Discuz!NT企业版之Sphinx全文搜索(上)
作为Discuz!NT企业版中的一员,在设计企业级搜索架构之初,就考虑了海量数量,准实时索引更新,并发访问,安装布署等诸多方面。目前在生产环境下被广泛使用的开源搜索引擎中,sphinx以其强大快速的索引功能,优异的并发响应性能,方面灵活的布署,分布式查询等诸多因素而倍受青睐。
目前Sphinx广泛应用在Linux平台上,尽管官方所发布的产品中也有window版本,并且支持mssql数据库,但在使用过程中才发现,其只在发布的windows平台下的版本里才支持mssql数据库,而linux平台下只有MySql,PostgreSQL这两种数据库支持。尽管后来在网上查找资料时发现可以使用UNIXODBC方式在LINUX下链接MsSql数据库,但在unixodbc的官方网站下载的源码包中却发现其并不包含makefile文件,从而导致下载解压的源码包无法编译(看来unixodbc开发者也疏忽了),当然即使ODBC能链接成功,但效率上还是可能存在问题。
而在window下尽管能实现链接mssql和创建索引以及查询,但在进行压力测试时发现即使50并发也会让sphinx守护进程疲于奔命到停止响应(后来在Linux下布署,发现同样数据索引量同一台机器,可以支持至少200-300并发),而sphinx的宿主环境是一台单核1.5G+1.5g内存的普通台式机(现在主流笔记本的配置都比它高得多)。所以就并发性而言,目前主流平台还是建立在linux上.
正因为如此,我才在解决方案中引入了一个mysql数据库,来实现下面三个目标:
1.为LINUX平台下SPHINX提供可访问的数据源。
2.充当快照功能(Slave database)解决当主数据库(Master database)宕机后,不会影响SPHINX创建索引了,这样看就相当于备份功能。
3.解决当创建SPHINX索引时,对主数据库的访问压力。
下面这张图简单说明了Sphinx(Linux) + MySql + Discuz!NT的关系:
如上面所说的,我们在产品中引入了Sphinx客户端API,而服务端则通过LINUX+SPHINX守护进程来实现,所以这篇文章要被分为两个部分,今天要说明的只是Discuz!NT方面的改动。下一篇将会介绍如何在LINUX下配置SPHINX及增量索引等相关工作。好了开始正文吧。
首先为了简化安装,我写了一个文件类用于配置SPHINX客户端信息,如下(Discuz.Config/EntLibConfigInfo.cs):
/// Sphinx企业级查询配置信息
/// </summary>
public class SphinxConfig
{
/// <summary>
/// Mysql增量数据库链接地址
/// </summary>
public string MySqlConn;
/// <summary>
/// 是否启用Sphinx搜索
/// </summary>
public bool Enable;
/// <summary>
/// Sphinx服务地址
/// </summary>
public string SphinxServiceHost;
/// <summary>
/// Sphinx服务端口
/// </summary>
public int SphinxServicePort = 3312 ;
......
}
该配置类中提供了是否开启SPHINX查询(Enable),以及MYSQL数据库链接,以及SPHINX服务端的地址端口信息等。
下面介绍一下Sphinx的客户端代码(C#)实现,该代码被放到了Discuz.EntLib这个项目中(位于SphinxClient/),而该项目是一个基于GNU的开源项目,其类"SphinxClient"实现了构造方法和相应访问SPHINX服务端守护进程的方法,如下:
这些方法的名称和参数信息与SPHINX开放的API是对应的,而相应的SPHINX文档可以从官方下载,这里只提供一个中文文档的下载地址,也就是CORESEEK的文档链接, 如下:
http://www.coreseek.cn/uploads/pdf/sphinx_doc_zhcn_0.9.pdf
这份手册中介绍了大部分API方法的使用和示例,是目前为止网上找到最全的中文文档了。
有了客户端,我们还要在已有的搜索代码中植入SPHINX查询逻辑代码。
在原来的产品中,搜索功能是使用SQLSERVER全文检索的方法提供的,其原理是:
使用SQLSERVER全文检索方法查询帖子分表(dnt_posts,表结构如下图所示)的MESSAGE字段:
而该字段是Text类型,所以在一次性查询出所有记录的pid字段后,以distinct方法过滤其中记录重复的tid信息,最终会返回tid字段并将其放入到数据库中,相应SQL语句构造方法参照如下(Discuz.Data.SqlServer/GlobalManage.cs):
{
StringBuilder sqlBuilder = new StringBuilder();
string orderfield = " lastpost " ;
