spark中stream编程指导(一)
概述
spark stream是对spark核心api的扩展,其有着很好的扩展性,很高的吞吐量以及容错性的动态数据的流式处理过程。数据可以来自不同的数据源,例如Kafka, Flume, Twitter, ZeroMQ, Kinesis, or TCP sockets,一些具有高级功能的复杂的算法,例如map,reduce,join andwindow,可以使用这些算法来进行数据的处理。最终,将数据推送到文件系统,数据库和仪表盘上。实际上,在数据流的处理过程中,可以使用机器学习算法和“图处理"(graph processing)算法。

从内部来看,其工作流程如下。spark流式处理接收动态输入数据流并且将数据切分成块(batch),随后spark引擎将会处理这些batch,以batch的形式来生成最后的结果流。

spark 流式处理提供了一种高级抽象的概念,叫作离散化流或是DStream,其表现为一种持续不断的数据流, DStreams可以以多种形式被创建,可以从输入数据流,例如Kafka, Flume, and Kinesis这样的数据源来进行创建,也可以将其他的DStream应用一些高级的操作进行DStream之间的转换。系统内部可以理解为,一个DStream就是一连串的RDD。
注意:spark流式处理的Python API在spark1.2之后已经有了。对于java和scala的api一直都是支持的,但是,需要注意的是对于流式处理的数据源的形式,现在spark只是支持基本的数据源类型,例如text file 或是text data,对于一些工具的数据源,例如Kafka and Flume,在今后的版本中会进行添加。
快速事例
下面是一个事例程序,该程序主要功能是计算文本数据的字数,这些数据来自于监听的一个数据服务器的TCP套接字端口。StreamingContext是所有流式处理程序的主要入口(类似于spark其他程序中的SparkContext),其中两个参数第一个为SparkConf设置的内容,第二个是设置每个几秒产生一个batch。
import org.apache.spark._ import org.apache.spark.streaming._ import org.apache.spark.streaming.StreamingContext._ // not necessary since Spark 1.3 // Create a local StreamingContext with two working thread and batch interval of 1 second. // The master requires 2 cores to prevent from a starvation scenario. val conf = new SparkConf().setMaster("local[2]").setAppName("NetworkWordCount") val ssc = new StreamingContext(conf, Seconds(1)) 利用上面的StreamingContext我们可以创建出DStream,这个DStream代表了来自TCP数据源的流式数据,方法参数 为主机名和端口(如下);
// Create a DStream that will connect to hostname:port, like localhost:9999
val lines = ssc.socketTextStream("localhost", 9999) 上面的lines DStream表示着从数据服务器中接收来的流式数据。在DStream中的每一条记录就是文本中的一行,接下 来我们将要把每一行数据按空格来切分成单词。
// Split each line into words
val words = lines.flatMap(_.split(" "))
flatmap函数是一个一对多的DStream操作,它在DStream数据源中从每条记录通过生成多条新记录可以创建一个新的
DStream。在这个例子中,每一行将被分解成多个单词并且单词流用words DStream来进行表示。随后我们将计算单
词数量。
// Count each word in each batch
val pairs = words.map(word => (word, 1))
val wordCounts = pairs.reduceByKey(_ + _)
// Print the first ten elements of each RDD generated in this DStream to the console
wordCounts.print()
words DStream被进一步的map成为(word,1)对式的DStream(mapped的过程是transformation的过程,一对一
的),随后这些pairs将会按照上面(key,value)的形式来统计每个数据batch中单词出现的频次,wordCounts.print()
函数可以将每秒产生的次数打印输出。需要注意的是,当这些代码执行的时候,spark流式处理仅仅设置计算,当程序开始
的时候,代码会执行,但是正真的处理过程还没有开始,在所有的transformation都被设置好了以后,要开始处理过程,
我们可以调用如下函数
ssc.start() // Start the computation
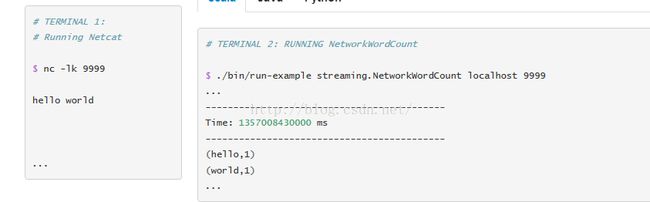
ssc.awaitTermination() // Wait for the computation to terminate 这段代码是spark当中的一个例子,可以在example下面找到,接下来开启端口在Linux下面:$ nc -lk 9999
接下来在spark控制台每隔一秒就会有“字对”显示,如下图
spark流式处理基本流程
Linking
与spark相似,spark流式处理也是用maven工具或是sbt工具来构建我们的工程,下面是流式编程的核心依赖
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-streaming_2.10</artifactId>
<version>1.4.1</version>
</dependency>
对于从源中获取数据例如 Kafka, Flume, and Kinesis,在SparkStreaming的核心api中并没有现成的接口,那么我们 必须从下面选择相应的依赖来进行添加,如下举出了部分依赖
| Source | Artifact |
|---|---|
| Kafka | spark-streaming-kafka_2.10 |
| Flume | spark-streaming-flume_2.10 |
| Kinesis | spark-streaming-kinesis-asl_2.10 [Amazon Software License] |
| spark-streaming-twitter_2.10 | |
| ZeroMQ | spark-streaming-zeromq_2.10 |
| MQTT | spark-streaming-mqtt_2.10 |
添加最新版本的依赖,关注Maven repository。
Initializing StreamingContext
要初始化Spark Streaming program,一个StreamingContext对象必须在所有spark流式处理的主函数入口被显示创建
一个 StreamingContext 对象可以从SparkConf对象中创建。
import org.apache.spark._
import org.apache.spark.streaming._
val conf = new SparkConf().setAppName(appName).setMaster(master)
val ssc = new StreamingContext(conf, Seconds(1)) 注意:在内部创建了SparkContext,他可以被访问按如下形式ssc.sparkContext.
import org.apache.spark.streaming._
val sc = ... // existing SparkContext
val ssc = new StreamingContext(sc, Seconds(1)) 在context被定义以后,你必须做一下几件事情: - 定义创建 input DStreams的输入源.
- 通过在DStreams上应用transformation和output operation来定义流式计算。
- 使用
streamingContext.start()来开始接收数据并且处理它
- 使用
streamingContext.等待处理或者是直接通过手动或是错误来停止 .awaitTermination() - 处理过程可以被自动停止使用
streamingContext.stop().
要点:
- context一旦开始,新的流式计算将不能被设置或者加入。
- 流式处理一旦被停止,将不能被自动重启。
- 在一个JVM中,同一时刻,只能有一个StreamingContext处理活跃状态.
- StreamingContext 中的stop()也可以是SparkContext停止运行,如果只想停止StreamingContext ,可以将stop() 设置可选参数叫做
stopSparkContext,将其设置为 false即可。 - 一个SparkContext 可以创建多个StreamingContext反复使用,前提是在下一个StreamingContext被创建之前,前一个StreamingContext要先被停止。
离散化流(Discretized Streams:DStreams)
Discretized Stream or DStream是spark Streaming提供的基本的抽象概念。它表现为一个持续不断的数据流,输入的数据流既可以接收数据源的数据,也可以处理由转换的输入流生成的数据流。就系统内部而言,DStream 可以被认为是一系列连续的RDD,RDD为一个不可变的、分布式数据集,为spark的抽象概念。在DStream 中的每一个RDD都有一个来自内部特定的数据,如下图所示
应用在DStream上面的任何操作都会转化成在DStream里边RDD的操作。例如上面例子中提到的将一个lines DStream 转换为words DStream 的过程中,flatmap操作就会被应用到每一个lines 下的RDD,进而生成words下的RDD,见下图。

