Hadoop分布式文件系统和I/O
Hadoop提供的数据类型,如下所示:
- BooleanWritable:标准布尔型数值
- ByteWritable:单字节数值
- DoubleWritable:双字节数
- FloatWritable:浮点数
- IntWritable:整型数
- LongWritable:长整型数
- Text:使用UTF8格式存储的文本
- NullWritable:当<key, value>中的key或value为空时使用
说明:
(1)这些数据类型都实现了WritableComparable接口,以便用这些类型定义的数据可以被序列化进行网络传输和文件存储,以及进行大小比较。
(2)对象序列化就是把一个对象变为二进制的数据流的一种方法,通过对象序列化可以方便地实现对象的传输和存储。
二、Hadoop文件的数据结构
一般硬盘的存储系统是由盘片—>柱面—>磁道—>扇区,磁盘块(一个扇区大小)为512bytes,文件系统块(也叫数据块)为几千字节。这里要区分两个概念,即磁盘块和文件系统块,磁盘的最小存储单位是扇区(磁盘块),数据的最小存储单位是块(文件系统块)。构建于单个磁盘上的文件系统通过磁盘块来管理该文件系统块,该文件系统块的大小可以是磁盘块的整数倍。
HDFS(Hadoop分布式文件系统)同样也有块(数据块或文件系统块)的概念,默认为64M,即磁盘进行数据读/写的最小单位,HDFS上的文件也被划分为块大小的多个分块,作为独立的存储单元。HDFS提供了两种类型的容器,一种是SequenceFile,一种是MapFile,两者均可以通过Hadoop API对其进行操作,也可以通过CLI(比如shell)对其进行操作,并且还可以将SequenceFile转换成为MapFile。
- SequenceFile数据结构
SequenceFile主要由一个Header后跟多条Record组成,如下所示:
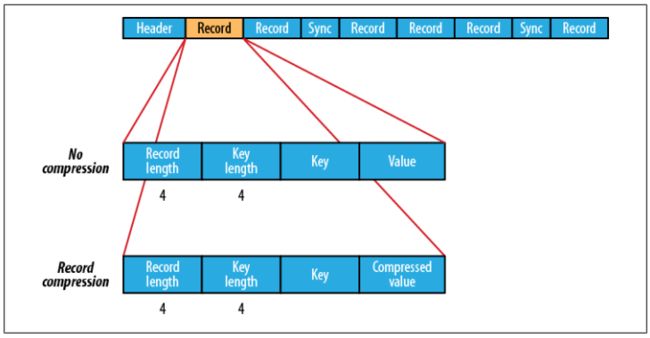
(1)Header主要包含了Key classname、Value classname存储压缩算法、用户自定义元数据等信息。此外,还包含了一些同步标识,用于快速定位到记录的边界。
(2)每条记录以键值对的方式进行存储,用来标示它的字符数组可依次解析成:记录的长度、Key的长度、Key值和Value值,并且Value值的结构取决于该记录是否被压缩。
说明:
(1)数据压缩的作用主要有两个,一是节省磁盘空间,一是加快网络传输,Sequence支持两种格式的数据压缩,分别是Record Compression和Block compression。前者是对每条记录的Value进行压缩。后者是将一连串的Record组织到一起,统一压缩成一个Block。
(2)Block信息主要存储:块所包含的记录数、每条记录Key长度的集合、每条记录Key值的集合、每条记录Value长度的集合和每条记录Value值的集合。
- MapFile数据结构
MapFile是排序后的SequenceFile,通过观察其目录结构可以看到MapFile由两部分组成,分别是data和index。index作为文件的数据索引,主要记录了每个Record的key值,以及该Record在文件中的偏移位置。在MapFile被访问的时候,索引文件会被加载到内存,通过索引映射关系可迅速定位到指定Record所在文件位置,因此,相对SequenceFile而言,MapFile的检索效率是高效的,缺点是会消耗一部分内存来存储index数据。
需注意的是,MapFile并不会把所有Record都记录到index中去,默认情况下每隔128条记录存储一个索引映射。当然,记录间隔可人为修改,通过MapFIle.Writer的setIndexInterval()方法,或修改io.map.index.interval属性。
说明:
与SequenceFile不同的是,MapFile的KeyClass一定要实现WritableComparable接口,即Key值是可比较的。
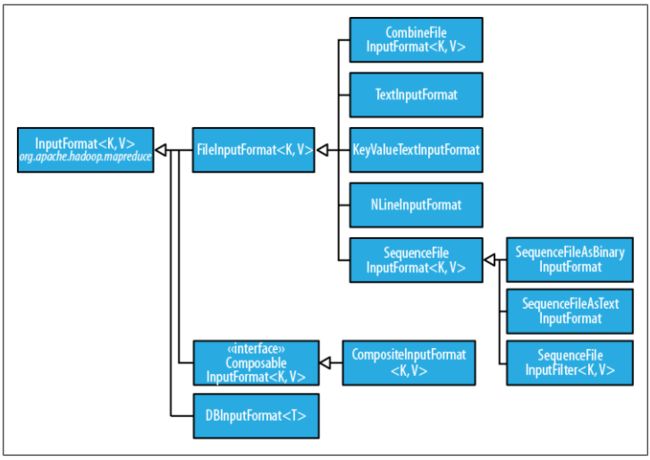
三、Hadoop输入格式
InputFormat类的层次结构,如下所示:
四、Hadoop输出格式
OutputFormat类的层次结构,如下所示:
