基于gensim模块的中文句子相似度计算工具
概述
中文句子相似度的计算有很多模型,我们使用 TFIDF , LSI 与 LDA 模型
这3中模型更加适用于文章相似度的计算
对于句子来说,长度太短,正确率相对不高
算法及代码
具体这几种模型的原理介绍可以参考别人的博客
http://www.52nlp.cn/%E5%A6%82%E4%BD%95%E8%AE%A1%E7%AE%97%E4%B8%A4%E4%B8%AA%E6%96%87%E6%A1%A3%E7%9A%84%E7%9B%B8%E4%BC%BC%E5%BA%A6%E4%B8%80
gensim包提供了这几个模型,因此我们直接拿来用就好
我将这个模型进行了简单的封装,包括增加了中文分词分句,并提供清晰简洁的API
代码:https://github.com/WenDesi/sentenceSimilarity
实验
实验数据源
从《枪炮、病菌与钢铁》一书中选出了10组,每组25个句子,共250个句子
先将这些句子用有道翻译翻译成英文,再分别用百度翻译与谷歌翻译再翻译成中文
其中将谷歌翻译版本作为训练集,原文与百度翻译版做测试集,分别对三种模型进行测试
衡量指标
分别从正确组数、正确率(其实两者一样,求别吐槽!!)、正确组平均得分、正确组最低得分
错误组数、错误率、错误组平均得分、错误组最高得分几个方面来衡量
实验结果

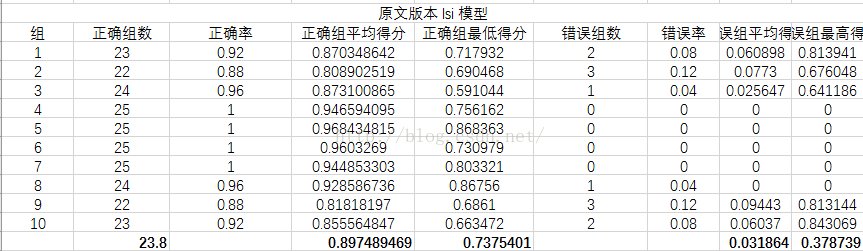


实验结果分析
可以看到LSI模型最好,LDA模型效果最差,分析原因可能是LDA模型原本就是分析文章的,对于句子级别的数据太小,所以效果不好