Hadoop 2.2.0和HBase 0.98.11伪分布式
拖了那么久,现在不得不开始了。sadly。
前期准备
Hadoop系列软件
| 软件 | 功用 |
|---|---|
| HBase | 数据库 |
| Hive | 数据仓库 |
| Mahout | 机器学习算法、数据挖掘 |
| Pig | 数据分析 |
| Avro | 数据序列化 |
| Chukwa | 日志处理、监控系统 |
| Zookeeper | 协调服务 |
Hadoop version support matrix
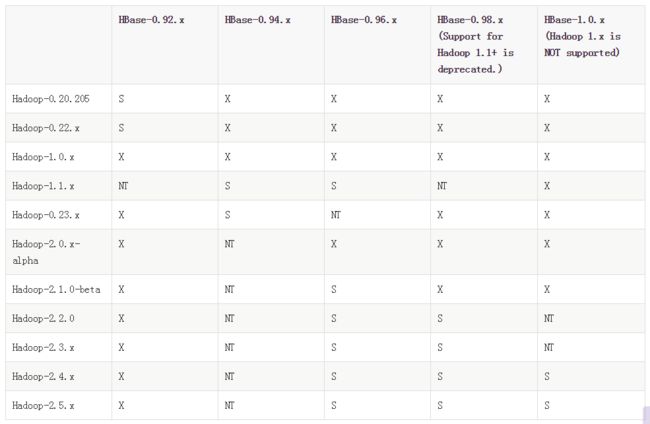
• “S” = supported
• “X” = not supported
• “NT” = Not tested
from:http://hbase.apache.org/book.html
软件选择
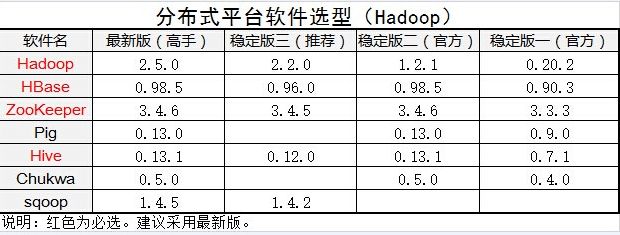
虚拟机,centos 6.5 32bit,Hadoop 2.2.0,hbase-0.98.11-hadoop2-bin.tar.gz。
安装jdk,添加java环境变量,配置ssh。
安装Hadoop 2.2.0,并伪分布式运行
解压Hadoop,重命名为apple,修改apple/etc/hadoop/下的配置文件。
配置并启动
hadoop-env.sh修改以下内容:
export JAVA_HOME=/usr/java/default
core-site.xml添加以下内容:
<property>
<name>fs.default.name</name>
<value>hdfs://localhost.localdomain:9000</value>
</property>
<property>
<name>hadoop.native.lib</name>
<value>true</value>
</property>hdfs-site.xml添加以下内容:
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
<property>
<name>dfs.namenode.name.dir</name>
<value>file:/home/tom/apple/hdfs/namenode</value>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>file:/home/tom/apple/hdfs/datanode</value>
</property>这里的两个地址,是你namenode和datanode两个节点上,希望hdfs文件存储的位置。
mapred-site.xml.template改为mapred-site.xml,添加以下内容:
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>yarn-site.xml添加以下内容:
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.nodemanager.aux-services.mapreduce.shuffle.class</name>
<value>org.apache.hadoop.mapred.ShuffleHandler</value>
</property>执行start-all.sh启动Hadoop。jps查看java进程应有
访问8088端口可以查看job信息,访问50070端口可以查看namenode信息。
错误提示:
1. 提示找不到JAVA_HOME的错误。在hadoop-env.sh中JAVA_HOME是这样表示的:export JAVA_HOME=${JAVA_HOME},我以为在profile里设置了JAVA_HOME就没问题了,可事实不是这样,需要改成export JAVA_HOME=/usr/java/default。
2. 在第一次启动Hadoop前要格式化HDFS,hadoop namenode -format。
3. 似乎hostname总是localhost.localdomain,也罢,每次启动手动更改为localhost好了,或者就用localhost.localdomain。
4. hadoop不推荐直接用start-all.sh启动,而应用start-dfs.sh和start-yarn.sh。
5. JobHistoryServer需要单独启动,通过它可以看到每个application的详细日志。启动命令如是,mr-jobhistory-daemon.sh start historyserver。
运行wordcount示例
hadoop fs -put input/file* /input
hadoop jar apple/share/hadoop/mapreduce/hadoop-mapreduce-examples-2.2.0.jar wordcount /input /output
如果自己编译wordcount程序
import java.io.IOException;
import java.util.StringTokenizer;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import org.apache.hadoop.util.GenericOptionsParser;
public class WordCount {
public static class TokenizerMapper extends Mapper<Object, Text, Text, IntWritable> {
private final static IntWritable one = new IntWritable(1);
private Text word = new Text();
public void map(Object key, Text value, Context context)
throws IOException, InterruptedException
{
StringTokenizer itr = new StringTokenizer(value.toString());
