Spark定制班第5课:基于案例一节课贯通Spark Streaming流计算框架的运行源码
本期内容:
来看下JobScheduler的启动过程start()。其中启动了EventLoop、StreamListenerBus、ReceiverTracker和jobGenerator等多项工作。
JobScheduler.start() 启动的第二项工作 StreamListenerBus。用于异步传递StreamingListenerEvents到注册的StreamingListeners。用于更新Spark UI中StreamTab的内容。
1 在线动态计算分类最热门商品案例回顾与演示
2 基于案例贯通Spark Streaming的运行源码
1 在线动态计算分类最热门商品案例回顾与演示
我们用Spark Streaming+Spark SQL来实现分类最热门商品的在线动态计算。代码如下:
package com.dt.spark.streaming
import org.apache.spark.SparkConf
import org.apache.spark.sql.Row
import org.apache.spark.sql.hive.HiveContext
import org.apache.spark.sql.types.{IntegerType, StringType, StructField, StructType}
import org.apache.spark.streaming.{Seconds, StreamingContext}
/**
* 使用Spark Streaming+Spark SQL来在线动态计算电商中不同类别中最热门的商品排名,例如手机
* 这个类别下面最热门的三种手机、电视这个类别下最热门的三种电视,该实例在实际生产环境下
* 具有非常重大的意义;
*
* @author DT大数据梦工厂
* 新浪微博: http://weibo.com/ilovepains/
*
* 实现技术:Spark Streaming+Spark SQL,之所以Spark Streaming能够使用ML、sql、graphx等
* 功能是因为有foreachRDD和Transform等接口,这些接口中其实是基于RDD进行操作,所以以RDD为
* 基石,就可以直接使用Spark其它所有的功能,就像直接调用API一样简单。
* 假设说这里的数据的格式:user item category,例如Rocky Samsung Android
*/
object OnlineTheTop3ItemForEachCategory2DB {
def main(args: Array[String]){
/**
* 第1步:创建Spark的配置对象SparkConf,设置Spark程序的运行时的配置信息,
* 例如说通过setMaster来设置程序要链接的Spark集群的Master的URL,如果设置
* 为local,则代表Spark程序在本地运行,特别适合于机器配置条件非常差(例如
* 只有1G的内存)的初学者 *
*/
val conf = new SparkConf() //创建SparkConf对象
//设置应用程序的名称,在程序运行的监控界面可以看到名称
conf.setAppName("OnlineTheTop3ItemForEachCategory2DB")
conf.setMaster("spark://Master:7077") //此时,程序在Spark集群
//设置batchDuration时间间隔来控制Job生成的频率并且创建Spark Streaming执行的入口
val ssc = new StreamingContext(conf, Seconds(5))
ssc.checkpoint("/root/Documents/SparkApps/checkpoint")
val userClickLogsDStream = ssc.socketTextStream("Master", 9999)
val formattedUserClickLogsDStream = userClickLogsDStream.map(clickLog =>
(clickLog.split(" ")(2) + "_" + clickLog.split(" ")(1), 1))
val categoryUserClickLogsDStream = formattedUserClickLogsDStream.reduceByKeyAndWindow(_+_,
_-_, Seconds(60), Seconds(20))
categoryUserClickLogsDStream.foreachRDD { rdd => {
if (rdd.isEmpty()) {
println("No data inputted!!!")
} else {
val categoryItemRow = rdd.map(reducedItem => {
val category = reducedItem._1.split("_")(0)
val item = reducedItem._1.split("_")(1)
val click_count = reducedItem._2
Row(category, item, click_count)
})
val structType = StructType(Array(
StructField("category", StringType, true),
StructField("item", StringType, true),
StructField("click_count", IntegerType, true)
))
val hiveContext = new HiveContext(rdd.context)
val categoryItemDF = hiveContext.createDataFrame(categoryItemRow, structType)
categoryItemDF.registerTempTable("categoryItemTable")
val reseltDataFram = hiveContext.sql("SELECT category,item,click_count FROM" +
" (SELECT category,item,click_count,row_number()" +
" OVER (PARTITION BY category ORDER BY click_count DESC) rank" +
"
FROM categoryItemTable) subquery WHERE rank <= 3")
reseltDataFram.show()
val resultRowRDD = reseltDataFram.rdd
resultRowRDD.foreachPartition { partitionOfRecords => {
if (partitionOfRecords.isEmpty){
println("This RDD is not null but partition is null")
} else {
// ConnectionPool is a static, lazily initialized pool of connections
val connection = ConnectionPool.getConnection()
partitionOfRecords.foreach(record => {
val sql = "insert into categorytop3(category,item,client_count) " +
values('" + record.getAs("category") + "','" +
record.getAs("item") + "'," + record.getAs("click_count") + ")"
val stmt = connection.createStatement();
stmt.executeUpdate(sql);
})
ConnectionPool.returnConnection(connection) // return to the pool for future reuse
}
}
}
}
}
}
/**
* 在StreamingContext调用start方法的内部其实是会启动JobScheduler的Start方法,进行消息循环,
* 在JobScheduler的start内部会构造JobGenerator和ReceiverTacker,并且调用JobGenerator和
* ReceiverTacker的start方法:
* 1,JobGenerator启动后会不断的根据batchDuration生成一个个的Job
* 2,ReceiverTracker启动后首先在Spark Cluster中启动Receiver(其实是在Executor中先启动
* ReceiverSupervisor),在Receiver收到数据后会通过ReceiverSupervisor存储到Executor并且
* 把数据的Metadata信息发送给Driver中的ReceiverTracker,在ReceiverTracker内部会通过
* ReceivedBlockTracker来管理接受到的元数据信息
* 每个BatchInterval会产生一个具体的Job,其实这里的Job不是Spark Core中所指的Job,它只是基于
* DStreamGraph而生成的RDD的DAG而已,从Java角度讲,相当于Runnable接口实例,此时要想运行Job
* 需要提交给JobScheduler,在JobScheduler中通过线程池的方式找到一个单独的线程来提交Job到集群
* 运行(其实是在线程中基于RDD的Action触发真正的作业的运行),为什么使用线程池呢?
