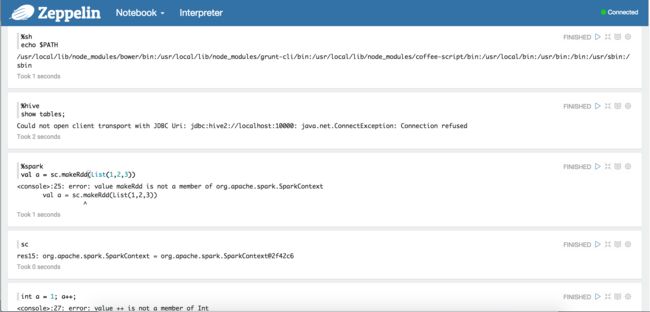
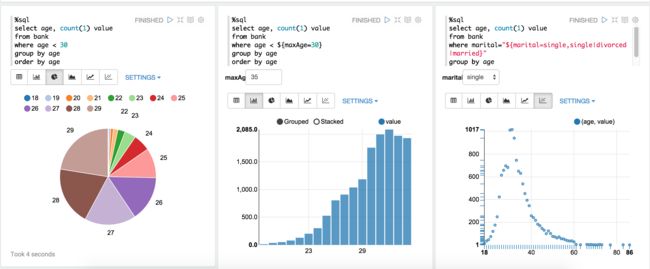
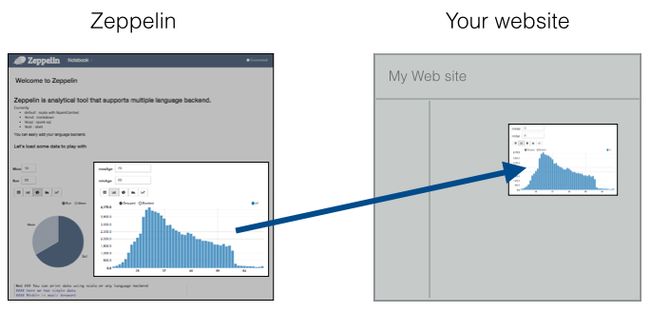
- nosql数据库技术与应用知识点
皆过客,揽星河
NoSQLnosql数据库大数据数据分析数据结构非关系型数据库
Nosql知识回顾大数据处理流程数据采集(flume、爬虫、传感器)数据存储(本门课程NoSQL所处的阶段)Hdfs、MongoDB、HBase等数据清洗(入仓)Hive等数据处理、分析(Spark、Flink等)数据可视化数据挖掘、机器学习应用(Python、SparkMLlib等)大数据时代存储的挑战(三高)高并发(同一时间很多人访问)高扩展(要求随时根据需求扩展存储)高效率(要求读写速度快)
- 分享一个基于python的电子书数据采集与可视化分析 hadoop电子书数据分析与推荐系统 spark大数据毕设项目(源码、调试、LW、开题、PPT)
计算机源码社
Python项目大数据大数据pythonhadoop计算机毕业设计选题计算机毕业设计源码数据分析spark毕设
作者:计算机源码社个人简介:本人八年开发经验,擅长Java、Python、PHP、.NET、Node.js、Android、微信小程序、爬虫、大数据、机器学习等,大家有这一块的问题可以一起交流!学习资料、程序开发、技术解答、文档报告如需要源码,可以扫取文章下方二维码联系咨询Java项目微信小程序项目Android项目Python项目PHP项目ASP.NET项目Node.js项目选题推荐项目实战|p
- Spark 组件 GraphX、Streaming
叶域
大数据sparkspark大数据分布式
Spark组件GraphX、Streaming一、SparkGraphX1.1GraphX的主要概念1.2GraphX的核心操作1.3示例代码1.4GraphX的应用场景二、SparkStreaming2.1SparkStreaming的主要概念2.2示例代码2.3SparkStreaming的集成2.4SparkStreaming的应用场景SparkGraphX用于处理图和图并行计算。Graph
- 大数据毕业设计hadoop+spark+hive知识图谱租房数据分析可视化大屏 租房推荐系统 58同城租房爬虫 房源推荐系统 房价预测系统 计算机毕业设计 机器学习 深度学习 人工智能
2401_84572577
程序员大数据hadoop人工智能
做了那么多年开发,自学了很多门编程语言,我很明白学习资源对于学一门新语言的重要性,这些年也收藏了不少的Python干货,对我来说这些东西确实已经用不到了,但对于准备自学Python的人来说,或许它就是一个宝藏,可以给你省去很多的时间和精力。别在网上瞎学了,我最近也做了一些资源的更新,只要你是我的粉丝,这期福利你都可拿走。我先来介绍一下这些东西怎么用,文末抱走。(1)Python所有方向的学习路线(
- Spark集群的三种模式
MelodyYN
#Sparksparkhadoopbigdata
文章目录1、Spark的由来1.1Hadoop的发展1.2MapReduce与Spark对比2、Spark内置模块3、Spark运行模式3.1Standalone模式部署配置历史服务器配置高可用运行模式3.2Yarn模式安装部署配置历史服务器运行模式4、WordCount案例1、Spark的由来定义:Hadoop主要解决,海量数据的存储和海量数据的分析计算。Spark是一种基于内存的快速、通用、可
- Java中的大数据处理框架对比分析
省赚客app开发者
java开发语言