switch (resultOrder)
{
case 1 :
orderfield = " tid " ;
break ;
case 2 :
orderfield = " replies " ;
break ;
case 3 :
orderfield = " views " ;
break ;
default :
orderfield = " lastpost " ;
break ;
}
sqlBuilder.AppendFormat( " SELECT DISTINCT [{0}posts{1}].[tid],[{0}topics].[{2}] FROM [{0}posts{1}] LEFT JOIN [{0}topics] ON [{0}topics].[tid]=[{0}posts{1}].[tid] WHERE [{0}topics].[displayorder]>=0 " ,
BaseConfigs.GetTablePrefix,
postTableId,
orderfield);
if (searchForumId != "" )
sqlBuilder.AppendFormat( " AND [{0}posts{1}].[fid] IN ({2}) " , BaseConfigs.GetTablePrefix, postTableId, searchForumId);
if (posterId != - 1 )
sqlBuilder.AppendFormat( " AND [{0}posts{1}].[posterid]={2} " , BaseConfigs.GetTablePrefix, postTableId, posterId);
if (searchTime != 0 )
sqlBuilder.AppendFormat( " AND [{0}posts{1}].[postdatetime] {2} '{3}' " ,
BaseConfigs.GetTablePrefix,
postTableId,
searchTimeType == 1 ? " < " : " > " ,
DateTime.Now.AddDays(searchTime).ToString( " yyyy-MM-dd 00:00:00 " ));
string [] keywordlist = Utils.SplitString(strKeyWord.ToString(), " " );
strKeyWord = new StringBuilder();
for ( int i = 0 ; i < keywordlist.Length; i ++ )
{
if (strKeyWord.Length > 0 )
strKeyWord.Append( " OR " );
if (GeneralConfigs.GetConfig().Fulltextsearch == 1 )
{
strKeyWord.AppendFormat( " CONTAINS(message, '/ " * " , BaseConfigs.GetTablePrefix, postTableId);
strKeyWord.Append(keywordlist[i]);
strKeyWord.Append( " */ "' ) ");
}
else
strKeyWord.AppendFormat( " [{0}posts{1}].[message] LIKE '%{2}%' " ,
BaseConfigs.GetTablePrefix,
postTableId,
RegEsc(keywordlist[i]));
}
if (keywordlist.Length > 0 )
sqlBuilder.Append( " AND " + strKeyWord.ToString());
sqlBuilder.AppendFormat( " ORDER BY [{0}topics]. " , BaseConfigs.GetTablePrefix);
switch (resultOrder)
{
case 1 :
sqlBuilder.Append( " [tid] " );
break ;
case 2 :
sqlBuilder.Append( " [replies] " );
break ;
case 3 :
sqlBuilder.Append( " [views] " );
break ;
default :
sqlBuilder.Append( " [lastpost] " );
break ;
}
return sqlBuilder.Append(resultOrderType == 1 ? " ASC " : " DESC " ).ToString();
}
如果上述的构造方法所拼接出的SQL语句被顺利执行后,就会在相应的dnt_searchcaches表中生成一条记录,形如:
注:<ForumTopics>表示其是论坛搜索的结果(因为产品中同时也提供了空间相册搜索功能,所以这样加以标识).