* 1,作业不断生成,所以为了提升效率,我们需要线程池;这和在Executor中通过线程池执行Task
* 有异曲同工之妙;
* 2,有可能设置了Job的FAIR公平调度的方式,这个时候也需要多线程的支持;
*/
ssc.start()
ssc.awaitTermination()
}
}
2 基于案例贯通Spark Streaming的运行源码
我们将基于以上案例,粗略地分析一下Spark源码,提示一些有针对性的内容,以了解其运行的主要流程。
代码没有直接使用SparkContext,而是使用StreamingContext。
我们来看看StreamingContext 的源码片段:
/**
* Create a StreamingContext by providing the configuration necessary for a new SparkContext.
* @param conf a org.apache.spark.SparkConf object specifying Spark parameters
* @param batchDuration the time interval at which streaming data will be divided into batches
*/
def this(conf: SparkConf, batchDuration: Duration) = {
this(StreamingContext.
createNewSparkContext(conf), null, batchDuration)
}
没错,
createNewSparkContext就是创建SparkContext:
private[streaming] def createNewSparkContext(conf: SparkConf): SparkContext = {
new SparkContext(conf)
}
这说明Spark Streaming也是Spark上的一个应用程序。
案例最开始,肯定要通过数据流创建一个InputDStream 。
val userClickLogsDStream = ssc.socketTextStream("Master", 9999)
socketTextStream方法定义如下:
/**
* Create a input stream from TCP source hostname:port. Data is received using
* a TCP socket and the receive bytes is interpreted as UTF8 encoded `\n` delimited
* lines.
* @param hostname Hostname to connect to for receiving data
* @param port Port to connect to for receiving data
* @param storageLevel Storage level to use for storing the received objects
* (default: StorageLevel.MEMORY_AND_DISK_SER_2)
*/
def socketTextStream(
hostname: String,
port: Int,
storageLevel: StorageLevel = StorageLevel.MEMORY_AND_DISK_SER_2
): ReceiverInputDStream[String] = withNamedScope("socket text stream") {
socketStream[String](hostname, port, SocketReceiver.bytesToLines, storageLevel)
}
可看到代码最后面调用socketStream。
socketStream定义如下:
/**
* Create a input stream from TCP source hostname:port. Data is received using
* a TCP socket and the receive bytes it interepreted as object using the given
* converter.
* @param hostname Hostname to connect to for receiving data
* @param port Port to connect to for receiving data
* @param converter Function to convert the byte stream to objects
* @param storageLevel Storage level to use for storing the received objects
* @tparam T Type of the objects received (after converting bytes to objects)
*/
def socketStream[T: ClassTag](
hostname: String,
port: Int,
converter: (InputStream) => Iterator[T],
storageLevel: StorageLevel
): ReceiverInputDStream[T] = {
new SocketInputDStream[T](this, hostname, port, converter, storageLevel)
}
实际上生成
SocketInputDStream。
SocketInputDStream类如下:
private[streaming]
class SocketInputDStream[T: ClassTag](
ssc_ : StreamingContext,
host: String,
port: Int,
bytesToObjects: InputStream => Iterator[T],
storageLevel: StorageLevel
) extends ReceiverInputDStream[T](ssc_) {
def getReceiver(): Receiver[T] = {
new SocketReceiver(host, port, bytesToObjects, storageLevel)
}
}
SocketInputDStream继承ReceiverInputDStream。
其中实现getReceiver方法,返回SocketReceiver对象。
总结一下SocketInputDStream的继承关系:
SocketInputDStream -> ReceiverInputDStream -> InputDStream -> DStream。
DStream是生成RDD的模板,是逻辑级别,当达到Interval的时候这些模板会被BatchData实例化成为RDD和DAG。
看看DStream的源码片段:
// RDDs generated, marked as private[streaming] so that testsuites can access it
@transient
private[streaming] var generatedRDDs = new HashMap[Time, RDD[T]] ()
看看DStream的getOrCompute:
/**
* Get the RDD corresponding to the given time; either retrieve it from cache
* or compute-and-cache it.