Java中的大数据处理框架对比分析大家好,我是微赚淘客系统3.0的小编,是个冬天不穿秋裤,天冷也要风度的程序猿!今天,我们将深入探讨Java中常用的大数据处理框架,并对它们进行对比分析。大数据处理框架是现代数据驱动应用的核心,它们帮助企业处理和分析海量数据,以提取有价值的信息。本文将重点介绍ApacheHadoop、ApacheSpark、ApacheFlink和ApacheStorm这四种流行的
- 写出渗透测试信息收集详细流程
卿酌南烛_b805
一、扫描域名漏洞:域名漏洞扫描工具有AWVS、APPSCAN、Netspark、WebInspect、Nmap、Nessus、天镜、明鉴、WVSS、RSAS等。二、子域名探测:1、dns域传送漏洞2、搜索引擎查找(通过Google、bing、搜索c段)3、通过ssl证书查询网站:https://myssl.com/ssl.html和https://www.chinassl.net/ssltools
- Spark MLlib模型训练—推荐算法 ALS(Alternative Least Squares)
不二人生
SparkML实战spark-ml推荐算法算法
SparkMLlib模型训练—推荐算法ALS(AlternativeLeastSquares)如果你平时爱刷抖音,或者热衷看电影,不知道有没有过这样的体验:这类影视App你用得越久,它就好像会读心术一样,总能给你推荐对胃口的内容。其实这种迎合用户喜好的推荐,离不开机器学习中的推荐算法。在今天这一讲,我们就结合两个有趣的电影推荐场景,为你讲解SparkMLlib支持的协同过滤与频繁项集算法电影推荐场
- Python基础知识进阶之正则表达式_头歌python正则表达式进阶
前端陈萨龙
程序员python学习面试
最后硬核资料:关注即可领取PPT模板、简历模板、行业经典书籍PDF。技术互助:技术群大佬指点迷津,你的问题可能不是问题,求资源在群里喊一声。面试题库:由技术群里的小伙伴们共同投稿,热乎的大厂面试真题,持续更新中。知识体系:含编程语言、算法、大数据生态圈组件(Mysql、Hive、Spark、Flink)、数据仓库、Python、前端等等。网上学习资料一大堆,但如果学到的知识不成体系,遇到问题时只是
- 分布式离线计算—Spark—基础介绍
测试开发abbey
人工智能—大数据
原文作者:饥渴的小苹果原文地址:【Spark】Spark基础教程目录Spark特点Spark相对于Hadoop的优势Spark生态系统Spark基本概念Spark结构设计Spark各种概念之间的关系Executor的优点Spark运行基本流程Spark运行架构的特点Spark的部署模式Spark三种部署方式Hadoop和Spark的统一部署摘要:Spark是基于内存计算的大数据并行计算框架Spar
- spark常用命令
我是浣熊的微笑
spark
查看报错日志:yarnlogsapplicationIDspark2-submit--masteryarn--classcom.hik.ReadHdfstest-1.0-SNAPSHOT.jar进入$SPARK_HOME目录,输入bin/spark-submit--help可以得到该命令的使用帮助。hadoop@wyy:/app/hadoop/spark100$bin/spark-submit--
- spark启动命令
学不会又听不懂
spark大数据分布式
hadoop启动:cd/root/toolssstart-dfs.sh,只需在hadoop01上启动stop-dfs.sh日志查看:cat/root/toolss/hadoop/logs/hadoop-root-datanode-hadoop03.outzookeeper启动:cd/root/toolss/zookeeperbin/zkServer.shstart,三台都要启动bin/zkServ
- 大数据领域的深度分析——AI是在帮助开发者还是取代他们?
