CUDA系列学习(二)CUDA memory & variables - different memory and variable types
本文来介绍CUDA的memory和变量存放,分为以下章节:
(一)、CPU Memory 结构
(二)、GPU Memory结构
(三)、CUDA Context
(四)、kernel设计
(五)、变量 & Memory
5.1 global arrays
5.2 global variables
5.3 Constant variables
5.4 Register
5.5 Local Array
5.6 Shared Memory
5.7 Texture Memory
5.8 总结
(一)、CPU Memory 结构
CPU提速主要依靠局部性原理,即时间局部性和空间局部性。我们先看一下CPU的内存结构:

Data Access
先复习一下数据在这几级存储中的传输。作为数据transfer的基本单位,cache line的典型大小为8*8(8个变量,每个8bytes)=64bytes. 当一个cache想要load数据到寄存器时,检查cache中的line,如果hit了就get到数据,否则将整条line从主存中去出来,(通常通过LRU)替换cache中一条line。寄存器传数据到cache也一样的过程。
Importance of Locality
上图中可见在CPU中memory<--->L3 Cache传输带宽为20GB/s, 除以64bytes/line得到传输记录速度约300M line/s,约为300M*8= 2.4G double/s. 一般地,浮点数操作需要两个输入+1个输出,那么loading 3个数(3 lines)的代价为 100Mflops。如果一个line中的全部8个variables都被用到,那么每秒浮点操作可以达到800Mflops。而CPU工作站典型为10 Gflops。这就要靠时间局部性来重用数据了。
(二)、GPU Memory结构
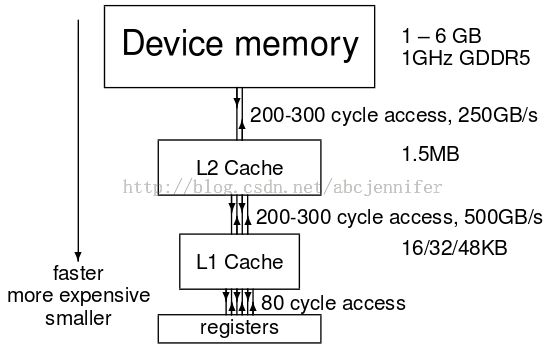
Data Access
- Kepler GPU的cache line通常为128bytes(32个float or 16个double)。
- 数据传输带宽最高250GB/s
- SMX的L2 cache统一1.5MB,L1 cache / shared memory有64KB
- 没有CPU中的全局缓存一致性,所以几乎没有两块block更新相同的全局数组元素。
Importance of Locality
GPU对浮点数的操作速度可达1Tflops。和上面CPU的计算类似,GPU中memory<--->L2Cache传输带宽为250GB/s, 除以128bytes/line得到传输记录速度约2G line/s,约为2G*16= 32G double/s. 一般地,浮点数操作需要两个输入+1个输出,那么loading 3个数(3 lines)的代价为 670Mflops。如果一个line中的全部16个variables都被用到,那么每秒浮点操作可以达到11Gflops。
这样的话每进行一次数据到device的传输需要45flops(45次浮点操作)才能达到500Gflops. 所以很多算法基本上不是卡在计算瓶颈,而是传输带宽。
(三)、CUDA Context
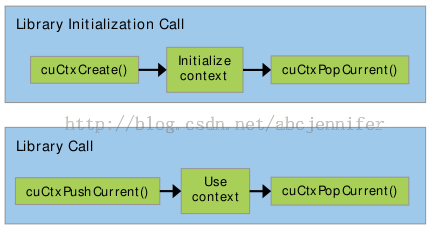
一个CUDA Context类似于一个CPU进程。程序在Initialization的时候,runtime给每个device创建一个CUDA context,这个context在所有host threads中共享。driver API中的所有资源和action都封装在一个CUDA context中,context被销毁的时候系统自动清空这些资源,每个context拥有其自己的地址空间。所以,CUdeviceptr的value在不同context中会指向不同的内存空间。
一个host thread同一时刻只能用一个device context,每个host thread都有一个保存当前contexts的stack。当一个context被cuCtxCreate()创建时,这个新的context被压入栈(在栈顶),调用cuCtxPopCurrent() 可将这个context弹出来,然后这个context就会“漂”到其他host thread中再被压入栈。
每个context都会维护一个count,表示有多少个threads在用。cuDtrCreate()令count = 1, cuCtxAttach()令count++,cuCtxDetach()令count--,cuCtxDestroy()令count = 0;一旦count=0,这个context就被销毁。
(四)、kernel设计
我们在CUDA系列学习(一)中提到了GPU用的是SIMT cores,现在看一下它是如何进行线程管理的。每个SMX 多处理器在创建,管理,调度,执行的时候将threads每32个组成一组,称为“wraps”。具体地,一个多处理器分配到多个blocks去执行的时候,它将blocks中的threads 分成wraps而且每个warp被一个warp scheduler来调度执行。一个warp一次执行一条相同指令,所以warp中所有threads同步执行是最有效的。那么如果warp中的部分threads走上了数据相关的条件分支,warp就连续在各个branch上执行,暂停没进入branch的threads。直到所有branch上的threads都执行完再合并了一起向下走。所以实现性能提升要注意尽量使warp内线程不要出现divergence。另外,注意这个branch divergence 之发生在warp内部;不同warp之间是独立执行的。
看两个kernel设计:
- __global__ void kernel_1(float* x)
- {
- int tid = threadIdx.x + blockDim.x * blockIdx.x;
- x[tid] = threadIdx.x;
- }
