CUDA系列学习(三)GPU设计与结构QA & coding练习
啥?你把CUDA系列学习(一),(二)都看完了还不知道為什麼要用GPU提速? 是啊。。经微博上的反馈我默默感觉到提出这样问题的小伙伴不在少数,但是更多小伙伴应该是看了(一)就感觉离自己太远所以赶紧撤粉跑掉了。。。都怪我没有写CUDA系列学习(零)。。。那么,这一章就补上这一块,通过一堆Q&A进行讲解,并辅助coding练习,希望大家感觉贴近CUDA是这么容易~~
请注意各个Q&A之间有顺序关系,轻依次阅读~ 否则不容易懂喔~
Q:现在硬件层面通常通过什么样的方法加速?
A:
- More processors
- Speed up clock frequency
- More memory
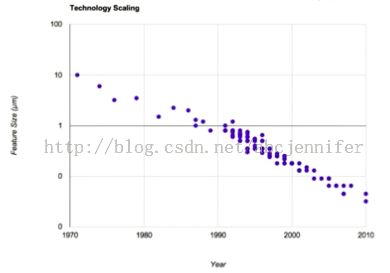
途径:将晶体管做得更快更小,功耗更少,那么每块芯片上就可以放更多transistor
宏观上看,一个处理器上能同时处理的数据就越多。
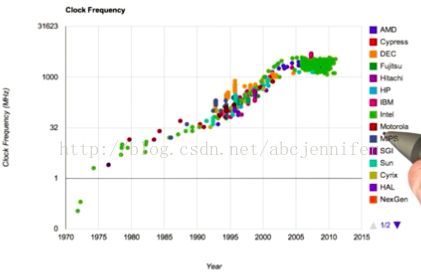
A:是晶体管不能做得更快更小了么?错!
- 关键问题在散热!即便晶体管越做越小也难以散热。所以,现在我们应该着眼于build更多小而低功耗(power-efficient)的processor来提速。
Q:CPU和GPU在设计上的区别?
A:
CPU: COMPLEX CONTROL HARDWARE
- flexible in performance :)
- expensive in terms of power :(
GPU: SIMPLE CONTROL HARDWARE
- more hardware for computation :)
- more power efficient :)
- more restrictive programming model :(
所以刚才说到的,目前想要设计更多power-efficient的处理器就是GPU的中心思想;CPU更重视优化 (minimize) latency而GPU更重视优化 (maximize) throughput。
A:
比如,要驾车行驶5000km从A到B。
方法1:
by taxi,200km/h,可承载2人:latency = 25h,throughput = 2/25 person/h
方法2:
by bus, 50km/h, 可以承载10人:latency=100h,throughput = 10/100 person/h
所以CPU更喜欢taxi,因为一次过来速度快,GPU更喜欢bus,因为吞吐量大。
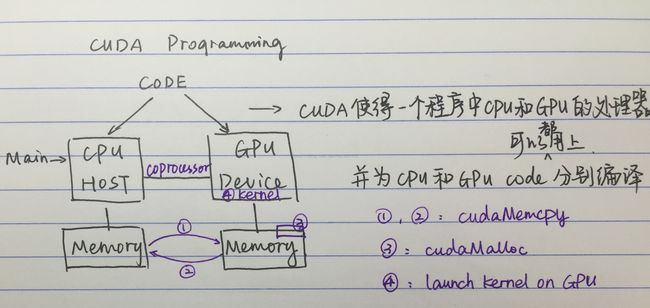
Q:CUDA是啥?CUDA programming软件层面的结构?
A:
Q:CUDA编程注意什么?
A: 注意GPU擅长什么!
- efficiency launching lots of threads
- running lots of threads in parallel
Q: kernel声明时对参数有没有限制?
A:
我们在CUDA系列学习(一)An Introduction to GPU and CUDA 中讲过kernel的声明:kernel<<<grid of blocks, block of threads>>> ,其限制是:maximum number of threads per block: 1024 for new, 512 for old。比如说,我希望2048个线程并行,不能直接申请kernel<<<1,2048>>>,而应该分开<<<a,b>>>,使a*b=2048 且a<=1024 && b<=1024.
Q: 具体讲一下kernel的general声明,参数意义与格式?
A: general表示:kernel<<<grid of blocks, block of threads, shmem>>>
shmem:shared memory per block in bytes
用G表示grid of blocks
用B表示block of threads
事实上,dim(x,y,z)中每一维默认都为1,所以:dim3(w,1,1)==dim3(w)==int w,即这三种表示是等效的
Q:CUDA程序中能够调用的常用 built-in variables都有哪些?
A:threadIdx, blockDim, blockIdx, gridDim
Q: CUDA程序模板来一个?
A: 说是模板,只是一个简单例子的大概套路,大家也可以参考CUDA系列学习(二)CUDA memory & variablesdifferent memory and variable types,如下:
1. 声明host变量,申请分配空间,并初始化
2. 声明device变量,申请分配空间
3. cudamemcpy将赋值了的host变量赋给device变量
4. 调用cuda kernel,并行跑线程
5. device返回结果传给host
6. 释放device变量memory
========================================
Exercise1:
input: float array [0, 1, 2, ... 63]
output: float array [0^2, 1^2, 2^2, ... 63^2]
Exercise2:
输入一张彩色图,转灰度图。
提示:
in CUDA, each pixel is represented in struct uchar4:
unsigned char r,b,g,w;//w: alpha channel, represent the transparent information
灰度转换公式:I = .299*r+.587*g+.114b(给rbg设置不同weight是人眼对不同通道的敏感度不同所致)
具体实现请参考 CUDA系列学习(二)CUDA memory & variablesdifferent memory and variable types,欢迎小伙伴们把exercise code和运行时间贴上来回复,最好和cpu版本有所比较~
参考资料:
udacity - cs344
from: http://blog.csdn.net/abcjennifer/article/details/42778711