阳爱铭
大数据与数据中台技术沉淀大数据人工智能后端数据库架构数据库开发etl工程师chatgpt
在大数据领域,生成式人工智能(AIGC)的应用正在迅速扩展,改变了数据科学家和开发者的工作方式。本文将从大数据的专业视角,探讨AI工具在这一领域的作用,以及它们是如何帮助开发者而非取代他们的。1.大数据领域的AI工具现状在大数据领域,AI工具已经取得了显著进展,以下是几款主要的AI工具及其功能和实际应用:ApacheSpark+MLlib:ApacheSpark是一个开源的分布式计算系统,广泛用于
- 大数据新视界 --大数据大厂之 Spark 性能优化秘籍:从配置到代码实践
青云交
大数据新视界Spark性能优化内存分配并行度存储级别shuffle减少算法优化代码实践数据读取广播变量数据倾斜Spark数据库
亲爱的朋友们,热烈欢迎你们来到青云交的博客!能与你们在此邂逅,我满心欢喜,深感无比荣幸。在这个瞬息万变的时代,我们每个人都在苦苦追寻一处能让心灵安然栖息的港湾。而我的博客,正是这样一个温暖美好的所在。在这里,你们不仅能够收获既富有趣味又极为实用的内容知识,还可以毫无拘束地畅所欲言,尽情分享自己独特的见解。我真诚地期待着你们的到来,愿我们能在这片小小的天地里共同成长,共同进步。本博客的精华专栏:Ja
- 编程常用命令总结
Yellow0523
LinuxBigData大数据
编程命令大全1.软件环境变量的配置JavaScalaSparkHadoopHive2.大数据软件常用命令Spark基本命令Spark-SQL命令Hive命令HDFS命令YARN命令Zookeeper命令kafka命令Hibench命令MySQL命令3.Linux常用命令Git命令conda命令pip命令查看Linux系统的详细信息查看Linux系统架构(X86还是ARM,两种方法都可)端口号命令L
- 【面试系列】Spark 高频面试题解答
野老杂谈
全网最全IT公司面试宝典面试spark职场和发展大数据
欢迎来到我的博客,很高兴能够在这里和您见面!欢迎订阅相关专栏:⭐️全网最全IT互联网公司面试宝典:收集整理全网各大IT互联网公司技术、项目、HR面试真题.⭐️AIGC时代的创新与未来:详细讲解AIGC的概念、核心技术、应用领域等内容。⭐️大数据平台建设指南:全面讲解从数据采集到数据可视化的整个过程,掌握构建现代化数据平台的核心技术和方法。⭐️《遇见Python:初识、了解与热恋》:涵盖了Pytho
- spark常见面试题
爱敲代码的小黑
spark大数据分布式
文章目录1.Spark的运行流程?2.Spark中的RDD机制理解吗?3.RDD的宽窄依赖4.DAG中为什么要划分Stage?5.Spark程序执行,有时候默认为什么会产生很多task,怎么修改默认task执行个数?6.RDD中reduceBykey与groupByKey哪个性能好,为什么?7.SparkMasterHA主从切换过程不会影响到集群已有作业的运行,为什么?8.SparkMaster使
- Spark面试题
golove666
面试题大全spark大数据分布式面试
Spark面试题1.Spark基础概念1.1解释Spark是什么以及它的主要特点Spark是什么?Spark的主要特点1.2描述Spark运行时架构和组件主要的Spark架构组件:1.3讲述Spark中的弹性分布式数据集(RDD)和数据帧(DataFrame)弹性分布式数据集(RDD)主要特征:创建和转换:使用场景:数据帧(DataFrame)主要特征:创建和操作:使用场景:RDD与DataFra
- 图计算:基于SparkGrpahX计算聚类系数
妙龄少女郭德纲
Spark图算法Scala聚类数据挖掘机器学习
图计算:基于SparkGrpahX计算聚类系数文章目录图计算:基于SparkGrpahX计算聚类系数一、什么是聚类系数二、基于SparkGraphX的聚类系数代码实现总结一、什么是聚类系数聚类系数(ClusteringCoefficient)是图计算和网络分析中的一个重要概念,用于衡量网络中节点的局部聚集程度。它有助于理解网络中节点之间的紧密程度和网络的结构特性。这是一种用来衡量图中节点聚类程度的
- 2024年最全使用Python求解方程_python解方程(1),字节面试官迟到
2401_84569545
程序员python学习面试
最后硬核资料:关注即可领取PPT模板、简历模板、行业经典书籍PDF。技术互助:技术群大佬指点迷津,你的问题可能不是问题,求资源在群里喊一声。面试题库:由技术群里的小伙伴们共同投稿,热乎的大厂面试真题,持续更新中。知识体系:含编程语言、算法、大数据生态圈组件(Mysql、Hive、Spark、Flink)、数据仓库、Python、前端等等。网上学习资料一大堆,但如果学到的知识不成体系,遇到问题时只是