*/
private[streaming] final def getOrCompute(time: Time): Option[RDD[T]] = {
// If RDD was already generated, then retrieve it from HashMap,
// or else compute the RDD
generatedRDDs.get(time).orElse {
// Compute the RDD if time is valid (e.g. correct time in a sliding window)
// of RDD generation, else generate nothing.
if (isTimeValid(time)) {
val rddOption = createRDDWithLocalProperties(time, displayInnerRDDOps = false) {
// Disable checks for existing output directories in jobs launched by the streaming
// scheduler, since we may need to write output to an existing directory during checkpoint
// recovery; see SPARK-4835 for more details. We need to have this call here because
// compute() might cause Spark jobs to be launched.
PairRDDFunctions.disableOutputSpecValidation.withValue(true) {
compute(time)
}
}
rddOption.foreach { case newRDD =>
// Register the generated RDD for caching and checkpointing
if (storageLevel != StorageLevel.NONE) {
newRDD.persist(storageLevel)
logDebug(s"Persisting RDD ${newRDD.id} for time $time to $storageLevel")
}
if (checkpointDuration != null && (time - zeroTime).isMultipleOf(checkpointDuration)) {
newRDD.checkpoint()
logInfo(s"Marking RDD ${newRDD.id} for time $time for checkpointing")
}
generatedRDDs.put(time, newRDD)
}
rddOption
} else {
None
}
}
}
主要是生成RDD
,再将生成的RDD放在HashMap中。具体生成RDD过程以后剖析。
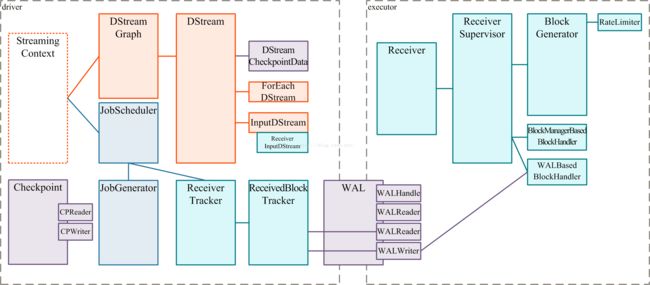
目前大致讲了DStream和RDD这些核心概念在Spark Streaming中的使用。
体现Spark Streaming应用运行流程的关键类如下图所示。
先看看ScreamingContext的start()。start()方法启动StreamContext,由于Spark应用程序不能有多个SparkContext对象实例,所以Spark Streaming框架在启动时对状态进行判断。代码如下:
/**
* Start the execution of the streams.
*
* @throws IllegalStateException if the StreamingContext is already stopped.
*/
def start(): Unit = synchronized {
state match {
case INITIALIZED =>
startSite.set(DStream.getCreationSite())
StreamingContext.ACTIVATION_LOCK.synchronized {
StreamingContext.assertNoOtherContextIsActive()
try {
validate()
// Start the streaming scheduler in a new thread, so that thread local properties
// like call sites and job groups can be reset without affecting those of the
// current thread.
