caffe 源码简单剖析
前言
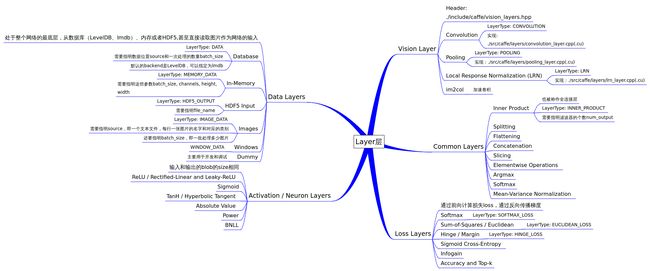
老实说,caffe中的layer层代码比较多,各种抽象看起来比较绕。官方关于Layer的教程写的很清楚,我根据这个文档,简单画了个图,再理解起来就方便了一些。
layer.hpp
和layer相关的头文件有:
common_layers.hpp
data_layers.hpp
layer.hpp
loss_layers.hpp
neuron_layers.hpp
vision_layers.hpp
其中``layer.hpp是抽象出来的基类,其他都是在其基础上的继承,也即剩下的五个头文件和上图中的五个部分。在layer.hpp`头文件里,包含了这几个头文件:
#include "caffe/blob.hpp"
#include "caffe/common.hpp"
#include "caffe/proto/caffe.pb.h"
#include "caffe/util/device_alternate.hpp"
在device_alternate.hpp中,通过#ifdef CPU_ONLY定义了一些宏来取消GPU的调用:
#define STUB_GPU(classname)
#define STUB_GPU_FORWARD(classname, funcname)
#define STUB_GPU_BACKWARD(classname, funcname)
layer中有这三个主要参数:
LayerParameter layer_param_; // 这个是protobuf文件中存储的layer参数
vector<share_ptr<Blob<Dtype>>> blobs_; // 这个存储的是layer的参数,在程序中用的
vector<bool> param_propagate_down_; // 这个bool表示是否计算各个blob参数的diff,即传播误差
Layer类的构建函数explicit Layer(const LayerParameter& param) : layer_param_(param)会尝试从protobuf文件读取参数。其三个主要接口:
virtual void SetUp(const vector<Blob<Dtype>*>& bottom, vector<Blob<Dtype>*>* top)
inline Dtype Forward(const vector<Blob<Dtype>*>& bottom, vector<Blob<Dtype>*>* top);
inline void Backward(const vector<Blob<Dtype>*>& top, const vector<bool>& propagate_down, const <Blob<Dtype>*>* bottom);
SetUp函数需要根据实际的参数设置进行实现,对各种类型的参数初始化;Forward和Backward对应前向计算和反向更新,输入统一都是bottom,输出为top,其中Backward里面有个propagate_down参数,用来表示该Layer是否反向传播参数。
在Forward和Backward的具体实现里,会根据Caffe::mode()进行对应的操作,即使用cpu或者gpu进行计算,两个都实现了对应的接口Forward_cpu、Forward_gpu和Backward_cpu、Backward_gpu,这些接口都是virtual,具体还是要根据layer的类型进行对应的计算(注意:有些layer并没有GPU计算的实现,所以封装时加入了CPU的计算作为后备)。另外,还实现了ToProto的接口,将Layer的参数写入到protocol buffer文件中。
data_layers.hpp
data_layers.hpp这个头文件包含了这几个头文件:
#include "boost/scoped_ptr.hpp"
#include "hdf5.h"
#include "leveldb/db.h"
#include "lmdb.h"
#include "caffe/blob.hpp"
#include "caffe/common.hpp"
#include "caffe/filler.hpp"
#include "caffe/internal_thread.hpp"
#include "caffe/layer.hpp"
#include "caffe/proto/caffe.pb.h"
看到hdf5、leveldb、lmdb,确实是与具体数据相关了。data_layer作为原始数据的输入层,处于整个网络的最底层,它可以从数据库leveldb、lmdb中读取数据,也可以直接从内存中读取,还可以从hdf5,甚至是原始的图像读入数据。
关于这几个数据库,简介如下:
LevelDB是Google公司搞的一个高性能的key/value存储库,调用简单,数据是被Snappy压缩,据说效率很多,可以减少磁盘I/O,具体例子可以看看维基百科。