- Spark运行时架构
tooolik
spark架构大数据
目录一,Spark运行时架构二,YARN集群架构(一)YARN集群主要组件1、ResourceManager-资源管理器2、NodeManager-节点管理器3、Task-任务4、Container-容器5、ApplicationMaster-应用程序管理器6,总结(二)YARN集群中应用程序的执行流程三、SparkStandalone架构(一)client提交方式(二)cluster提交方式四、
- 使用SparkSql进行表的分析与统计
xingyuan8
大数据java
背景我们的数据挖掘平台对数据统计有比较迫切的需求,而Spark本身对数据统计已经做了一些工作,希望梳理一下Spark已经支持的数据统计功能,后期再进行扩展。准备数据在参考文献6中下载鸢尾花数据,此处格式为iris.data格式,先将data后缀改为csv后缀(不影响使用,只是为了保证后续操作不需要修改)。数据格式如下:SepalLengthSepalWidthPetalLengthPetalWid
- 13.Spark Core-Spark中广播变量和累加器
__元昊__
一、前述Spark中因为算子中的真正逻辑是发送到Executor中去运行的,所以当Executor中需要引用外部变量时,需要使用广播变量。累机器相当于统筹大变量,常用于计数,统计。二、具体原理1、广播变量广播变量理解图image注意事项1、能不能将一个RDD使用广播变量广播出去?不能,因为RDD是不存储数据的。可以将RDD的结果广播出去。2、广播变量只能在Driver端定义,不能在Executor
- 比较Spark与Flink
傲雪凌霜,松柏长青
大数据后端sparkflink大数据
ApacheSpark和ApacheFlink都是目前非常流行的大数据处理引擎,但它们在架构、处理模式、应用场景等方面有一些显著的区别。下面是二者的对比:1.处理模式Spark:主要支持批处理(BatchProcessing),也能通过SparkStreaming处理流式数据,但SparkStreaming本质上是通过微批(micro-batching)的方式处理流数据,延迟相对较高。SparkS
- Spark底层逻辑
傲雪凌霜,松柏长青
大数据后端spark大数据
ApacheSpark的底层逻辑可以从其核心概念、组件和执行流程等方面来理解。Spark提供了一个分布式数据处理框架,其底层逻辑基于批处理架构,能够在大规模集群中高效地处理数据。以下是Spark的底层逻辑的详细介绍:1.核心概念Spark的底层基于几个核心概念来实现分布式计算,包括:RDD(ResilientDistributedDataset,弹性分布式数据集):RDD是Spark最基础的数据抽
- Spark - 升级版数据源JDBC2
大猪大猪
在spark的数据源中,只支持Append,Overwrite,ErrorIfExists,Ignore,这几种模式,但是我们在线上的业务几乎全是需要upsert功能的,就是已存在的数据肯定不能覆盖,在mysql中实现就是采用:ONDUPLICATEKEYUPDATE,有没有这样一种实现?官方:不好意思,不提供,dounine:我这有呀,你来用吧。哈哈,为了方便大家的使用我已经把项目打包到mave
- PySpark
静听山水
Sparkspark
PySpark的本质确实是Python的一个接口层,它允许你使用Python语言来编写ApacheSpark应用程序。通过这个接口,你可以利用Spark强大的分布式计算能力,同时享受Python的易用性和灵活性。1、PySpark的工作原理PySpark的工作原理可以概括为以下几个步骤:编写Python代码:开发者使用Python语法来编写Spark应用程序。这些程序通常涉及创建RDDs(弹性分布
- Ubuntu的ssh
请不要问我是谁
安装sshsudoapt-getupdatesudoapt-getinstallopenssh-server检测ssh是否启动sudops-e|grepssh创建root用户sudopasswdroot配置本机无密码ssh登录cd/home/spark0ssh-keygen-trsa-P""cat.ssh/id_rsa.pub>>.ssh/authorized_keyschmod600.ssh/a
- 2024年大数据最新实时数仓之实时数仓架构(Hudi)
2401_84185556
程序员大数据架构