ThreadUtils.runInNewThread("streaming-start") {
sparkContext.setCallSite(startSite.get)
sparkContext.clearJobGroup()
sparkContext.setLocalProperty(SparkContext.SPARK_JOB_INTERRUPT_ON_CANCEL, "false")
//启动JobScheduler
scheduler.start()
}
state = StreamingContextState.ACTIVE
} catch {
case NonFatal(e) =>
logError("Error starting the context, marking it as stopped", e)
scheduler.stop(false)
state = StreamingContextState.STOPPED
throw e
}
StreamingContext.setActiveContext(this)
}
shutdownHookRef = ShutdownHookManager.addShutdownHook(
StreamingContext.SHUTDOWN_HOOK_PRIORITY)(stopOnShutdown)
// Registering Streaming Metrics at the start of the StreamingContext
assert(env.metricsSystem != null)
env.metricsSystem.registerSource(streamingSource)
uiTab.foreach(_.attach())
logInfo("StreamingContext started")
case ACTIVE =>
logWarning("StreamingContext has already been started")
case STOPPED =>
throw new IllegalStateException("StreamingContext has already been stopped")
}
}
初始状态时,会启动JobScheduler。
来看下JobScheduler的启动过程start()。其中启动了EventLoop、StreamListenerBus、ReceiverTracker和jobGenerator等多项工作。
def start(): Unit = synchronized {
if (eventLoop != null) return // scheduler has already been started
logDebug("Starting JobScheduler")
eventLoop = new EventLoop[JobSchedulerEvent]("JobScheduler") {
override protected def onReceive(event: JobSchedulerEvent): Unit = processEvent(event)
override protected def onError(e: Throwable): Unit = reportError("Error in job scheduler", e)
}
// 启动消息循环处理线程。用于处理JobScheduler的各种事件。
eventLoop.start()
// attach rate controllers of input streams to receive batch completion updates
for {
inputDStream <- ssc.graph.getInputStreams
rateController <- inputDStream.rateController
} ssc.addStreamingListener(rateController)
// 启动监听器。用于更新Spark UI中StreamTab的内容。
listenerBus.start(ssc.sparkContext)
receiverTracker = new ReceiverTracker(ssc)
// 生成InputInfoTracker。用于
管理所有的输入的流,以及他们输入的数据统计。这些
信息将通过 StreamingListener监听。
inputInfoTracker = new InputInfoTracker(ssc)
// 启动ReceiverTracker。用于处理数据接收、数据缓存、Block生成。
receiverTracker.start()
// 启动JobGenerator。用于DStreamGraph初始化、DStream与RDD的转换、生成Job、提交执行等工作。
jobGenerator.start()
logInfo("Started JobScheduler")
}
JobScheduler中的
消息处理函数processEvent
,处理三类消息:Job已开始,Job已完成,错误报告。
private def processEvent(event: JobSchedulerEvent) {
try {
event match {
case JobStarted(job, startTime) => handleJobStart(job, startTime)
case JobCompleted(job, completedTime) => handleJobCompletion(job, completedTime)
case ErrorReported(m, e) => handleError(m, e)
}
} catch {
case e: Throwable =>
reportError("Error in job scheduler", e)
}
}
我们再粗略地分析一下JobScheduler.start()中启动的工作。
先看JobScheduler.start()启动的第一项工作EventLoop。EventLoop用于处理JobScheduler的各种事件。
EventLoop中有事件队列:
private val eventQueue: BlockingQueue[E] = new LinkedBlockingDeque[E]()
还有一个线程处理队列中的事件:
private val eventThread = new Thread(name) {
setDaemon(true)
override def run(): Unit = {
try {
while (!stopped.get) {
val event = eventQueue.take()
try {
onReceive(event)
} catch {
case NonFatal(e) => {
try {
onError(e)
} catch {
case NonFatal(e) => logError("Unexpected error in " + name, e)
}
}
}
}
} catch {
case ie: InterruptedException => // exit even if eventQueue is not empty
case NonFatal(e) => logError("Unexpected error in " + name, e)
}
}
}
这个线程中的onReceive、onError,在JobScheduler中的EventLoop实例化时已定义。
JobScheduler.start() 启动的第二项工作 StreamListenerBus。用于异步传递StreamingListenerEvents到注册的StreamingListeners。用于更新Spark UI中StreamTab的内容。
以下代码用于传递各种事件:
override def onPostEvent(listener: StreamingListener, event: StreamingListenerEvent): Unit = {
event match {
case
receiverStarted: StreamingListenerReceiverStarted =>
listener.onReceiverStarted(receiverStarted)
case
receiverError: StreamingListenerReceiverError =>
listener.onReceiverError(receiverError)
case
receiverStopped: StreamingListenerReceiverStopped =>
listener.onReceiverStopped(receiverStopped)
case
batchSubmitted: StreamingListenerBatchSubmitted =>
listener.onBatchSubmitted(batchSubmitted)
case
batchStarted: StreamingListenerBatchStarted =>
listener.onBatchStarted(batchStarted)
case
batchCompleted: StreamingListenerBatchCompleted =>
listener.onBatchCompleted(batchCompleted)
case
outputOperationStarted: StreamingListenerOutputOperationStarted =>
listener.onOutputOperationStarted(outputOperationStarted)
case
outputOperationCompleted: StreamingListenerOutputOperationCompleted =>
listener.onOutputOperationCompleted(outputOperationCompleted)
case _ =>
}
}
看JobScheduler.start()启动的第三项工作ReceiverTracker。
ReceiverTracker用于管理所有的输入的流,以及他们输入的数据统计。这些信息将通过 StreamingListener监听。
ReceiverTracker的start()中,会内部实例化ReceiverTrackerEndpoint这个Rpc消息通信体。
def start(): Unit = synchronized {
if (isTrackerStarted) {
throw new SparkException("ReceiverTracker already started")
}
if (!receiverInputStreams.isEmpty) {
endpoint = ssc.env.rpcEnv.setupEndpoint(
"ReceiverTracker", new ReceiverTrackerEndpoint(ssc.env.rpcEnv))
if (!skipReceiverLaunch) launchReceivers()
logInfo("ReceiverTracker started")
trackerState = Started
}
}
在ReceiverTracker启动的过程中会调用其launchReceivers方法:
/**
* Get the receivers from the ReceiverInputDStreams, distributes them to the
* worker nodes as a parallel collection, and runs them.
