
5 添加需要的数据列到模板当中并编辑报表模板。
通过这五个步骤,就可以生成我们需要的报表模板了,当然我们可以在这里进行报表预览(预览时会连接到上述提供的自定义数据源当中并显示数据源提供的数据)和修改模板等。
创建报表工程及报表
下面就让我们具体看看怎样进行上述一系列的操作。
首先,我们要在之前创建的 ODA 数据驱动工程上来创建自己的报表工程。具体操作是:右键单击 ODA 数据驱动工程 — > Run As — > Eclipse Application。这里会基于 ODA 数据驱动工程、数据源工程和 ODA Designer 工程打开一个新的 Eclipse 平台。在这个平台上创建一个报表工程,如下图所示:
图表 9 创建新的报表工程
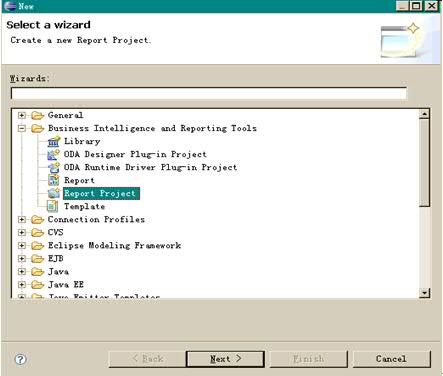
点击 Next,然后输入我们的报表工程名称“com.ibm.oda.sample.report”,点击 Finish。 如下图所示:
图表 10 输入报表名称
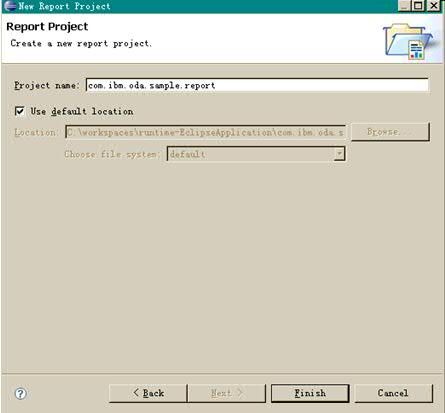
这样,报表工程就已经创建好了。接下来我们需要创建一个新的报表,选择 Report,点击 Next。如下图所示:
图表 11 创建新的报表
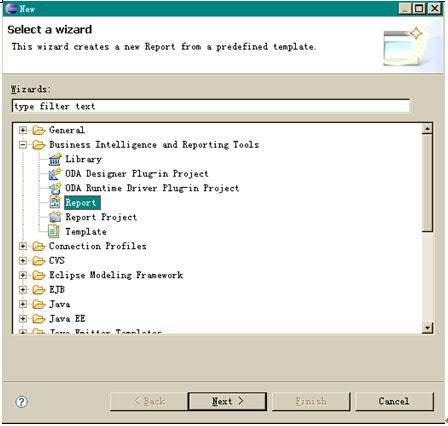
输入报表名称“oda_report.rptdesign”,点击 Next。如下图所示:
图表 12 输入报表名称
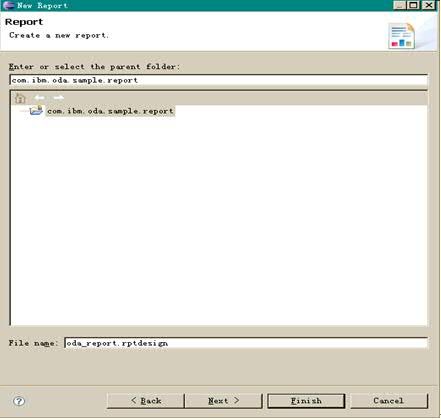
然后再这一步选择“Blank Report”,点击 Finish。如下图所示:
图表 13 选择报表模板
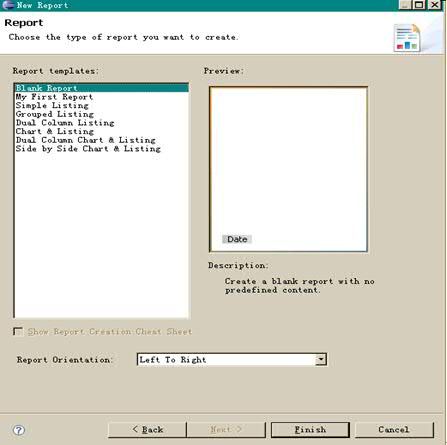
完成上面的操作之后,初始化的报表模板就创建成功了。之后我们还需要对这个报表工程添加资源,编辑以及生成报表。
添加资源,编辑并生成报表
对于一个自定义的报表,我们不但要指定它的数据源,而且还需要指定它的数据集。以及选择需要的报表样式或者需要显示的报表字段等等一些内容。
首先,打开“Data Explorer”视图,在这个视图里面我们可以看到数据源(Data Sources),数据集(Data Sets)以及其它一些菜单选项等。右键点击菜单选项 Data Sources — > New Data Source,这时我们进入数据源选择对话框,如下图所示:
图表 14 Data Explorer 视图
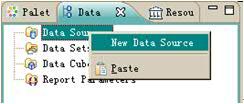
图表 15 选择自定义数据源
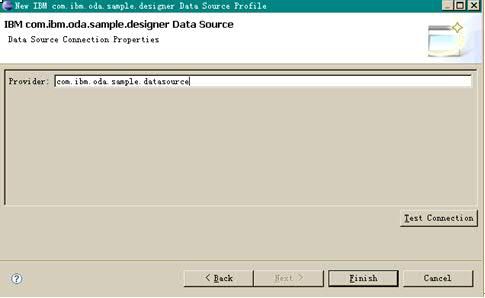