技术框架Kafka:用于接入数据源;FlinkCDC:如果直接接入业务数据源可以考虑CDC方式,如果通过Kafka缓冲接入业务数据可以忽略;Flink:用于数据ETL,包括接入数据、处理数据及输出数据全链路数据计算任务;Spark:用于数据ETL,包括处理数据及输出数据全链路数据计算任务;Hudi:湖仓一体数据管理框架,用来管理模型数据,包括ODS/DWD/DWS/DIM/ADS等;Doris:O
- 实时数仓之实时数仓架构(Hudi)(1),2024年最新熬夜整理华为最新大数据开发笔试题
2401_84181221
程序员架构大数据
+Hudi:湖仓一体数据管理框架,用来管理模型数据,包括ODS/DWD/DWS/DIM/ADS等;+Doris:OLAP引擎,同步数仓结果模型,对外提供数据服务支持;+Hbase:用来存储维表信息,维表数据来源一部分有Flink加工实时写入,另一部分是从Spark任务生产,其主要作用用来支持FlinkETL处理过程中的LookupJoin功能。这里选用Hbase原因主要因为Table的HbaseC
- java线程的无限循环和退出
3213213333332132
java
最近想写一个游戏,然后碰到有关线程的问题,网上查了好多资料都没满足。
突然想起了前段时间看的有关线程的视频,于是信手拈来写了一个线程的代码片段。
希望帮助刚学java线程的童鞋
package thread;
import java.text.SimpleDateFormat;
import java.util.Calendar;
import java.util.Date
- tomcat 容器
BlueSkator
tomcatWebservlet
Tomcat的组成部分 1、server
A Server element represents the entire Catalina servlet container. (Singleton) 2、service
service包括多个connector以及一个engine,其职责为处理由connector获得的客户请求。
3、connector
一个connector
- php递归,静态变量,匿名函数使用
dcj3sjt126com
PHP递归函数匿名函数静态变量引用传参
<!doctype html>
<html lang="en">
<head>
<meta charset="utf-8">
<title>Current To-Do List</title>
</head>
<body>
- 属性颜色字体变化
周华华
JavaScript
function changSize(className){
var diva=byId("fot")
diva.className=className;
}
</script>
<style type="text/css">
.max{
background: #900;
color:#039;
- 将properties内容放置到map中
g21121
properties
代码比较简单:
private static Map<Object, Object> map;
private static Properties p;
static {
//读取properties文件
InputStream is = XXX.class.getClassLoader().getResourceAsStream("xxx.properti
- [简单]拼接字符串
53873039oycg
字符串
工作中遇到需要从Map里面取值拼接字符串的情况,自己写了个,不是很好,欢迎提出更优雅的写法,代码如下:
import java.util.HashMap;
import java.uti
- Struts2学习
云端月影
最近开始关注struts2的新特性,从这个版本开始,Struts开始使用convention-plugin代替codebehind-plugin来实现struts的零配置。
配置文件精简了,的确是简便了开发过程,但是,我们熟悉的配置突然disappear了,真是一下很不适应。跟着潮流走吧,看看该怎样来搞定convention-plugin。
使用Convention插件,你需要将其JAR文件放
- Java新手入门的30个基本概念二
aijuans
java新手java 入门
基本概念: 1.OOP中唯一关系的是对象的接口是什么,就像计算机的销售商她不管电源内部结构是怎样的,他只关系能否给你提供电就行了,也就是只要知道can or not而不是how and why.所有的程序是由一定的属性和行为对象组成的,不同的对象的访问通过函数调用来完成,对象间所有的交流都是通过方法调用,通过对封装对象数据,很大限度上提高复用率。 2.OOP中最重要的思想是类,类是模板是蓝图,
- jedis 简单使用