*/
private def launchReceivers(): Unit = {
val receivers = receiverInputStreams.map(nis => {
val rcvr = nis.getReceiver()
rcvr.setReceiverId(nis.id)
rcvr
})
runDummySparkJob()
logInfo("Starting " + receivers.length + " receivers")
endpoint.send(StartAllReceivers(receivers))
}
其中调用了runDummySparkJob方法来启动Spark Streaming的框架第一个Job,其中collect这个action操作会触发Spark Job的执行。这个方法是为了确保每个Slave都注册上,避免所有Receiver都在一个节点,使后面的计算能负载均衡。
/**
* Run the dummy Spark job to ensure that all slaves have registered. This avoids all the
* receivers to be scheduled on the same node.
*
* TODO Should poll the executor number and wait for executors according to
* "spark.scheduler.minRegisteredResourcesRatio" and
* "spark.scheduler.maxRegisteredResourcesWaitingTime" rather than running a dummy job.
*/
private def runDummySparkJob(): Unit = {
if (!ssc.sparkContext.isLocal) {
ssc.sparkContext.makeRDD(1 to 50, 50).map(x => (x, 1)).reduceByKey(_ + _, 20).collect()
}
assert(getExecutors.nonEmpty)
}
ReceiverTracker.launchReceivers()
还调用了endpoint.send(StartAllReceivers(receivers))方法,Rpc消息通信体发送StartAllReceivers消息。
ReceiverTrackerEndpoint它自己接收到消息后,先根据调度策略获得Recevier在哪个Executor上运行,然后在调用startReceiver(receiver, executors)方法,来启动Receiver。
override def receive: PartialFunction[Any, Unit] = {
// Local messages
case StartAllReceivers(receivers) =>
val scheduledLocations = schedulingPolicy.scheduleReceivers(receivers, getExecutors)
for (receiver <- receivers) {
val executors = scheduledLocations(receiver.streamId)
updateReceiverScheduledExecutors(receiver.streamId, executors)
receiverPreferredLocations(receiver.streamId) = receiver.preferredLocation
startReceiver(receiver, executors)
}
在startReceiver方法中,ssc.sparkContext.submitJob提交Job的时候传入startReceiverFunc这个方法,因为startReceiverFunc该方法是在Executor上执行的。而在startReceiverFunc方法中是实例化ReceiverSupervisorImpl对象,该对象是对Receiver进行管理和监控。这个Job是Spark Streaming框架为我们启动的第二个Job,且一直运行。因为supervisor.awaitTermination()该方法会阻塞等待退出。
/**
* Start a receiver along with its scheduled executors
*/
private def startReceiver(
receiver: Receiver[_],
scheduledLocations: Seq[TaskLocation]): Unit = {
def shouldStartReceiver: Boolean = {
// It's okay to start when trackerState is Initialized or Started
!(isTrackerStopping || isTrackerStopped)
}
val receiverId = receiver.streamId
if (!shouldStartReceiver) {
onReceiverJobFinish(receiverId)
return
}
val checkpointDirOption = Option(ssc.checkpointDir)
val serializableHadoopConf =
new SerializableConfiguration(ssc.sparkContext.hadoopConfiguration)
// Function to start the receiver on the worker node
val startReceiverFunc: Iterator[Receiver[_]] => Unit =
(iterator: Iterator[Receiver[_]]) => {
if (!iterator.hasNext) {
throw new SparkException(
"Could not start receiver as object not found.")
}
if (TaskContext.get().attemptNumber() == 0) {
val receiver = iterator.next()
assert(iterator.hasNext == false)
//实例化Receiver监控者
val supervisor = new ReceiverSupervisorImpl(
receiver, SparkEnv.get, serializableHadoopConf.value, checkpointDirOption)
supervisor.start()
supervisor.awaitTermination()
} else {
// It's restarted by TaskScheduler, but we want to reschedule it again. So exit it.