而dnt_searchcacheds数据字典如下(上面的ForumTopics对应表中的tids字段:text类型 ):
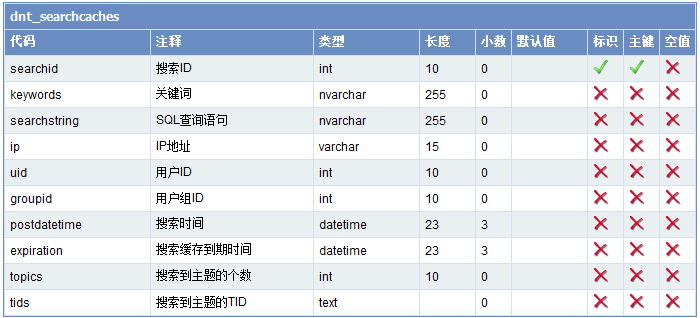
然后根据这些tid记录,按分页的大小一次获取其中一段数据(比如头10条:1,5,6,10,11,12,13,2,26,25),然后再用这段tid集合作为where条件 放到类似下面的查询语句中运行,就会获取相应的主题列表了(查询结果以主题列表而不是帖子列表方式呈现,这也是为什么要在GetSearchPostContentSQL中进行distinct的原因,因为一个主题可以有多个帖子,即1:n):
select * from dnt_topics where tid in (tid集合)
原理清楚之后,下面就是加入SPHINX查询逻辑了。因为SPHINX对全文索引进行查询时,会返回相应的documemntId,相应对帖子分表中的pid字段,所以只要将逻辑代码放到GetSearchPostContentSQL中就可以了,这里使用了配置文件开关的方式来标识是否执行SPHINX查询,如下:![]()
{
// 如果开启sphinx全文搜索时
if ( ! string .IsNullOrEmpty(strKeyWord.ToString()) && EntLibConfigs.GetConfig() != null && EntLibConfigs.GetConfig().Sphinxconfig.Enable)
{
return GetSphinxSqlService().GetSearchPostContentSQL(posterId, searchForumId, resultOrder, resultOrderType, searchTime, searchTimeType, postTableId, strKeyWord);
}
StringBuilder sqlBuilder = new StringBuilder();
string orderfield = " lastpost " ;
switch (resultOrder)
{
case 1 :
orderfield = " tid " ;
break ;
......
通过上述代码,可以看出GetSphinxSqlService()这个方法就是提供SPHINX查询和数据服务的接口,该接口定义如下:
/// 查询服务数据操作接口
/// </summary>
public interface ISqlService
{
/// <summary>
/// 创建Sphinx的数据表(目前只支持mysql数据库类型)
/// </summary>
/// <param name="tableName"> 当前分表名称 </param>
/// <returns></returns>
bool CreatePostTable( string tableName);
/// <summary>
/// 创建Sphinx数据表帖子
/// </summary>
/// <param name="tableName"> 当前分表名称 </param>
/// <param name="pid"> 帖子ID </param>
/// <param name="tid"> 主题ID </param>
/// <param name="fid"> 所属版块ID </param>
/// <param name="posterid"> 发帖人 </param>
/// <param name="postdatetime"> 发帖日期 </param>
/// <param name="title"> 标题 </param>
/// <param name="message"> 内容 </param>
/// <returns></returns>
int CreatePost( string tableName, int pid, int tid, int fid, int posterid, string postdatetime, string title, string message);
/// <summary>
/// 更新Sphinx数据表帖子
/// </summary>
/// <param name="tableName"> 当前分表名称 </param>
/// <param name="pid"> 帖子ID </param>
/// <param name="tid"> 主题ID </param>
/// <param name="fid"> 所属版块ID </param>
/// <param name="posterid"> 发帖人 </param>
/// <param name="postdatetime"> 发帖日期 </param>
/// <param name="title"> 标题 </param>
/// <param name="message"> 内容 </param>
/// <returns></returns>
int UpdatePost( string tableName, int pid, int tid, int fid, int posterid, string postdatetime, string title, string message);
/// <summary>
/// 获取要搜索的主题ID(Tid)信息
/// </summary>
/// <param name="posterId"> 发帖者id </param>
/// <param name="searchForumId"> 搜索版块id </param>
/// <param name="resultOrder"> 结果排序方式 </param>
/// <param name="resultOrderType"> 结果类型类型 </param>
/// <param name="searchTime"> 搜索时间 </param>
/// <param name="searchTimeType"> 搜索时间类型 </param>
/// <param name="postTableId"> 当前分表ID </param>
/// <param name="strKeyWord"> 关键字 </param>
/// <returns></returns>
string GetSearchPostContentSQL( int posterId, string searchForumId, int resultOrder, int resultOrderType, int searchTime, int searchTimeType, int postTableId, System.Text.StringBuilder strKeyWord);
}
设计这个接口的目的首先是解除Discuz.EntLib.dll与其它DLL文件的互相依赖。第二就是为了当本机用户发表或更新帖子信息时,会调用这个接口的中的相应方法来创建(CreatePost)或更新(UpdatePost)mysql数据库中的相应帖子记录,以确保sphinx获取索引数据的有效性。