- __global__ void kernel_2(float* x)
- {
- int tid = threadIdx.x + blockDim.x * blockIdx.x;
- x[1000*tid] = threadIdx.x;
- }
kernel_1中一个warp的32个thread访问x的相邻元素,即x[0]~x[31]在相同的cache line, 就是一个好的transfer;
kernel_2中访问不连续内存,就要请求不同cache line,严重影响performance
(五)、变量 & Memory
上一篇CUDA系列学习(一)An Introduction to GPU and CUDA中我们提到了memory由host memory和device memory组成,每部分尤其自己独立的内存空间。Kernel跑在device memory上,所以runtime提供了分配,释放,复制 device memory 和device <-->host 间transfer data的函数。
5.1 global arrays
global arrays:
- 保存在/占用device memory
- 由host code(非kernel部分code)声明
- 一直存在,直到被host code释放
- 因为所有block执行顺序不定,所以如果一个block修改了一个数组元素,其他block就不能再对该元素进行读写
5.2 global variables
声明前加标识符__device__,表示变量要放在device上了 e.g. __device__ int reduction_lock=0;
__shared__(见4.6)和__constant__(见4.3)中至多有一个跟在__device__后面同时使用,标明用哪块memory空间,如果这两个都没写,则:
- 变量可以被grid内的所有threads读写
- 与application同生死
- 也可以定义为array,但是必须指定size
- 可以在host code中通过以下函数读写:
1. cudaMemcpyToSymbol;
2. cudaMemcpyFromSymbol;
3. cudaMemcpy + cudaGetSymbolAddress
Demo Code:
- // float scalar
- __device__ float devData;
- float value = 3.14f;
- cudaMemcpyToSymbol(devData, &value, sizeof(float));
- //cudaMemcpyToSymbol(const char* symbol, const void* src, size_t count, size_t offset = 0, enum cudaMemcpyKind)
- // float array
- __device__ float* devPointer;
- float* ptr;
- cudaMalloc(&ptr, 256 * sizeof(float));
- cudaMemcpyToSymbol(devPointer, &ptr, sizeof(ptr));
5.3 Constant variables <常用>
- 哪里声明随便,声明前加标识符__constant__
- 与application同生死
- grid内所有thread可直接读(不可update),在host code中通过以下函数初始化
1. cudaMemcpyToSymbol;
2. cudaMemcpyFromSymbol;
3. cudaMemcpy + cudaGetSymbolAddress
Demo Code:
- __constant__ float constData[256];
- float data[256];
- cudaMemcpyToSymbol(constData, data, sizeof(data));
- //cudaMemcpyToSymbol(const char* symbol, const void* src, size_t count, size_t offset = 0, enum cudaMemcpyKind)
- cudaMemcpyFromSymbol(data, constData, sizeof(data));
- //cudaMemcpyFromSymbol(const char* dst, const void* src_symbol, size_t count, size_t offset = 0, enum cudaMemcpyKind)
5.4 Register
- 默认一个kernel中的所有内部变量都存在register中
- 64K 32-bit registers per SMX
- up to 63 registers per thread (up to 255 for K20 / K40)
这时有64K/63 = 1024个threads (256个threads for K20 / K40)
- up to 2048 threads (at most 1024 per thread block)
这时每个thread有32个register
- not much difference between “fat” and “thin” threads
- 如果程序需要更多的register呢?就“spill over”到L1 cache,这样访问速度就慢了,我们要尽量避免spill
5.5 Local Array
指kernel code中声明的数组。
- 简单情况下,编译器会将小数组float a[3]转换成3个标量registers:a0,a1,a2作处理
- 复杂的情况,会将array放到L1(16KB),只能放4096个32-bit的变量,如果有1024个线程,每个线程只能分配放4个变量。
5.6 Shared Memory
前面加标识符__shared__ e.g. __shared__ int x_dim;
- 要占用thread block的shared memory space.