而LMDB(Lightning Memory-Mapped Database),是个和levelDB类似的key/value存储库,但效果似乎更好些,其首页上写道“ultra-fast,ultra-compact”,这个有待进一步学习啊~~
HDF(Hierarchical Data Format)是一种为存储和处理大容量科学数据而设计的文件格式及相应的库文件,当前最流行的版本是HDF5,其文件包含两种基本数据对象:
- 群组(group):类似文件夹,可以包含多个数据集或下级群组;
- 数据集(dataset):数据内容,可以是多维数组,也可以是更复杂的数据类型。
以上内容来自维基百科,关于使用可以参考[HDF5 小试——高大上的多对象文件格式](HDF5 小试——高大上的多对象文件格式),后续会再详细的研究下怎么用。
caffe/filler.hpp的作用是在网络初始化时,根据layer的定义进行初始参数的填充,下面的代码很直观,根据FillerParameter指定的类型进行对应的参数填充。
// A function to get a specific filler from the specification given in
// FillerParameter. Ideally this would be replaced by a factory pattern,
// but we will leave it this way for now.
template <typename Dtype>
Filler<Dtype>* GetFiller(const FillerParameter& param) {
const std::string& type = param.type();
if (type == "constant") {
return new ConstantFiller<Dtype>(param);
} else if (type == "gaussian") {
return new GaussianFiller<Dtype>(param);
} else if (type == "positive_unitball") {
return new PositiveUnitballFiller<Dtype>(param);
} else if (type == "uniform") {
return new UniformFiller<Dtype>(param);
} else if (type == "xavier") {
return new XavierFiller<Dtype>(param);
} else {
CHECK(false) << "Unknown filler name: " << param.type();
}
return (Filler<Dtype>*)(NULL);
}
internal_thread.hpp里面封装了pthread函数,继承的子类可以得到一个单独的线程,主要作用是在计算当前的一批数据时,在后台获取新一批的数据。
关于data_layer,基本要注意的我都在图片上标注了。
neuron_layers.hpp
输入了data后,就要计算了,比如常见的sigmoid、tanh等等,这些都计算操作被抽象成了neuron_layers.hpp里面的类NeuronLayer,这个层只负责具体的计算,因此明确定义了输入ExactNumBottomBlobs()和ExactNumTopBlobs()都是常量1,即输入一个blob,输出一个blob。
common_layers.hpp
NeruonLayer仅仅负责简单的一对一计算,而剩下的那些复杂的计算则通通放在了common_layers.hpp中。像ArgMaxLayer、ConcatLayer、FlattenLayer、SoftmaxLayer、SplitLayer和SliceLayer等各种对blob增减修改的操作。
loss_layers.hpp
前面的data layer和common layer都是中间计算层,虽然会涉及到反向传播,但传播的源头来自于loss_layer,即网络的最终端。这一层因为要计算误差,所以输入都是2个blob,输出1个blob。
vision_layers.hpp
vision_layer主要是图像卷积的操作,像convolusion、pooling、LRN都在里面,按官方文档的说法,是可以输出图像的,这个要看具体实现代码了。里面有个im2col的实现,看caffe作者的解释,主要是为了加速卷积的,这个具体是怎么实现的要好好研究下~~
后语
结合官方文档,再加画图和看代码,终于对整个layer层有了个基本认识:data负责输入,vision负责卷积相关的计算,neuron和common负责中间部分的数据计算,而loss是最后一部分,负责计算反向传播的误差。具体的实现都在src/caffe/layers里面,慢慢再研究研究。
在这些抽象的基类头文件里,看起来挺累,好在各种搜索,也能学到一些技巧,如,巧用宏定义来简写C,C++代码,使用模板方法,将有大量重复接口和参数的类抽象为一个宏定义,达到简化代码的目的。