可以通过反射的方法实例化该接口对象以便访问其中的方法,如下(GlobalManage.cs):
private static SphinxConfig.ISqlService sphinxSqlService;
private static SphinxConfig.ISqlService GetSphinxSqlService()
{
if (sphinxSqlService == null )
{
try
{
sphinxSqlService = (SphinxConfig.ISqlService)Activator.CreateInstance(Type.GetType( " Discuz.EntLib.SphinxClient.SphinxSqlService, Discuz.EntLib " , false , true ));
}
catch
{
throw new Exception( " 请检查BIN目录下有无Discuz.EntLib.dll文件 " );
}
}
return sphinxSqlService;
}
#endregion
而在Discuz.EntLib中提供了该接口的MYSQL类型数据库实现方法(Discuz.EntLib/SphinxClient/SphinxSqlService.cs),如下:
{
private SphinxConfig sphinxConfig = EntLibConfigs.GetConfig().Sphinxconfig;
public int CreatePost( string tableName, int pid, int tid, int fid, int posterid, string postdatetime, string title, string message)
{
DbParameter[] prams = {
MakeParam( " ?pid " , (DbType)MySqlDbType.Int32, 4 , ParameterDirection.Input, pid),
MakeParam( " ?tid " , (DbType)MySqlDbType.Int32, 4 , ParameterDirection.Input, tid),
MakeParam( " ?fid " , (DbType)MySqlDbType.Int16, 2 , ParameterDirection.Input, fid),
MakeParam( " ?posterid " , (DbType)MySqlDbType.Int32, 4 , ParameterDirection.Input, posterid),
MakeParam( " ?postdatetime " , (DbType)MySqlDbType.VarString, 20 , ParameterDirection.Input, postdatetime),
MakeParam( " ?title " , (DbType)MySqlDbType.VarString, 60 , ParameterDirection.Input, title),
MakeParam( " ?message " , (DbType)MySqlDbType.Text, 0 , ParameterDirection.Input, message)
};
string commandText = " SET NAMES utf8;INSERT INTO ` " + tableName + " ` (`pid`,`tid`,`fid`,`posterid`,`postdatetime`,`title`,`message`) VALUES(?pid,?tid,?fid,?posterid,?postdatetime,?title,?message) " ;
try
{
return TypeConverter.ObjectToInt(ExecuteScalar(commandText, prams));
}
catch
{
CreatePostTable(tableName);
return TypeConverter.ObjectToInt(ExecuteScalar(commandText, prams));
}
}
public bool CreatePostTable( string tableName)
{
EntLibConfigInfo entLibConfigInfo = EntLibConfigs.GetConfig();
// 数据库MY.ini文件中也要指定或在安装实例是即指定为utf-8
// SET NAMES utf8;CREATE DATABASE IF NOT EXISTS test;
string commandText = string .Format( " SET NAMES utf8; " +
" CREATE TABLE IF NOT EXISTS `{0}` ( " +
" `pid` INT(11) NOT NULL , " +
" `tid` INT(11) NOT NULL , " +
" `fid` INT(11) NOT NULL , " +
" `posterid` INT(11) NOT NULL , " +
" `postdatetime` DATETIME NOT NULL, " +
" `title` varchar(60) NOT NULL, " +
" `message` TEXT NOT NULL, " +
" PRIMARY KEY (`pid`) " +
" ) DEFAULT CHARSET=utf8; " ,
tableName);
ExecuteScalar(commandText, null );
return true ;
}
public int UpdatePost( string tableName, int pid, int tid, int fid, int posterid, string postdatetime, string title, string message)
{
DbParameter[] prams = {
MakeParam( " ?pid " , (DbType)MySqlDbType.Int32, 4 , ParameterDirection.Input, pid),
MakeParam( " ?tid " , (DbType)MySqlDbType.Int32, 4 , ParameterDirection.Input, tid),
MakeParam( " ?fid " , (DbType)MySqlDbType.Int16, 2 , ParameterDirection.Input, fid),
MakeParam( " ?posterid " , (DbType)MySqlDbType.Int32, 4 , ParameterDirection.Input, posterid),
MakeParam( " ?postdatetime " , (DbType)MySqlDbType.VarString, 20 , ParameterDirection.Input, postdatetime),