- 要比global memory快很多,所以只要有机会就把global memory整成shared memory
- 与block同生死
- thread block内所有threads共用(可读可写)
- 啥时侯用呢?当所有threads访问都是同一个值的时候,这样就避免用register了
但是有问题就是,如果一个thread block有多个warp(上一篇blog中提到的概念,block中的thread每32个被分到一个warp,最后一个不足32个thread也没关系,同样形成一个warp),各warp执行指令顺序是不定的,那么久需要线程同步机制,用指令__syncthreads(); 插入一个“barrier”,所有wrap执行到这个barrier之前没有thread/warp能够越过去。
Kepler GPU给L1 Cache + shared memory总共64KB,可以分为16+48,32+32,48+16;这个split可以通过cudaFuncSetCacheConfig()或cudaDeviceSetCacheConfig()设置,默认给shared memroy 48KB。这个具体情况看程序了。
下面通过一个经典例子来看shared memory作用:矩阵乘法
目的:实现C=A*B,方法:c[i,j] = A[i,:] * B[:,j],
其中矩阵用row-major表示,即c[i,j] = *(c.elements + i*c.width + j)
1. 不用shared memory优化版:
设A为m*t的矩阵;B为t*n的矩阵;
每个线程读取A的一行,B的一列,计算C的对应值;
所以这样需要从global memory中读n次A,m次B。
- // Matrices are stored in row-major order:
- // M(row, col) = *(M.elements + row * M.width + col)
- typedef struct {
- int width;
- int height;
- float* elements;
- } Matrix;
- // Thread block size
- #define BLOCK_SIZE 16
- // Forward declaration of the matrix multiplication kernel
- __global__ void MatMulKernel(const Matrix, const Matrix, Matrix);
- // Matrix multiplication - Host code
- // Matrix dimensions are assumed to be multiples of BLOCK_SIZE
- void MatMul(const Matrix A, const Matrix B, Matrix C)
- {
- // Load A and B to device memory
- Matrix d_A;
- d_A.width = A.width; d_A.height = A.height;
- size_t size = A.width * A.height * sizeof(float);
- cudaMalloc(&d_A.elements, size);
- cudaMemcpy(d_A.elements, A.elements, size,
- cudaMemcpyHostToDevice);
- Matrix d_B;
- d_B.width = B.width; d_B.height = B.height;
- size = B.width * B.height * sizeof(float);
- cudaMalloc(&d_B.elements, size);
- cudaMemcpy(d_B.elements, B.elements, size,
- cudaMemcpyHostToDevice);
- // Allocate C in device memory
- Matrix d_C;
- d_C.width = C.width; d_C.height = C.height;
- size = C.width * C.height * sizeof(float);
- cudaMalloc(&d_C.elements, size);
- // Invoke kernel
- dim3 dimBlock(BLOCK_SIZE, BLOCK_SIZE);
- dim3 dimGrid(B.width / dimBlock.x, A.height / dimBlock.y);
- MatMulKernel<<<dimGrid, dimBlock>>>(d_A, d_B, d_C);
- // Read C from device memory
- cudaMemcpy(C.elements, Cd.elements, size,
- cudaMemcpyDeviceToHost);
- }
- // Free device memory
- cudaFree(d_A.elements);
- cudaFree(d_B.elements);
- cudaFree(d_C.elements);
- }
- // Matrix multiplication kernel called by MatMul()
- __global__ void MatMulKernel(Matrix A, Matrix B, Matrix C)
- {
- // Each thread computes one element of C
- // by accumulating results into Cvalue
- float Cvalue = 0;
- int row = blockIdx.y * blockDim.y + threadIdx.y;
- int col = blockIdx.x * blockDim.x + threadIdx.x;
- for (int e = 0; e < A.width; ++e)
- Cvalue += A.elements[row * A.width + e]* B.elements[e * B.width + col];
- C.elements[row * C.width + col] = Cvalue;
- }
2. 利用shared memory
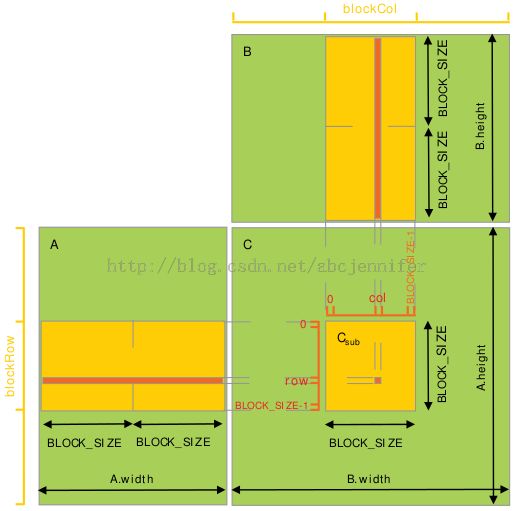