}
}
// Create the RDD using the scheduledLocations to run the receiver in a Spark job
val receiverRDD: RDD[Receiver[_]] =
if (scheduledLocations.isEmpty) {
ssc.sc.makeRDD(Seq(receiver), 1)
} else {
val preferredLocations = scheduledLocations.map(_.toString).distinct
ssc.sc.makeRDD(Seq(receiver -> preferredLocations))
}
receiverRDD.setName(s"Receiver $receiverId")
ssc.sparkContext.setJobDescription(s"Streaming job running receiver $receiverId")
ssc.sparkContext.setCallSite(Option(ssc.getStartSite()).getOrElse(Utils.getCallSite()))
val future = ssc.sparkContext.submitJob[Receiver[_], Unit, Unit](
receiverRDD, startReceiverFunc, Seq(0), (_, _) => Unit, ())
// We will keep restarting the receiver job until ReceiverTracker is stopped
future.onComplete {
case Success(_) =>
if (!shouldStartReceiver) {
onReceiverJobFinish(receiverId)
} else {
logInfo(s"Restarting Receiver $receiverId")
self.send(RestartReceiver(receiver))
}
case Failure(e) =>
if (!shouldStartReceiver) {
onReceiverJobFinish(receiverId)
} else {
logError("Receiver has been stopped. Try to restart it.", e)
logInfo(s"Restarting Receiver $receiverId")
self.send(RestartReceiver(receiver))
}
}(submitJobThreadPool)
logInfo(s"Receiver ${receiver.streamId} started")
}
接下来看下ReceiverSupervisorImpl的启动过程,先启动所有注册上的BlockGenerator对象,然后向ReceiverTrackerEndpoint发送RegisterReceiver消息,再调用receiver的onStart方法。
/** Start the supervisor */
def start() {
onStart()
startReceiver()
}
其中的onStart():
override protected def onStart() {
registeredBlockGenerators.foreach { _.start() }
}
其中的startReceiver():
/** Start receiver */
def startReceiver(): Unit = synchronized {
try {
if (onReceiverStart()) {
logInfo("Starting receiver")
receiverState = Started
receiver.onStart()
logInfo("Called receiver onStart")
} else {
// The driver refused us
stop("Registered unsuccessfully because Driver refused to start receiver " + streamId, None)
}
} catch {
case NonFatal(t) =>
stop("Error starting receiver " + streamId, Some(t))
}
}
override protected def onReceiverStart(): Boolean = {
val msg = RegisterReceiver(
streamId, receiver.getClass.getSimpleName, host, executorId, endpoint)
trackerEndpoint.askWithRetry[Boolean](msg)
}
其中在Driver运行的ReceiverTrackerEndpoint对象接收到RegisterReceiver消息后,将streamId, typ, host, executorId, receiverEndpoint封装为ReceiverTrackingInfo保存到内存对象receiverTrackingInfos这个HashMap中。
override def receiveAndReply(context: RpcCallContext): PartialFunction[Any, Unit] = {
// Remote messages
case RegisterReceiver(streamId, typ, host, executorId, receiverEndpoint) =>
val successful =
registerReceiver(streamId, typ, host, executorId, receiverEndpoint, context.senderAddress)
context.reply(successful)
case AddBlock(receivedBlockInfo) =>
if (WriteAheadLogUtils.isBatchingEnabled(ssc.conf, isDriver = true)) {
walBatchingThreadPool.execute(new Runnable {
override def run(): Unit = Utils.tryLogNonFatalError {
if (active) {
context.reply(addBlock(receivedBlockInfo))
} else {
throw new IllegalStateException("ReceiverTracker RpcEndpoint shut down.")
}
}
})
} else {
context.reply(addBlock(receivedBlockInfo))
}
/** Register a receiver */
private def registerReceiver(
streamId: Int,
typ: String,
host: String,
executorId: String,
receiverEndpoint: RpcEndpointRef,
senderAddress: RpcAddress
): Boolean = {
if (!receiverInputStreamIds.contains(streamId)) {
throw new SparkException("Register received for unexpected id " + streamId)
}
if (isTrackerStopping || isTrackerStopped) {
return false
}
val scheduledLocations = receiverTrackingInfos(streamId).scheduledLocations
val acceptableExecutors = if (scheduledLocations.nonEmpty) {
// This receiver is registering and it's scheduled by
// ReceiverSchedulingPolicy.scheduleReceivers. So use "scheduledLocations" to check it.
scheduledLocations.get
} else {
// This receiver is scheduled by "ReceiverSchedulingPolicy.rescheduleReceiver", so calling
// "ReceiverSchedulingPolicy.rescheduleReceiver" again to check it.
