(源码)关于A->B*->D的时间序列频繁模式挖掘的思考 1.26更新
这个算法是导师课题的一个部分,感觉对时间序列频繁模式挖掘的学习还是很有帮助的,在博客里做一下记录。
首先要明确一下什么是A->B*->D模式:
A->B->D表示在A事件发生后又发生了B事件,又发生了D事件,由于我应用在社交网络,那么这三种事件就可以表示为三个人在某微博下的留言。
什么是A->B*->D模式?这里的*表示不管在A与D时间发生的时间点当中有多少个B事件发生,都可以这个标记这种模式,比如:
A->B->B->D或A->B->B->B->D都可以写成A->B*->D的形式,但看A->B->D和A->B->B->D和A->B->B->B->D可能每个都不是频繁的,但如果把他们看成一种形式A->B*->D就有可能是频繁的,我所要解决的就是这个问题。
这里有个前提条件,就是我所研究的背景是社交网络,也就是说每个事件发生的时间点一定不可能一样,也就是说,每个事件之间一定有先后的发生顺序,综上所述,我只考虑时间序列的频繁模式挖掘,而不考虑传统的频繁模式挖掘。
程序流程图:
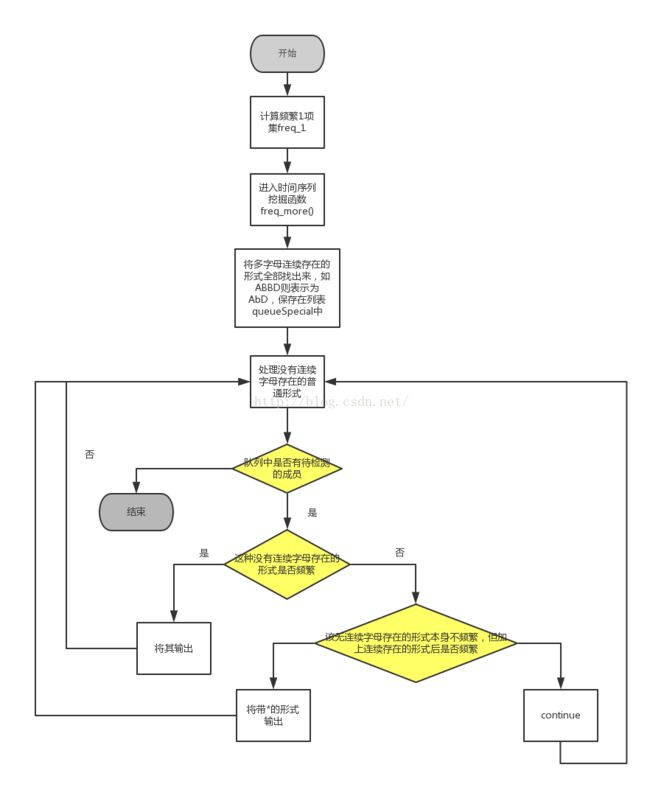
本算法里面的字母理论上应该是社交网络中的各个事件,目前正在搜索合适的数据集,将其封装成一个类就可以像算法里的字母一样表示了。数据集的搜索目前还在进行中。
1.26更新 ver1.1
增加多重序列识别功能:ABDBDF -> A(BD)F
增加多重序列内存在的多重序列识别功能 :
ABBDDBBDDF -> A(B)(D)(B)(D)F -> A(BD)F
增加多重序列内重复序列识别功能:
ABBBBF有这样一种形式 A(BB)F 可化为 A(B)F,目的是为了避免重复
源代码:(数据集是自己造的,比较具有代表性的小数据,肉眼可以识别出本算法在运行上没有问题)
#coding:utf-8
__author__ = 'ChiXu_15s103144_HIT'
import copy
import sys
#----------------------------------------------------------#
# 计算Frequent_1 #
#----------------------------------------------------------#
def freq1(dataSet, freq_num):
freq_1 = [] ; Ele = []
for i in range(len(dataSet)):
SID = splitToAlphabet(dataSet[i])
setSID = list(set(SID))
Ele += setSID
setEle = list(set(Ele))
for item in setEle:
if Ele.count(item) >= freq_num:
freq_1.append(item)
print('the Frequent_1 elements are:%s' %freq_1)
return freq_1
#----------------------------------------------------------#
# 计算Frequent_more #
#----------------------------------------------------------#
def freq_more(dataSet, freq_num, freq_1):
x = []
queue = []
queueBrief = []
for a in freq_1:
x.append(a)
queue.append(x)# queue = [['A'],['B'],['D'],['F']]
x = []
while queue != []: # 先处理多重形式
queueDemo = extendMember(queue, freq_1) # 扩展queue成员 example:[['A', 'A'], ['A', 'B'], ['A', 'D'], ['B', 'A'], ['B', 'B'], ['B', 'D'], ['D', 'A'], ['D', 'B'], ['D', 'D']]
queue = []
for item in queueDemo:
itemFreqNum = frequentNum(dataSet, item)
if itemFreqNum > 0: # 只要出现过
briefItemList = toBriefItem(item) # item的缩略形式 example: ['D(BD)', '(BB)D']
if briefItemList != []: # 如果有缩略形式的话
for BriefItem in briefItemList:
queueBrief.append(BriefItem)
queue.append(item)
else: # 如果没有缩略形式
queue.append(item)
print queueBrief
# 下面处理非多重形式
for a in freq_1:
x.append(a)
queue.append(x)# queue = [['A'],['B'],['D'],['F']]
x = []
# queueBrief去括号:
queueBriefNoBrancket = []
for briefString in queueBrief: # briefString: 'D(BD)'
briefAlphabet = splitToAlphabet(briefString) # briefAlphabet: ['D','(','B','D',')']
while '(' in briefAlphabet:
briefAlphabet.remove('(')
briefAlphabet.remove(')')
# 至此 briefAlphabet: ['D','B','D']
queueBriefNoBrancket.append(combinToString(briefAlphabet))
while queue != []:
queueDemo = extendMember(queue, freq_1)
queue = []
for item in queueDemo: # item: ['A','B','B']
itemFreqNum = frequentNum(dataSet, item)
itemBrief = toBriefItem(item) # itemBiref:有缩略形式:['A(B)'] 没有:[]
if itemFreqNum >= freq_num or (itemBrief!=[] and queueBrief.count(itemBrief) >= freq_num):
print('频繁的形式: %s' %item)
queue.append(item)
#----------------------------------------------------------#
# 将queue成员进行扩展 #
#----------------------------------------------------------#
def extendMember(queue, freq_1): #queueDemo
queueDemo = []
