Spark集群配置-Mesosphere方案
#操作系统
CentOS 7
JDK 1.6以上, 如:/usr/share/jdk1.7.0_45
#修改节点名字
本次搭建Spark集群机器主从节点, 修改host(/etc/hosts)如下:
Hostname |
Ip |
|
Master |
xd-ui |
192.168.1.5 |
Slave 1 |
Xd-1 |
192.168.1.6 |
Slave 2 |
Xd-2 |
192.168.1.7 |
Slave 3 |
Xd-3 |
192.168.1.8 |
#安装mesosphere repo
sudo rpm -Uvh http://repos.mesosphere.io/el/7/noarch/RPMS/mesosphere-el-repo-7-1.noarch.rpm
#下载apache mesos
wget http://downloads.mesosphere.io/master/centos/7/mesos-0.21.1-1.1.centos701406.x86_64.rpm
sudo rpm -Uvh mesos-0.21.1-1.1.centos701406.x86_64.rpm
#安装marathon
sudo yum -y install marathon
#安装chronos
sudo yum -y install chronos
ZooKeeper配置,此处略,详细看zook配置文档
On each node, replacing the IP addresses below with each master's IP address, set /etc/mesos/zk to:
zk://1.1.1.1:2181,2.2.2.2:2181,3.3.3.3:2181/mesos
#配置Mesosphere master节点
quorum
设置:/etc/mesos-master/quorum内容: 1
目前个人理解Quorum主节点个数,类似hadoop临时主节点,大家有意见的可以反馈我。
Hostname
设置/etc/mesos-master/hostname为xd-ui
Work_dir
设置/etc/mesos-master/work_dir为工作目前,默认为:/var/lib/mesos,我这里设置/alidata1/mesos
配置结构显示如下
[dev@xd-ui ~]$ tree /etc/mesos-master/ |
重启Mesos Master:
[dev@xd-ui ~]$sudo service mesos-master restart |
#配置Mesosphere slave节点
Xd-1
配置各个节点的Slaves |
Xd-2
配置各个节点的Slaves |
Xd-3
配置各个节点的Slaves |
在节点[xd-1,xd-2,xd-3]上重启各个Mesos Slaves:
[dev@xd-1 ~]$sudo service mesos-slave restart |
检查各个节点是否起来
[dev@xd-ui ~]$sudo ps -ef | grep mesos /usr/sbin/mesos-slave --master=zk://xd-1:2181,xd-2:2181,xd-3:2181/mesos --log_dir=/var/log/mesos --hostname=xd-3 --work_dir=/alidata1/mesos
|
出现类似内容则启动正常
#访问Mesosphere主页,确认各个节点是否正常
浏览器输入 http://xd-ui:5050/,点击slaves标签页
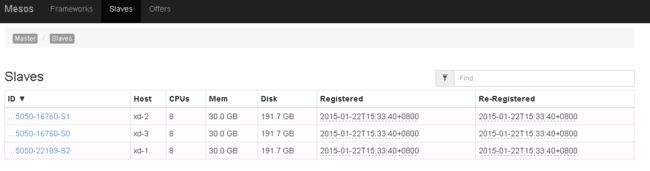
#Spark配置
下载spark分布式二进制套件
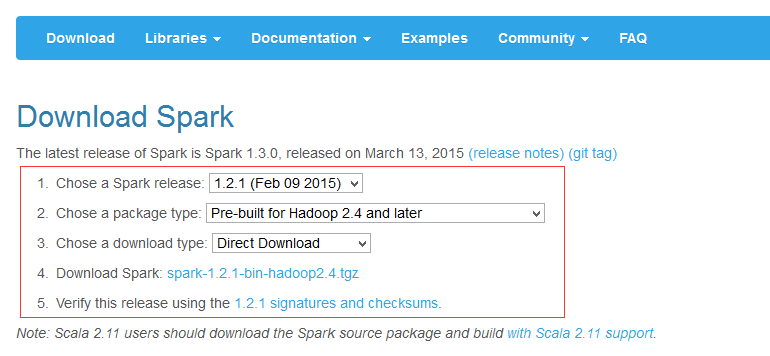
注意:按实际需要,选择对应的spark和hadoop版本
解压spark-1.2.1-bin-hadoop2.4.tgz
tar -czvf spark-1.2.1-bin-hadoop2.4.tgz spark-1.2.1-bin-hadoop2.4 |
修改${SPARK_HOME}/bin/spark-class或者conf/spark-env.sh,在首行添加:
export JAVA_HOME=/usr/share/jdk1.7.0_45 |
确定所有的Mesos 节点的JDK,按照目录是一致的.