scheduleReceiver(streamId)
}
def isAcceptable: Boolean = acceptableExecutors.exists {
case loc: ExecutorCacheTaskLocation => loc.executorId == executorId
case loc: TaskLocation => loc.host == host
}
if (!isAcceptable) {
// Refuse it since it's scheduled to a wrong executor
false
} else {
val name = s"${typ}-${streamId}"
val receiverTrackingInfo = ReceiverTrackingInfo(
streamId,
ReceiverState.ACTIVE,
scheduledLocations = None,
runningExecutor = Some(ExecutorCacheTaskLocation(host, executorId)),
name = Some(name),
endpoint = Some(receiverEndpoint))
receiverTrackingInfos.put(streamId, receiverTrackingInfo)
listenerBus.post(StreamingListenerReceiverStarted(receiverTrackingInfo.toReceiverInfo))
logInfo("Registered receiver for stream " + streamId + " from " + senderAddress)
true
}
}
Receiver的启动,以ssc.socketTextStream("localhost", 9999)为例,创建的是SocketReceiver对象。内部启动一个线程来连接Socket Server,读取socket数据并存储。
private[streaming]
class SocketReceiver[T: ClassTag](
host: String,
port: Int,
bytesToObjects: InputStream => Iterator[T],
storageLevel: StorageLevel
) extends Receiver[T](storageLevel) with Logging {
def onStart() {
// Start the thread that receives data over a connection
new Thread("Socket Receiver") {
setDaemon(true)
override def run() { receive() }
}.start()
}
def onStop() {
// There is nothing much to do as the thread calling receive()
// is designed to stop by itself isStopped() returns false
}
/** Create a socket connection and receive data until receiver is stopped */
def receive() {
var socket: Socket = null
try {
logInfo("Connecting to " + host + ":" + port)
socket = new Socket(host, port)
logInfo("Connected to " + host + ":" + port)
val iterator = bytesToObjects(socket.getInputStream())
while(!isStopped && iterator.hasNext) {
store(iterator.next)
}
if (!isStopped()) {
restart("Socket data stream had no more data")
} else {
logInfo("Stopped receiving")
}
} catch {
case e: java.net.ConnectException =>
restart("Error connecting to " + host + ":" + port, e)
case NonFatal(e) =>
logWarning("Error receiving data", e)
restart("Error receiving data", e)
} finally {
if (socket != null) {
socket.close()
logInfo("Closed socket to " + host + ":" + port)
}
}
}
}
接下来看JobScheduler.start()中启动的第四项工作JobGenerator。
JobGenerator有成员RecurringTimer,用于
启动消息系统和定时器。按照batchInterval时间间隔定期发送GenerateJobs消息。
//根据创建StreamContext时传入的batchInterval,定时发送GenerateJobs消息
private val timer = new RecurringTimer(clock, ssc.graph.batchDuration.milliseconds,
longTime => eventLoop.post(GenerateJobs(new Time(longTime))), "JobGenerator")
JobGenerator的start()方法:
/** Start generation of jobs */
def start(): Unit = synchronized {
if (eventLoop != null) return // generator has already been started
// Call checkpointWriter here to initialize it before eventLoop uses it to avoid a deadlock.
// See SPARK-10125
checkpointWriter
eventLoop = new EventLoop[JobGeneratorEvent]("JobGenerator") {
override protected def onReceive(event: JobGeneratorEvent): Unit = processEvent(event)
override protected def onError(e: Throwable): Unit = {
jobScheduler.reportError("Error in job generator", e)
}
}
// 启动消息循环处理线程
eventLoop.start()
if (ssc.isCheckpointPresent) {
restart()
} else {
// 开启定时生成Job的定时器
startFirstTime()
}
}
JobGenerator.start()中的startFirstTime()的定义:
/** Starts the generator for the first time */
private def startFirstTime() {
val startTime = new Time(timer.getStartTime())
graph.start(startTime - graph.batchDuration)
timer.start(startTime.milliseconds)
logInfo("Started JobGenerator at " + startTime)
}
JobGenerator.start()中的processEvent()的定义:
/** Processes all events */
private def processEvent(event: JobGeneratorEvent) {
logDebug("Got event " + event)
event match {
case GenerateJobs(time) => generateJobs(time)
case ClearMetadata(time) => clearMetadata(time)
case DoCheckpoint(time, clearCheckpointDataLater) =>
doCheckpoint(time, clearCheckpointDataLater)
case ClearCheckpointData(time) => clearCheckpointData(time)
}
}
其中generateJobs的定义:
/** Generate jobs and perform checkpoint for the given `time`. */
private def generateJobs(time: Time) {
// Set the SparkEnv in this thread, so that job generation code can access the environment
// Example: BlockRDDs are created in this thread, and it needs to access BlockManager
// Update: This is probably redundant after threadlocal stuff in SparkEnv has been removed.