for item in queue:
itemString = combinToString(item)
for alphabet in freq_1:
String = itemString + alphabet
queueDemo.append(splitToAlphabet(String))
#print(queueDemo)
return queueDemo
#----------------------------------------------------------#
# 计算item频度 ##
#----------------------------------------------------------#
def frequentNum(dataSet, item): #freq_num
# item: ['A','B','B','D']
flag = 0
alphabetAppearTimes = 0
freq_num = 0
for SID in dataSet:
SIDalphabetList = splitToAlphabet(SID) # 将该SID分解为字母列表
for alphabet in item:
if alphabet in SIDalphabetList: # 该字母存在于SID中
while flag <= len(SIDalphabetList)-1:
if SIDalphabetList[flag] == alphabet:
flag += 1
alphabetAppearTimes += 1 # 记录有几个item字母在该SID中出现过
break
else:
flag += 1
else:
break # item中某个字母在列表中没有出现则不用检查SID了
if alphabetAppearTimes == len(item): # 这几个字母都在这个SID中出现了
freq_num += 1
flag = 0
alphabetAppearTimes = 0
return freq_num
#----------------------------------------------------------#
# ABBD -> A(B)D #
#----------------------------------------------------------#
def toBriefItem(item): #briefItem
# item = ['A','B','D','B','D','F'] 每一个扩展的成员
briefItem = [] # return
queue = [] # 待鉴别列表
briefItemDemo = [] # example: ['D(B)DBDBD', 'DB(BD)', 'DBB(DB)D', '(DB)D', 'D(BD)']
item.append('')
item.insert(0, '')
queue.append(item)
while queue != []:
lenth = 1 # 识别字符串的长度
alphabetList = queue[0]
alphabetListLenth = len(alphabetList) # 不算首末的空位
del queue[0] # 删除第一个待鉴别成员
while lenth <= (alphabetListLenth)/2: # 以lenth长的串为一组,寻找相邻组有没有相重的
flag = 0
for i in range(lenth):
groupNewDemo = []
group = makeGroup(alphabetList, lenth, flag) # 进行分组,比如两两一组或者三三一组,flag是分组的起始位置
longestNum = longestItemNum(group, lenth) # 看两两一组或者三三一组的组数有多少
if longestNum == 1:
break
else:
groupNew = copy.deepcopy(group)
j = flag+1
while j<len(groupNew)-1:
if groupNew[j]==groupNew[j+1] and groupNew[j]!=groupNew[j-1] and len(groupNew[j])==len(groupNew[j+1])==lenth: # 添加左括号
groupNew.insert(j, '(')
j += 2
elif groupNew[j]!=groupNew[j+1] and groupNew[j]==groupNew[j-1] and len(groupNew[j])==len(groupNew[j-1])==lenth: # 添加右括号
groupNew.insert(j+1, ')')
j += 2
else:
j += 1
# example: groupNew = ['','A','(','BD','BD',')','F','']
sign = 1
if '(' in groupNew:
while sign<len(groupNew)-1: # 只要groupNew里面还有未处理的对子
if groupNew[sign]!='(':
groupNewDemo.append(groupNew[sign])
sign += 1
else: # 遇到了'('
groupNewDemo.append('(')
groupNew.remove('(')
groupNewDemo.append(groupNew[sign])
groupNewDemo.append(')')
positionBracket = groupNew.index(')')
groupNew.remove(')')
sign = positionBracket
for i in range(sign, len(groupNew)-1):
groupNewDemo.append(groupNew[sign])
# groupNewDemo = ['A','(','BD',')','F']
#下面判断括号里面有没有重复的形式,反例: 'A(BCBC)D' 或 'A(BB)D'
while '(' in groupNewDemo:
positionBrancketLeft = groupNewDemo.index('(')
# 'BB' -> ['B','B']
checkedString = splitToAlphabet(groupNewDemo[positionBrancketLeft+1])
if toBriefItem(checkedString) != []: # 遇到'BB'或者'BDBD'这样的形式的话
break
else:
sys.stdout.write('item:%s -> ' %combinToString(item)) # print: ABDBDF
print(combinToString(groupNewDemo)) # print: A(BD)F
briefItemDemo.append(combinToString(groupNewDemo))
groupNewDemo.remove('(') # 去除从左到右第一个'('
groupNewDemo.remove(')') # 去除从左到右第一个')'
# 至此括号里的对子都只缩到一个了
x = []