再压缩成spark-1.2.1-bin-hadoop2.4.tgz
tar -czvf spark-1.2.1-bin-haoop2.4.tgz |
再发布压缩tgz包到hdfs或者http。
可以使用Nginx做一个简单的下载服务器,比如我的下载地址是:
http://192.168.0.7/download/ spark-1.2.1-bin-haoop2.4.tgz |
把解压的spark目录放到mesos-master上。
并且配置${SPARK_HOME}/conf/spark-env.sh,在文件末尾添加:
export MESOS_NATIVE_LIBRARY=/usr/local/lib/libmesos.so |
#启动spark shell
[dev@xd-ui spark-1.2.0-dist]$ ./bin/spark-shell
Using Spark's default log4j profile: org/apache/spark/log4j-defaults.properties
15/01/22 16:07:46 INFO SecurityManager: Changing view acls to: dev
15/01/22 16:07:46 INFO SecurityManager: Changing modify acls to: dev
15/01/22 16:07:46 INFO SecurityManager: SecurityManager: authentication disabled; ui acls disabled; users with view permissions: Set(dev); users with modify permissions: Set(dev)
15/01/22 16:07:46 INFO HttpServer: Starting HTTP Server
15/01/22 16:07:46 INFO Utils: Successfully started service 'HTTP class server' on port 50256.
Welcome to
____ __
/ __/__ ___ _____/ /__
_\ \/ _ \/ _ `/ __/ '_/
/___/ .__/\_,_/_/ /_/\_\ version 1.2.0
/_/
Using Scala version 2.10.4 (Java HotSpot(TM) 64-Bit Server VM, Java 1.7.0_45)
Type in expressions to have them evaluated.
输入测试代码
scala> val data = 1 to 10000; val distData = sc.parallelize(data); distData.filter(_< 10).collect()
data: scala.collection.immutable.Range.Inclusive = Range(1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17, 18, 19, 20, 21, 22, 23, 24, 25, 26, 27, 28, 29, 30, 31, 32, 33, 34, 35, 36, 37, 38, 39, 40, 41, 42, 43, 44, 45, 46, 47, 48, 49, 50, 51, 52, 53, 54, 55, 56, 57, 58, 59, 60, 61, 62, 63, 64, 65, 66, 67, 68, 69, 70, 71, 72, 73, 74, 75, 76, 77, 78, 79, 80, 81, 82, 83, 84, 85, 86, 87, 88, 89, 90, 91, 92, 93, 94, 95, 96, 97, 98, 99, 100, 101, 102, 103, 104, 105, 106, 107, 108, 109, 110, 111, 112, 113, 114, 115, 116, 117, 118, 119, 120, 121, 122, 123, 124, 125, 126, 127, 128, 129, 130, 131, 132, 133, 134, 135, 136, 137, 138, 139, 140, 141, 142, 143, 144, 145, 146, 147, 148, 149, 150, 151, 152, 153, 154, 155, 156, 157, 158, 159, 160, 161, 162, 163, 164, 165, 166, 167, 168, 169, 170...
#查看mesosphere ui界面确定任务是否运行成功
浏览器输入http://xd-ui:5050
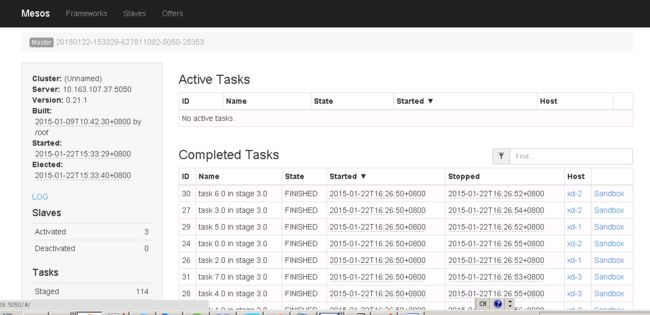
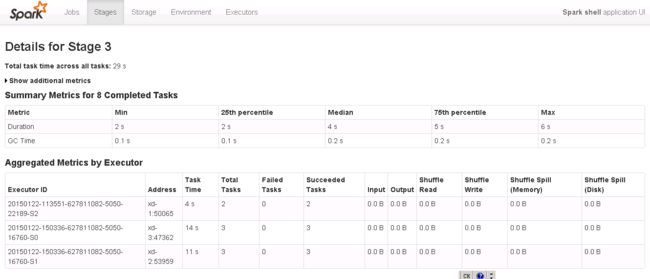
#打开spark WebUI界面查看任务执行结果:
浏览器输入:http://xd-ui:4040
参考资料
http://mesosphere.com/downloads/details/index.html http://mesosphere.com/docs/tutorials/run-spark-on-mesos/ http://mesosphere.com/docs/getting-started/datacenter/install/ http://mesos.apache.org/gettingstarted/ http://spark.apache.org/docs/latest/running-on-mesos.html#configuration |