MakeParam( " ?title " , (DbType)MySqlDbType.VarString, 60 , ParameterDirection.Input, title),
MakeParam( " ?message " , (DbType)MySqlDbType.Text, 0 , ParameterDirection.Input, message)
};
string commandText = " SET NAMES utf8;UPDATE ` " + tableName + " ` SET `tid` = ?tid, `fid` = ?fid, `posterid`= ?posterid,`postdatetime` = ?postdatetime,`title` = ?title, `message` = ?message WHERE `pid` = ?pid " ;
try
{
return ExecuteNonQuery(commandText, prams);
}
catch
{
return 0 ;
}
}
public string GetSearchPostContentSQL( int posterId, string searchForumId, int resultOrder, int resultOrderType, int searchTime, int searchTimeType, int postTableId, StringBuilder strKeyWord)
{
if ( string .IsNullOrEmpty(strKeyWord.ToString()))
return "" ;
SphinxClient cli = new SphinxClient(sphinxConfig.SphinxServiceHost, sphinxConfig.SphinxServicePort);
cli.SetLimits( 0 , 300000 ); // 30万条数据(单个帖子分表一般不应超过30万条记录)
if (searchForumId != "" )
cli.SetFilter( " fid " , TypeConverter.StrToInt(searchForumId), false );
if (posterId != - 1 )
cli.SetFilter( " posterid " , posterId, false );
if (searchTime != 0 )
{
if (searchTimeType == 1 ) // "<" 多少天之前 即: searchTimeType == 1
cli.SetFilterRange( " postdatetime " , DateTimeHelper.ConvertToUnixTimestamp(DateTime.Now.AddYears( - 10 )), DateTimeHelper.ConvertToUnixTimestamp(DateTime.Now.AddDays(searchTime)), false );
else // ">" 多少天之内
cli.SetFilterRange( " postdatetime " , DateTimeHelper.ConvertToUnixTimestamp(DateTime.Now.AddDays(searchTime)), DateTimeHelper.ConvertToUnixTimestamp(DateTime.Now), false );
}
if (resultOrderType == 1 ) // " ASC"
cli.SetGroupBy( " tid " , ( int )ResultsGroupFunction.Attribute, " tid ASC " );
else // DESC
cli.SetGroupBy( " tid " , ( int )ResultsGroupFunction.Attribute);
cli.SetGroupDistinct( " tid " );
string orderBy = "" ;
switch (resultOrder)
{
case 1 : // tid
orderBy = " tid " ;
break ;
case 2 : // replies
orderBy = " tid " ;
break ;
case 3 : // views
orderBy = " tid " ;
break ;
default :
orderBy = " postdatetime " ;
break ;
}
cli.SetSortMode(( int )ResultsSortMode.Extended, orderBy + (resultOrderType == 1 ? " ASC " : " DESC " ));
foreach ( string keyword in Utils.SplitString(strKeyWord.ToString(), " " ))
{
cli.AddQuery(keyword, BaseConfigs.GetTablePrefix + " posts " + postTableId); // 搜索主索引
cli.AddQuery(keyword, BaseConfigs.GetTablePrefix + " posts " + postTableId + " _stem " ); // 搜索增量索引
}
cli.SetWeights( new int [] { 1 , 100 });
SphinxResult[] results = cli.RunQueries();
string postid = "" ;
foreach (SphinxResult sr in results)
{
foreach (SphinxMatch sphinxMatch in sr.matches)
{
if (postid.Length < 280000 ) // 防止SQL语句过长而无法被执行,这里指定最长为28万
{
postid += sphinxMatch.docId + " , " ;
}
}
}
if ( string .IsNullOrEmpty(postid)) // 当没有搜索到任何数据时
return "" ;
StringBuilder sqlBuilder = new StringBuilder();
sqlBuilder.AppendFormat( " SELECT [{0}posts{1}].[tid] FROM [{0}posts{1}] LEFT JOIN [{0}topics] ON [{0}topics].[tid]=[{0}posts{1}].[tid] WHERE [{0}posts{1}].[pid] IN ({2}) AND [{0}topics].[displayorder]>=0 " ,
BaseConfigs.GetTablePrefix,
postTableId,
postid.TrimEnd( ' , ' ));
return sqlBuilder.ToString();
}
....