在这个对话框当中,我们可以看到前文定义的数据源“IBM com.ibm.oda.sample.driver Data Source”。选择该数据源,点击 Next 进入下一个对话框之后,这里将根据 ODA Designer 工程的配置信息(参见上文“数据驱动的参数配置”部分)来显示数据源输入对话框,输入数据源提供者的名称 “com.ibm.oda.sample.datasource”,点击 Finish,完成数据源的创建。如下图所示:
图表 16 输入数据源提供者名称
数据源创建完成之后,我们还需要创建数据集。右键单击菜单选项 Data Sets — > New Data Set,然后进入数据集选择对话框,这里会根据之前所选择的数据源列出该数据源下已有的数据集,选择该数据集,点击 Next。如下图所示:
图表 17 选择数据集
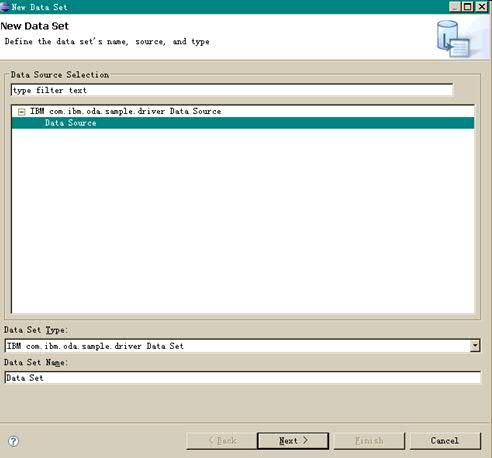
然后这里将根据 ODA Designer 工程的设计,进入到数据查询条件对话框,这里我们输入查询条件“select *”(因为我们的实例数据源不会检查查询条件,实际上,读者可以在这里输入任何内容。另外 ODA 的数据查询语句无需遵照 SQL 的语法,只要数据源能够正确识别即可)查询所有数据,然后点击 Finish。如下图所示:
图表 18 输入数据查询条件
这里会进入输出列编辑对话框,我们使用所有默认选项,输出所有列,点击 OK,完成数据集的创建。如下图所示:
图表 19 数据集编辑框
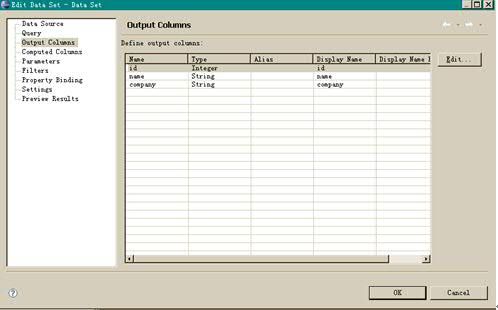
创建完数据源和数据集之后,我们就可以开始设计自己的报表了,首先打开“Palette”视图,我们可以看到很多报表的控件。如下图所示:
图表 20 Palette 视图
把控件 Table( 见上图 ) 拖入报表模板当中 ( 需要输入要显示的列数和行数 ),报表模板就会添加一个 Table 的控件,如下图所示:
图表 21 报表模板上的 Table 控件
然后切换到“Data Explorer”视图,这是我们可以看到该视图上的数据源和数据集已经增加了内容。如下图所示:
图表 22 Data Explorer 视图
把这些字段拖入报表模板上的 Table 控件中,这样子数据集就和这个 Table 控件绑定在一起了。如下图所示:
图表 23 绑定了数据集的 Table 控件
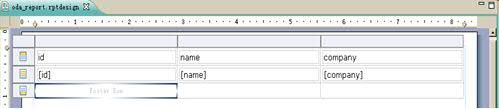
选择报表模板下端的 Preview 选项,这时就可以预览连接到我们自定义的数据源上的数据了。如下图所示:
图表 24 模板报表数据预览
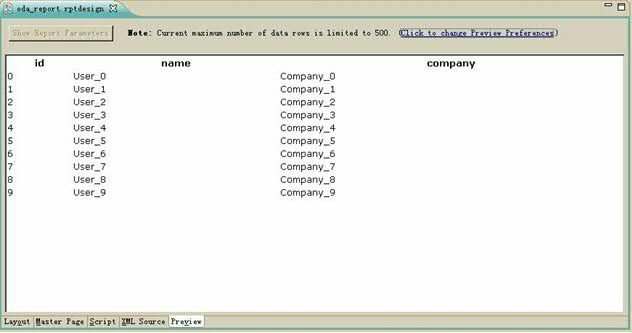
至此,我们就实现了使用自定义的 ODA 数据驱动连接到自定义的数据源上,并通过 BIRT 工具最终生成报表。
ODA 为程序员提供了一套的数据访问框架。各式各样格式的数据,通过 ODA 数据驱动这座桥梁,就变成了统一的数据格式,方便数据使用者调用。 如果你的数据源是数据库,你通常不会想要使用 ODA,因为数据库开发方通常会提供 JDBC 数据驱动。但如果你的数据源不是数据库,而你想使用报表来展示,则可以使用 ODA 来扩展