k = 0
if '(' in groupNewDemo:
while k < len(groupNewDemo):
if groupNewDemo[k]!='(' and groupNewDemo[k]!=')':
x.append(groupNewDemo[k])
k = k+1
else:
k = k+1
#briefItem.append(x)
x.append('')
x.insert(0, '')
queue.append(x) # 增加一个鉴别成员
flag += 1
lenth += 1
# 去掉list中首末的''
for i in range(len(briefItem)):
briefItem[i].pop(0)
briefItem[i].pop(-1)
item.pop(-1)
item.pop(0)
#下面选出最短字符串的,带括号的字串
i = len(briefItemDemo) - 1
while i >= 0:
if len(briefItemDemo[i]) > len(briefItemDemo[-1]):
break
else:
briefItem.append(briefItemDemo[i])
i -= 1
return briefItem
# example: briefItem:['D(BD)', '(DB)D']
#----------------------------------------------------------#
# 计算item在全转成大写的特殊列表中存在的次数 #
#----------------------------------------------------------#
def changeSpecialNum(changeSpecial, item): #appearTimes
if item not in changeSpecial:
return 0
else:
appearTimes = changeSpecial.count(item)
return appearTimes
#----------------------------------------------------------#
# 将字符串分解为字母 ##
#----------------------------------------------------------#
def splitToAlphabet(item): #alphabetList
alphabetList = []
for i in range(len(item)):
alphabetList.append(item[i])
return alphabetList
#----------------------------------------------------------#
# 将字母合成成字符串 ##
#----------------------------------------------------------#
def combinToString(briefItemList): #briefItem
briefItem = ''
for alphabet in briefItemList:
briefItem += alphabet
return briefItem
#----------------------------------------------------------#
# 将字符串进行分组 # alphabetList=['','A','B','B','B','D','']
#----------------------------------------------------------#
def makeGroup(alphabetList, num, flag): # group num:几几一组
alphabet = ''
alphabetListNew = []
#alphabetList = ['A','B','B','B','D']
if num == 1:
#print(alphabetList)
return alphabetList
else:
alphabetList.pop(0)
alphabetList.pop(-1) # 把首末的空位去掉
for i in range(flag):
alphabetListNew.append(alphabetList[i])
while len(alphabetList) - flag >= num:
for i in range(num):
alphabet += alphabetList[flag+i]
alphabetListNew.append(alphabet)
flag = flag + num # 标志位后移num
alphabet = ''
for i in range(flag, len(alphabetList)): # 把剩下几个字母扔进去
alphabetListNew.append(alphabetList[i])
alphabetListNew.insert(0, '')
alphabetListNew.append('')
# alphabetListNew = ['','AB','BB','D','']
#print(alphabetListNew)
alphabetList.append('')
alphabetList.insert(0, '')
return alphabetListNew
#----------------------------------------------------------#
# 两两一组或三三一组的组数有多少 #
#----------------------------------------------------------#
def longestItemNum(group, lenth):
longest = 0
itemNum = 0
if lenth == 1:
return len(group) - 2
else:
for item in group:
if len(item) == longest:
itemNum += 1
elif len(item) > longest:
itemNum = 1
longest = len(item)
else:
continue
return itemNum
#main
#dataSet = ['ABDBD','FDDDA','BDBDD','ABDFF','BDDBFBD']
dataSet = ['ABD','ABBD','ABBBD']
freq_1 = freq1(dataSet, 2)
freq_more(dataSet, 2 , freq_1)
#makeGroup(['','A','B','B','D','D','B','B','D','D','F',''], 3, 0)
#toBriefItem(['A','B','F','B','F','B','F','B','F','D','A','A'])
#longestItemNum(['','A','B','BDD','BBD','ABC','D',''], 3)
#extendMember([['A'],['B'],['D'],['F']], ['A','B','D','F'])