}
上面方法中的GetSearchPostContentSQL即是SPHINX查询对象的构造和执行过程了,大家可以参照SPHINX的官方文档或之前所说的那个中文文档来查询对应的语句语法。如果该方法执行正确,就会获取一个SQL语句,该语句与SQLSERVER进行全文检索时所调用的方法返回的SQL语句结果相同。
不过上面代码中的这段代码要在这里解释一下,因为它与后面所讲述的“增量索引”是相互对应的:
{
cli.AddQuery(keyword, BaseConfigs.GetTablePrefix + " posts " + postTableId); // 搜索主索引
cli.AddQuery(keyword, BaseConfigs.GetTablePrefix + " posts " + postTableId + " _stem " ); // 搜索增量索引
}
上面代码是执行查询时所使用的索引名称和关键字绑定,因为考虑到创建大数据量表索引时的时间会相对较长,所以这里引入了增量索引,也就是主索引中存储的是整个数据表中的索引信息(某时间段之前),而增量索引只保存指定条件(会在下文中说明)的"新记录(某时间段之后)"信息。我们可以让“创建主索引”的工作在一天中服务器最闲的时候来生成(比如凌晨4-5点钟),而增量索引每几分钟(甚至一分钟)生成一次。这样当查询时我们同时指定这两个索引来能实现“准实时”的查询效果了。
除了在搜索时调用了该服务接口的相应方法,再有就是在创建或更新帖子信息时也调用了相应方法,比如创建帖子时(Discuz.Forum/Posts.cs):
/// 创建帖子
/// </summary>
/// <param name="postInfo"> 帖子信息类 </param>
/// <returns> 返回帖子id </returns>
public static int CreatePost(PostInfo postInfo)
{
int pid = Data.Posts.CreatePost(postInfo, GetPostTableId(postInfo.Tid));
// 本帖具有正反方立场
if (postInfo.Debateopinion > 0 )
{
DebatePostExpandInfo dpei = new DebatePostExpandInfo();
dpei.Tid = postInfo.Tid;
dpei.Pid = pid;
dpei.Opinion = postInfo.Debateopinion;
dpei.Diggs = 0 ;
Data.Debates.CreateDebateExpandInfo(dpei);
}
RemoveShowTopicCache(postInfo.Tid.ToString());
// 将数据同步到sphinx增量表中
if (pid > 0 && EntLibConfigs.GetConfig() != null && EntLibConfigs.GetConfig().Sphinxconfig.Enable)
{
GetSphinxSqlService().CreatePost(GetPostTableName(), pid, postInfo.Tid, postInfo.Fid, postInfo.Posterid, postInfo.Postdatetime, postInfo.Title, postInfo.Message);
}
return pid;
}
和更新帖子时:
/// 更新指定帖子信息
/// </summary>
/// <param name="postsInfo"> 帖子信息 </param>
/// <returns> 更新数量 </returns>
public static int UpdatePost(PostInfo postInfo)
{
if (postInfo == null || postInfo.Pid < 1 )
return 0 ;
RemoveShowTopicCache(postInfo.Tid.ToString());
// 将数据同步到sphinx增量表中
if (postInfo.Pid > 0 && EntLibConfigs.GetConfig() != null && EntLibConfigs.GetConfig().Sphinxconfig.Enable)
{
GetSphinxSqlService().UpdatePost(GetPostTableName(), postInfo.Pid, postInfo.Tid, postInfo.Fid, postInfo.Posterid, postInfo.Postdatetime, postInfo.Title, postInfo.Message);
}
return Data.Posts.UpdatePost(postInfo, GetPostTableId(postInfo.Tid));
}
到这时,架构中的Discuz!NT客户端部分甚本上就介绍完了。下一篇文章中将会介绍在服务器如果安装,配置SPHINX以及定时生成主和增量索引等工作。
原文链接:http://www.cnblogs.com/daizhj/archive/2010/06/28/discuznt_entlib_sphinx_one.html
BLOG: http://daizhj.cnblogs.com/
作者:daizhj,代震军