antlove
javarediscachecommandjedis
jedis.RedisOperationCollection.java
package jedis;
import org.apache.log4j.Logger;
import redis.clients.jedis.Jedis;
import java.util.List;
import java.util.Map;
import java.util.Set;
pub
- PL/SQL的函数和包体的基础
百合不是茶
PL/SQL编程函数包体显示包的具体数据包
由于明天举要上课,所以刚刚将代码敲了一遍PL/SQL的函数和包体的实现(单例模式过几天好好的总结下再发出来);以便明天能更好的学习PL/SQL的循环,今天太累了,所以早点睡觉,明天继续PL/SQL总有一天我会将你永远的记载在心里,,,
函数;
函数:PL/SQL中的函数相当于java中的方法;函数有返回值
定义函数的
--输入姓名找到该姓名的年薪
create or re
- Mockito(二)--实例篇
bijian1013
持续集成mockito单元测试
学习了基本知识后,就可以实战了,Mockito的实际使用还是比较麻烦的。因为在实际使用中,最常遇到的就是需要模拟第三方类库的行为。
比如现在有一个类FTPFileTransfer,实现了向FTP传输文件的功能。这个类中使用了a
- 精通Oracle10编程SQL(7)编写控制结构
bijian1013
oracle数据库plsql
/*
*编写控制结构
*/
--条件分支语句
--简单条件判断
DECLARE
v_sal NUMBER(6,2);
BEGIN
select sal into v_sal from emp
where lower(ename)=lower('&name');
if v_sal<2000 then
update emp set
- 【Log4j二】Log4j属性文件配置详解
bit1129
log4j
如下是一个log4j.properties的配置
log4j.rootCategory=INFO, stdout , R
log4j.appender.stdout=org.apache.log4j.ConsoleAppender
log4j.appender.stdout.layout=org.apache.log4j.PatternLayout
log4j.appe
- java集合排序笔记
白糖_
java
public class CollectionDemo implements Serializable,Comparable<CollectionDemo>{
private static final long serialVersionUID = -2958090810811192128L;
private int id;
private String nam
- java导致linux负载过高的定位方法
ronin47
定位java进程ID
可以使用top或ps -ef |grep java
![图片描述][1]
根据进程ID找到最消耗资源的java pid
比如第一步找到的进程ID为5431
执行
top -p 5431 -H
![图片描述][2]
打印java栈信息
$ jstack -l 5431 > 5431.log
在栈信息中定位具体问题
将消耗资源的Java PID转
- 给定能随机生成整数1到5的函数,写出能随机生成整数1到7的函数
bylijinnan
函数
import java.util.ArrayList;
import java.util.List;
import java.util.Random;
public class RandNFromRand5 {
/**
题目:给定能随机生成整数1到5的函数,写出能随机生成整数1到7的函数。
解法1:
f(k) = (x0-1)*5^0+(x1-
- PL/SQL Developer保存布局
Kai_Ge
近日由于项目需要,数据库从DB2迁移到ORCAL,因此数据库连接客户端选择了PL/SQL Developer。由于软件运用不熟悉,造成了很多麻烦,最主要的就是进入后,左边列表有很多选项,自己删除了一些选项卡,布局很满意了,下次进入后又恢复了以前的布局,很是苦恼。在众多PL/SQL Developer使用技巧中找到如下这段:
&n
- [未来战士计划]超能查派[剧透,慎入]
comsci
计划
非常好看,超能查派,这部电影......为我们这些热爱人工智能的工程技术人员提供一些参考意见和思想........
虽然电影里面的人物形象不是非常的可爱....但是非常的贴近现实生活....