while (itr.hasMoreTokens())
{
word.set(itr.nextToken());
context.write(word, one);
}
}
}
public static class IntSumReducer extends Reducer<Text, IntWritable, Text, IntWritable> {
private IntWritable result = new IntWritable();
public void reduce(Text key, Iterable<IntWritable> values, Context context)
throws IOException, InterruptedException
{
int sum = 0;
for (IntWritable val : values)
{
sum += val.get();
}
result.set(sum);
context.write(key, result);
}
}
public static void main(String[] args) throws Exception
{
Configuration conf = new Configuration();
String[] otherArgs = new GenericOptionsParser(conf, args).getRemainingArgs();
if (otherArgs.length != 2)
{
System.err.println("Usage: wordcount <in> <out>");
System.exit(2);
}
Job job = new Job(conf, "word count");
job.setJarByClass(WordCount.class);
job.setMapperClass(TokenizerMapper.class);
job.setCombinerClass(IntSumReducer.class);
job.setReducerClass(IntSumReducer.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class);
FileInputFormat.addInputPath(job, new Path(otherArgs[0]));
FileOutputFormat.setOutputPath(job, new Path(otherArgs[1]));
System.exit(job.waitForCompletion(true) ? 0 : 1);
}
}
javac -cp $(hadoop classpath) -d temp WordCount.java
jar -cvf sort.jar -C temp .
hadoop jar sort.jar WordCount /input /output
/etc/profile的配置
我并没有配置下面的东西,但在教程里这些是配置了的。
打开/etc/profile,添加以下内容:
export HADOOP_HOME=/home/tom/apple
export HADOOP_MAPRED_HOME=$HADOOP_HOME
export HADOOP_COMMON_HOME=$HADOOP_HOME
export HADOOP_HDFS_HOME=$HADOOP_HOME
export HADOOP_COMMON_LIB_NATIVE_DIR=$HADOOP_HOME/lib/native
export HADOOP_OPTS="-Djava.library.path=$HADOOP_HOME/lib/native"
export YARN_HOME=$HADOOP_HOME执行source /etc/profile,使更改后的profile生效。
不过暂时,profile文件中我只是修改了PATH而已,将java的bin,hadoop的bin和sbin,hbase的bin添加到PATH,甚至连CLASSPATH都没有设置,现在还未出现什么异常。
HBase
下载解压,将bin添加到PATH里。
打开hbase/conf/hbase-env.sh,添加以下内容:
export JAVA_HOME=/usr/java/default
export HBASE_MANAGES_ZK=true
表示使用hbase默认自带的 Zookeeper
打开hbase/conf/hbase-site.xml,添加以下内容:
<property>
<name>hbase.rootdir</name>
<value>hdfs://localhost.localdomain:9000/hbase</value>
</property>
<property>
<name>hbase.cluster.distributed</name>
<value>true</value>
</property>
<property>
<name>hbase.master</name>
<value>localhost.localdomain:60000</value>
</property>
<property>
<name>hbase.zookeeper.quorum</name>
<value>localhost.localdomain</value>
</property>用如下命令启动和关闭Hbase:start-hbase.sh和stop-hbase.sh
注意:必须先启动Hadoop,再启动Hbase;先关闭Hbase,再关闭Hadoop
打开http://localhost:60010,如果能进去,说明安装成功。
验证HBase
进入Hbase: hbase shell
查看所有表名:list
参考文献
Hadoop2.2.0+Hbase0.98.1+Sqoop1.4.4+Hive0.13完全安装手册_百度文库
http://www.dwz.cn/DZ4rq
hbase安装配置(整合到hadoop)
http://blog.csdn.net/hguisu/article/details/7244413