这些里边的RDD的transformation被Spark Engine来进行计算。DStream隐藏了大部分的细节并且提供给开发者一些很高级,方便的api可以使用。这些操作将会在后面部分详细的讨论。
Input DStreams and Receivers
Input DStreams是表示着那些从数据流源接收的输入数据流的DStreams。在上面的例子当中,lines是一个Input DStreams,它表示着从netcat服务器上接收的最初的数据流。每一个Input DStream都可以被Receiver联系起来,Receiver可以从数据源接收数据并且把数据存储到内存当中,等待处理。
Spark Streaming提供了两种策略来建立流式处理的源:
- 基本源(Basic sources): 这一类数据源在StreamingContext API中可以直接使用,例如 file systems, socket connections, and Akka actors.
- 高级源(Advanced sources):这类源比如 Kafka, Flume, Kinesis, Twitter, etc. ,使用必须通过其他的通过类。这个主要通过添加其他的依赖来实现,具体见linking。
注意,如果你想要在你的流式应用中并行地接收多重数据流,你可以创建多个Input DStreams(详细介绍见 Performance Tuning )。这将创建多个Receiver,这些Receiver将同时接收多个数据流。但是需要注意的是,一个Spark worker或是executor是一个long-running的任务,因此,它会长时间占用分配给spark流式处理应用的核数(cores)。因此记住一个应用需要分配多少核数来处理接收的数据,和需要运行多少个Receiver来并行接收数据是十分重要的。
要点
-
当在本地运行一个流式处理应用程序时,不要使用local或者是local[1]来作为master URL。这意味着只会有一个线程在处理运行着的任务时被用到。如果你正在使用一个基于Receiver(e.g. sockets, Kafka, Flume, etc.)的 input DStream接收数据,然后单一的线程将会被使用来运行receiver,从而没有线程来处理已经接收的数据。因此,在本地运行时,local[n]中n的数量一定要大于receiver的数量。
-
在一个集群当中,扩展运行逻辑的时候,被分配给应用的核的数量一定要多于receiver的数量,否则系统将只是接收数据,并不会进行数据处理。