deep learning tutorial(三)Stacked Denoising Autoencoders (SdA)
Stacked Autoencoders
1.前向传导
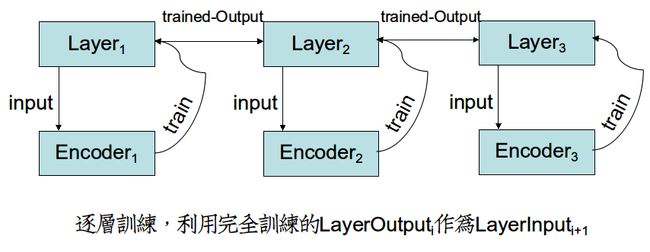
Denoising autoencoders可以利用栈式结构来形成一个深层网络。这种结构每次只训练一个层,每个层都作为一个单独的Denoising autoencoder来极小化它的重构误差。
2.微调(fine-tuning)
当所有层都预训练完之后,我们通过极小化预测预测误差(prediction error)来进行有监督学习。具体是在最后一层的后面加上一个逻辑回归层(logistic regression layer),然后再训练整个网络。
这一步类似于感知学习算法,因为我们现在得到了
正确数据(target class),r然后计算得到输出值,将输出值和正确的值相比,由此来调整每一个输出端上的权值。
以下是UFLDL的解释:
首先,你需要用原始输入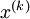 训练第一个自编码器,它能够学习得到原始输入的一阶特征表示
训练第一个自编码器,它能够学习得到原始输入的一阶特征表示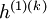 。 接着,你需要把原始数据输入到上述训练好的稀疏自编码器中,对于每一个输入,都可以得到它对应的一阶特征表示。然后你再用这些一阶特征作为另一个稀疏自编码器的输入,使用它们来学习二阶特征。
。 接着,你需要把原始数据输入到上述训练好的稀疏自编码器中,对于每一个输入,都可以得到它对应的一阶特征表示。然后你再用这些一阶特征作为另一个稀疏自编码器的输入,使用它们来学习二阶特征。
代码解读
class SdA
初始化
for i in range(self.n_layers):
# 对每一层
# 如果是第一层,输入就是原始数据
# 否则就是上一层的输出
if i == 0:
input_size = n_ins
else:
input_size = hidden_layers_sizes[i - 1]
if i == 0:
layer_input = self.x
else:
layer_input = self.sigmoid_layers[-1].output
#Hidden layer进行来两部计算1.y=x*W+b;2.sigmoiid(y)
sigmoid_layer = HiddenLayer(rng=numpy_rng,
input=layer_input,
n_in=input_size,
n_out=hidden_layers_sizes[i],
activation=T.nnet.sigmoid)
#将这一层加在后面
self.sigmoid_layers.append(sigmoid_layer)
# 这里,dA层和前面的sigmoid层共用一个W和b
self.params.extend(sigmoid_layer.params)
# dA layer,注意dA 用的是 sigmoid layer层的参数W,b
dA_layer = dA(numpy_rng=numpy_rng,
theano_rng=theano_rng,
input=layer_input,
n_visible=input_size,
n_hidden=hidden_layers_sizes[i],
W=sigmoid_layer.W,
bhid=sigmoid_layer.b)
self.dA_layers.append(dA_layer)
在最后一层加入softmax层
# softmax
self.logLayer = LogisticRegression(
input=self.sigmoid_layers[-1].output,
n_in=hidden_layers_sizes[-1],
n_out=n_outs
)
self.params.extend(self.logLayer.params)
# 计算cost
self.finetune_cost = self.logLayer.negative_log_likelihood(self.y)
#计算错误率
self.errors = self.logLayer.errors(self.y)
2.预训练,加入某种噪声,对原始数据进行重构
for dA in self.dA_layers:
# get the cost and the updates list
cost, updates = dA.get_cost_updates(corruption_level,
learning_rate)
# compile the theano function
fn = theano.function(
inputs=[
index,
theano.In(corruption_level, value=0.2),
theano.In(learning_rate, value=0.1)
],
outputs=cost,
updates=updates,
givens={
self.x: train_set_x[batch_begin: batch_end]
}
)
# append `fn` to the list of functions
pretrain_fns.append(fn)
3.最后,进行微调,把重构后的数据输入sigmoid层,当成一个多层感知器进行训练,利用原始数据的标签来训练出softmax分类器的网络参数。
index = T.lscalar('index') # index to a [mini]batch
# compute the gradients with respect to the model parameters
gparams = T.grad(self.finetune_cost, self.params)
# compute list of fine-tuning updates
updates = [
(param, param - gparam * learning_rate)
for param, gparam in zip(self.params, gparams)
]
train_fn = theano.function(
inputs=[index],
outputs=self.finetune_cost,
updates=updates,
givens={
self.x: train_set_x[
index * batch_size: (index + 1) * batch_size
],
self.y: train_set_y[
index * batch_size: (index + 1) * batch_size
]
},
name='train'
)
就是一般的梯度下降,只不过W的初值是由第一步encoder获得的
extend()函数用于在列表末尾一次性追加另一个序列中的多个值(用新列表扩展原来的列表),只接受列表作为参数。
append()方法用于在列表末尾添加新的对象,只接受一个obj作为参数。