Python结合BeautifulSoup抓取知乎数据
本文主要介绍利用Python登录知乎账号,抓取其中的用户名、用户头像、知乎的问题、问题来源、被赞数目、以及回答者。其中数据是配合Beautiful Soup进行解析的。
首先,要解决的是知乎登录问题。在程序中登录知乎我们直接提供用户名和密码是无法进行登录的,这里我们采用一个比较笨拙的办法直接在发送请求过程中附带上cookies。这个cookies值我们可以通过在火狐浏览器登录知乎时用firebug直接捕获。cookies获取如下图所示:
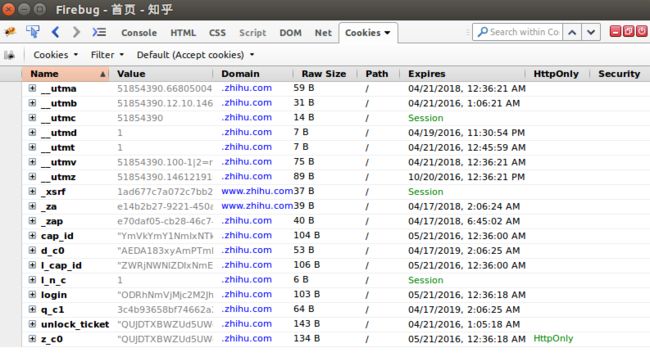
[info]
email =youremail
password = youpassword
[cookies]
q_c1 =
cap_id =
_za =
__utmt =
__utma =
__utmb =
__utmc =
__utmz =
__utmv =
z_c0 =
unlock_ticket = 然后我们可以利用python的requests模块、urllib、urllib2模块实现如下登录代码:
#知乎登录
def create_session():
cf = ConfigParser.ConfigParser()
cf.read('config.ini')
#从配置文件获取cookies值,并转化为dict
cookies = cf.items('cookies')
cookies = dict(cookies)
from pprint import pprint
pprint(cookies)
#获取登录名
email = cf.get('info', 'email')
#获取登录密码
password = cf.get('info', 'password')
session = requests.session()
login_data = {'email': email, 'password': password}
header = {
'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/43.0.2357.124 Safari/537.36',
'Host': 'www.zhihu.com',
'Referer': 'http://www.zhihu.com/'
}
#post登录
r = session.post('http://www.zhihu.com/login/email', data=login_data,
headers=header)
if r.json()['r'] == 1:
print 'Login Failed, reason is:',
for m in r.json()['data']:
print r.json()['data'][m]
print 'So we use cookies to login in...'
has_cookies = False
for key in cookies:
if key != '__name__' and cookies[key] != '':
has_cookies = True
break
if has_cookies is False:
raise ValueError('请填写config.ini文件中的cookies项.')
else:
r = session.get('http://www.zhihu.com/login/email',
cookies=cookies) # 用cookies登录
return session, cookies登录是否成功我们可以查看保存的请求返回的网页是否包含登录用户名。登录成功后我们利用BeautifulSoup 的构造方法将请求后获得的知乎页面文档进行构造得到一个文档的对象。这个转换过程中首先,文档被转换成Unicode,并且HTML的实例都被转换成Unicode编码,然后,Beautiful Soup选择最合适的解析器来解析这段文档,如果手动指定解析器那么Beautiful Soup会选择指定的解析器来解析文档。Beautiful Soup将复杂HTML文档转换成一个复杂的树形结构,每个节点都是Python对象。我们可以通过这些节点结合原始HTML文件来提取我们需要的内容。如下图所示,是我们获取登录用户名和部分知乎问题在html文档中对应的部分。
我们完整的抓取以及数据提取代码如下所示:

# -*- coding: utf-8 -*-
''' 网络爬虫之用户名密码及验证码登陆:爬取知乎网站 '''
import requests
import ConfigParser
from bs4 import BeautifulSoup
import re
import urllib
import urllib2
def create_session():
cf = ConfigParser.ConfigParser()
cf.read('config.ini')
#从配置文件获取cookies值,并转化为dict
cookies = cf.items('cookies')
cookies = dict(cookies)
from pprint import pprint
pprint(cookies)
#获取登录名
email = cf.get('info', 'email')
#获取登录密码
password = cf.get('info', 'password')
session = requests.session()
login_data = {'email': email, 'password': password}
header = {
'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/43.0.2357.124 Safari/537.36',
'Host': 'www.zhihu.com',
'Referer': 'http://www.zhihu.com/'
}
#post登录
r = session.post('http://www.zhihu.com/login/email', data=login_data,
headers=header)
if r.json()['r'] == 1:
print 'Login Failed, reason is:',
for m in r.json()['data']:
print r.json()['data'][m]
print 'So we use cookies to login in...'
has_cookies = False
for key in cookies:
if key != '__name__' and cookies[key] != '':
has_cookies = True
break
if has_cookies is False:
raise ValueError('请填写config.ini文件中的cookies项.')
else:
r = session.get('http://www.zhihu.com/login/email',
cookies=cookies) # 用cookies登录
return session, cookies
if __name__ == '__main__':
requests_session, requests_cookies = create_session()
url = 'http://www.zhihu.com'
reqs= requests_session.get(url, cookies=requests_cookies) # 已登陆
content=reqs.content
#保存整个内容为html页面
with open('url.html', 'w') as fp:
fp.write(content)
soup=BeautifulSoup(content)
#获取登录用户名
user_name=soup.find("div",class_="top-nav-profile").a.span.string
print "user_name:%s" % (user_name)
#获取用户头像地址
pic_url=soup.find("div",class_="top-nav-profile").a.img
#下载用户头像
urllib.urlretrieve(pic_url['src'],'/home/zeus/pic1/'+'1.jpg')
print "potos:%s" %(pic_url['src'])
#获取前10个话题的内容
for topic in soup.find_all("div",class_="feed-main",limit=10):
print '-------------------------------------------------------'
#获取知乎问题来源
topic_source=topic.find("div",class_="feed-source").a.get_text()
print "topic source:%s" %(topic_source)
#获取知乎问题
question=topic.find("div",class_="content").a.get_text()
print "question:%s" %(question)
#获取该问题被赞次数
votecount=topic.find("div",class_="zm-item-vote").a.get_text()
print "votecount:%s" %(votecount)
#获取问题回答者的用户名
answer=topic.find("div",class_="zm-item-rich-text js-collapse- body")
if answer:
print "answer_name:%s" %(answer['data-author-name'])
print '-------------------------------------------------------'
我们运行代码得到如下结果:
对比浏览器页面的知乎数据:
抓取并保存的用户头像放在机器:/home/zeus路径下pic1文件夹下,图片名1.jpg。
可见我们的程序确实成功抓取到了登录用户的知乎数据。