五、数据流
- 文件读取剖析
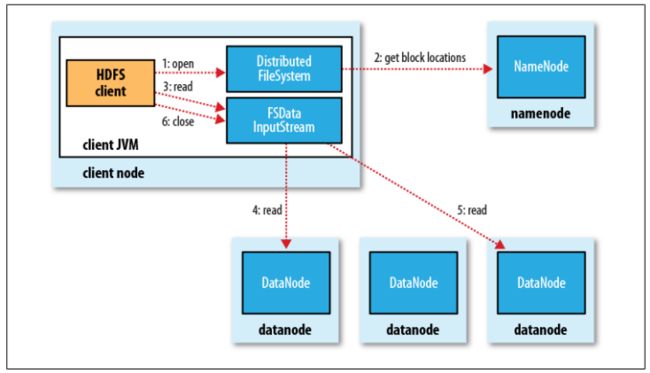
- 客户端通过调用FileSyste对象的open()方法来打开希望读取的文件,对于HDFS来说,这个对象是分布式文件系统的一个实例。参见步骤1。
- DistributedFileSystem通过使用RPC来调用namenode,以确定文件起始块的位置。对于每一个块,namenode返回存有该块复本的datanode地址。此外,这些datanode根据它们与客户端的距离来排序。如果该客户端本身就是一个datanode(比如,在一个MapReduce任务中),并保存有相应数据块的一个复本时,该节点将从本地datanode中读取数据。参见步骤2。
- DistributedFileSystem类返回一个FSDataInputStream对象(一个支持文件定位的输入流)给客户端并读取数据。FSDataInputStream类转而封装DFSInputStream对象,该对象管理着datanode和namenode的I/O。接着,客户端对这个输入流调用read()方法。参见步骤3。
- 存储着文件起始块的datanode地址的DFSInputStream随即连接距离最近的datanode。通过对数据流反复调用read()方法,可以将数据从datanode传输到客户端。参见步骤4。
- 到达块的末端时,DFSInputStream会关闭与该datanode的连接,然后寻找下一个块的最佳datanode。客户端只需要读取连续的流,并且对于客户端都是透明的。参见步骤5。
- 客户端从流中读取数据时,块是按照打开DFSInputStream与datanode新建连接的顺序读取的。它也需要询问namenode来检索下一批所需块的datanode的位置。一旦客户端完成读取,就对FSDataInputStream调用close()方法。参见步骤6。
- 文件写入剖析
- 客户端通过对DistributedFileSystem对象调用create()函数来创建文件。参见步骤1。
- DistributedFileSystem对namenode创建一个RPC调用,在文件系统的命名空间中创建一个新的文件,此时该文件中还没有相应的数据块。namenode执行各种不同的检查以确保这个文件不存在,并且客户端有创建该文件的权限。如果这些检查均通过,namenode就会为创建新文件记录一条记录;否则,文件创建失败并向客户端抛出一个IOException异常。参见步骤2。
- DistributedFileSystem向客户端返回一个FSDataOutputStream对象,由此客户端可以开始写入数据,就像读取事件一样,FSDataOutputStream封装一个DFSOutputStream对象,该对象负责处理datanode和namenode之间的通信。在客户端写入数据时,DFSOutputStream将它分成一个个的数据包,并写入内部队列,称为"数据队列"。
- DataStreamer处理数据队列,它的责任是根据datanode列表来要求namenode分配适合的新块来存储数据备份。这一组datanode构成一个管线——我们假设复本数为3,所以管线中有3个节点。DataStreamer将数据包流式传输到管线中第1个datanode,该datanode存储数据包并将它发送到管线中的第2个datanode。同样地,第2个datanode存储该数据包并且发送给管线中的第3个(也是最后一个)datanode。参见步骤4。
- DFSOutputStream也维护着一个内部数据包队列来等待datanode的收到确认回执,称为"确认队列"。当收到管道中所有datanode确认信息后,该数据包才会从确认队列删除。参数步骤5。
- 客户端完成数据的写入后,会对数据流调用close()方法。参见步骤6。该操作将剩余的所有数据包写入datanode管线中,并在联系namenode且发送文件写入完成信息之前,等待确认。参见步骤7。namenode已经知道文件由哪些块组成(通过DataStreamer询问数据块的分配),所以它在返回成功前只需要等待数据块进行最小量的复制。
[1] Hadoop权威指南
[2] Hadoop应用开发技术详解
[3] Java开发实战经典