&nbs
- Google Map API V2
dai_lm
google map
以后如果要开发包含google map的程序就更麻烦咯
http://www.cnblogs.com/mengdd/archive/2013/01/01/2841390.html
找到篇不错的文章,大家可以参考一下
http://blog.sina.com.cn/s/blog_c2839d410101jahv.html
1. 创建Android工程
由于v2的key需要G
- java数据计算层的几种解决方法2
datamachine
javasql集算器
2、SQL
SQL/SP/JDBC在这里属于一类,这是老牌的数据计算层,性能和灵活性是它的优势。但随着新情况的不断出现,单纯用SQL已经难以满足需求,比如: JAVA开发规模的扩大,数据量的剧增,复杂计算问题的涌现。虽然SQL得高分的指标不多,但都是权重最高的。
成熟度:5星。最成熟的。
- Linux下Telnet的安装与运行
dcj3sjt126com
linuxtelnet
Linux下Telnet的安装与运行 linux默认是使用SSH服务的 而不安装telnet服务 如果要使用telnet 就必须先安装相应的软件包 即使安装了软件包 默认的设置telnet 服务也是不运行的 需要手工进行设置 如果是redhat9,则在第三张光盘中找到 telnet-server-0.17-25.i386.rpm
- PHP中钩子函数的实现与认识
dcj3sjt126com
PHP
假如有这么一段程序:
function fun(){
fun1();
fun2();
}
首先程序执行完fun1()之后执行fun2()然后fun()结束。
但是,假如我们想对函数做一些变化。比如说,fun是一个解析函数,我们希望后期可以提供丰富的解析函数,而究竟用哪个函数解析,我们希望在配置文件中配置。这个时候就可以发挥钩子的力量了。
我们可以在fu
- EOS中的WorkSpace密码修改
蕃薯耀
修改WorkSpace密码
EOS中BPS的WorkSpace密码修改
>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>
蕃薯耀 201
- SpringMVC4零配置--SpringSecurity相关配置【SpringSecurityConfig】
hanqunfeng
SpringSecurity
SpringSecurity的配置相对来说有些复杂,如果是完整的bean配置,则需要配置大量的bean,所以xml配置时使用了命名空间来简化配置,同样,spring为我们提供了一个抽象类WebSecurityConfigurerAdapter和一个注解@EnableWebMvcSecurity,达到同样减少bean配置的目的,如下:
applicationContex
- ie 9 kendo ui中ajax跨域的问题
jackyrong
AJAX跨域
这两天遇到个问题,kendo ui的datagrid,根据json去读取数据,然后前端通过kendo ui的datagrid去渲染,但很奇怪的是,在ie 10,ie 11,chrome,firefox等浏览器中,同样的程序,
浏览起来是没问题的,但把应用放到公网上的一台服务器,
却发现如下情况:
1) ie 9下,不能出现任何数据,但用IE 9浏览器浏览本机的应用,却没任何问题
- 不要让别人笑你不能成为程序员
lampcy
编程程序员
在经历六个月的编程集训之后,我刚刚完成了我的第一次一对一的编码评估。但是事情并没有如我所想的那般顺利。
说实话,我感觉我的脑细胞像被轰炸过一样。
手慢慢地离开键盘,心里很压抑。不禁默默祈祷:一切都会进展顺利的,对吧?至少有些地方我的回答应该是没有遗漏的,是不是?
难道我选择编程真的是一个巨大的错误吗——我真的永远也成不了程序员吗?
我需要一点点安慰。在自我怀疑,不安全感和脆弱等等像龙卷风一
- 马皇后的贤德
nannan408
马皇后不怕朱元璋的坏脾气,并敢理直气壮地吹耳边风。众所周知,朱元璋不喜欢女人干政,他认为“后妃虽母仪天下,然不可使干政事”,因为“宠之太过,则骄恣犯分,上下失序”,因此还特地命人纂述《女诫》,以示警诫。但马皇后是个例外。
有一次,马皇后问朱元璋道:“如今天下老百姓安居乐业了吗?”朱元璋不高兴地回答:“这不是你应该问的。”马皇后振振有词地回敬道:“陛下是天下之父,
- 选择某个属性值最大的那条记录(不仅仅包含指定属性,而是想要什么属性都可以)
Rainbow702
sqlgroup by最大值max最大的那条记录
好久好久不写SQL了,技能退化严重啊!!!
直入主题:
比如我有一张表,file_info,
它有两个属性(但实际不只,我这里只是作说明用):
file_code, file_version
同一个code可能对应多个version
现在,我想针对每一个code,取得它相关的记录中,version 值 最大的那条记录,
SQL如下:
select
*
- VBScript脚本语言
tntxia
VBScript
VBScript 是基于VB的脚本语言。主要用于Asp和Excel的编程。
VB家族语言简介
Visual Basic 6.0
源于BASIC语言。
由微软公司开发的包含协助开发环境的事
- java中枚举类型的使用
xiao1zhao2
javaenum枚举1.5新特性
枚举类型是j2se在1.5引入的新的类型,通过关键字enum来定义,常用来存储一些常量.
1.定义一个简单的枚举类型
public enum Sex {
MAN,
WOMAN
}
枚举类型本质是类,编译此段代码会生成.class文件.通过Sex.MAN来访问Sex中的成员,其返回值是Sex类型.
2.常用方法
静态的values()方