每个thread block负责计算一个子矩阵Csub, 其中每个thread负责计算Csub中的一个元素。如下图所示。为了将fit设备资源,A,B都分割成很多block_size维的方形matrix,Csub将这些方形matrix的乘积求和而得。每次计算一个乘积时,先将两个对应方形矩阵从global memory 载入 shared memory(一个thread负责载入A, B两个sub matrix的元素),然后每个thread计算乘积的一个元素,再由每个thread将这些product加和,存入一个register,最后一次性写入global memory。计算时注意同步,详见代码。
设A为m*t的矩阵;B为t*n的矩阵;
这样呢,A只从global memory读了n/block_size次,B只读了m/block_size次;
Kernel Code:
- __global__ void MatMulKernel(Matrix A, Matrix B, Matrix C)
- {
- // Block row and column
- int blockRow = blockIdx.y;
- int blockCol = blockIdx.x;
- // Each thread block computes one sub-matrix Csub of C
- Matrix Csub = GetSubMatrix(C, blockRow, blockCol);
- // Each thread computes one element of Csub by accumulating results into Cvalue
- float Cvalue = 0;
- // Thread row and column within Csub
- int row = threadIdx.y;
- int col = threadIdx.x;
- // Loop over all the sub-matrices of A and B that are
- // required to compute Csub
- // Multiply each pair of sub-matrices together
- // and accumulate the results
- for (int m = 0; m < (A.width / BLOCK_SIZE); ++m) {
- // Get sub-matrix Asub of A
- Matrix Asub = GetSubMatrix(A, blockRow, m);
- // Get sub-matrix Bsub of B
- Matrix Bsub = GetSubMatrix(B, m, blockCol);
- // Shared memory used to store Asub and Bsub respectively
- __shared__ float As[BLOCK_SIZE][BLOCK_SIZE];
- __shared__ float Bs[BLOCK_SIZE][BLOCK_SIZE];
- // Load Asub and Bsub from device memory to shared memory
- // Each thread loads one element of each sub-matrix
- As[row][col] = GetElement(Asub, row, col);
- Bs[row][col] = GetElement(Bsub, row, col);
- // Synchronize to make sure the sub-matrices are loaded
- // before starting the computation
- __syncthreads();
- // Multiply Asub and Bsub together
- for (int e = 0; e < BLOCK_SIZE; ++e)
- Cvalue += As[row][e] * Bs[e][col];
- // Synchronize to make sure that the preceding
- // computation is done before loading two new
- // sub-matrices of A and B in the next iteration
- __syncthreads();
- }
- // Write Csub to device memory
- // Each thread writes one element
- SetElement(Csub, row, col, Cvalue);
- }
Host Code:
- // Invoke kernel
- dim3 dimBlock(BLOCK_SIZE, BLOCK_SIZE);
- dim3 dimGrid(B.width / dimBlock.x, A.height / dimBlock.y);
- MatMulKernel<<<dimGrid, dimBlock>>>(d_A, d_B, d_C);
5.7 Texture memory
前面加标识符const __restrict__, 之所以叫texture是因为之前用texture memory想服务于纯graphics的应用。
不同于shared memory,对texture memory, 不同线程可以访问到不同value。K20/K40中texture cache有48KB。
5.8 总结
综上,每个block内有以下资源:
- threads
- registers (registers per thread * number of threads)
- shared memory
这些决定了一个SMX上能同时运行多少个blocks(最多16个)。
参考:
1. CUDA C Programming Guide
2. different memory and variable types
3. CUDA 安装与配置
4. CUDA调试工具——CUDA GDB
5. GPU工作方式
6. Fermi 架构白皮书(GPU继承了Fermi的很多架构特点)
7. GTX460架构
from: http://blog.csdn.net/abcjennifer/article/details/42528569