SparkEnv.set(ssc.env)
Try {
// 根据特定的时间获取具体的数据
jobScheduler.receiverTracker.allocateBlocksToBatch(time) // allocate received blocks to batch
//调用DStreamGraph的generateJobs生成Job
graph.generateJobs(time) // generate jobs using allocated block
} match {
case Success(jobs) =>
val streamIdToInputInfos = jobScheduler.inputInfoTracker.getInfo(time)
jobScheduler.submitJobSet(JobSet(time, jobs, streamIdToInputInfos))
case Failure(e) =>
jobScheduler.reportError("Error generating jobs for time " + time, e)
}
eventLoop.post(DoCheckpoint(time, clearCheckpointDataLater = false))
}
/** Perform checkpoint for the give `time`. */
private def doCheckpoint(time: Time, clearCheckpointDataLater: Boolean) {
if (shouldCheckpoint && (time - graph.zeroTime).isMultipleOf(ssc.checkpointDuration)) {
logInfo("Checkpointing graph for time " + time)
ssc.graph.updateCheckpointData(time)
checkpointWriter.write(new Checkpoint(ssc, time), clearCheckpointDataLater)
}
}
DStreamGraph的generateJobs方法,调用输出流的generateJob方法来生成Jobs集合。
// 输出流:具体Action的输出操作
private val outputStreams = new ArrayBuffer[DStream[_]]()
def generateJobs(time: Time): Seq[Job] = {
logDebug("Generating jobs for time " + time)
val jobs = this.synchronized {
outputStreams.flatMap { outputStream =>
val jobOption = outputStream.generateJob(time)
jobOption.foreach(_.setCallSite(outputStream.creationSite))
jobOption
}
}
logDebug("Generated " + jobs.length + " jobs for time " + time)
jobs
}
来看下DStream的generateJob方法,调用getOrCompute方法来获取当Interval的时候,DStreamGraph会被BatchData实例化成为RDD,如果有RDD则封装jobFunc方法,里面包含context.sparkContext.runJob(rdd, emptyFunc),然后返回封装后的Job。
/**
* Generate a SparkStreaming job for the given time. This is an internal method that
* should not be called directly. This default implementation creates a job
* that materializes the corresponding RDD. Subclasses of DStream may override this
* to generate their own jobs.
*/
private[streaming] def generateJob(time: Time): Option[Job] = {
getOrCompute(time) match {
case Some(rdd) => {
val jobFunc = () => {
val emptyFunc = { (iterator: Iterator[T]) => {} }
context.sparkContext.runJob(rdd, emptyFunc)
}
Some(new Job(time, jobFunc))
}
case None => None
}
}
接下来看JobScheduler的submitJobSet方法,向线程池中提交JobHandler。而JobHandler实现了Runnable 接口,最终调用了job.run()这个方法。看一下Job类的定义,其中run方法调用的func为构造Job时传入的jobFunc,其包含了context.sparkContext.runJob(rdd, emptyFunc)操作,最终导致Job的提交。
def submitJobSet(jobSet: JobSet) {
if (jobSet.jobs.isEmpty) {
logInfo("No jobs added for time " + jobSet.time)
} else {
listenerBus.post(StreamingListenerBatchSubmitted(jobSet.toBatchInfo))
jobSets.put(jobSet.time, jobSet)
jobSet.jobs.foreach(job => jobExecutor.execute(new JobHandler(job)))
logInfo("Added jobs for time " + jobSet.time)
}
}
private class JobHandler(job: Job) extends Runnable with Logging {
import JobScheduler._
def run() {
try {
val formattedTime = UIUtils.formatBatchTime(
job.time.milliseconds, ssc.graph.batchDuration.milliseconds, showYYYYMMSS = false)
val batchUrl = s"/streaming/batch/?id=${job.time.milliseconds}"
val batchLinkText = s"[output operation ${job.outputOpId}, batch time ${formattedTime}]"
ssc.sc.setJobDescription(
s"""Streaming job from <a href="$batchUrl">$batchLinkText</a>""")
ssc.sc.setLocalProperty(BATCH_TIME_PROPERTY_KEY, job.time.milliseconds.toString)
ssc.sc.setLocalProperty(OUTPUT_OP_ID_PROPERTY_KEY, job.outputOpId.toString)
// We need to assign `eventLoop` to a temp variable. Otherwise, because
// `JobScheduler.stop(false)` may set `eventLoop` to null when this method is running, then
// it's possible that when `post` is called, `eventLoop` happens to null.
var _eventLoop = eventLoop
if (_eventLoop != null) {
_eventLoop.post(JobStarted(job, clock.getTimeMillis()))
// Disable checks for existing output directories in jobs launched by the streaming
// scheduler, since we may need to write output to an existing directory during checkpoint
// recovery; see SPARK-4835 for more details.
PairRDDFunctions.disableOutputSpecValidation.withValue(true) {
job.run()
}
_eventLoop = eventLoop
if (_eventLoop != null) {
_eventLoop.post(JobCompleted(job, clock.getTimeMillis()))
}
} else {
// JobScheduler has been stopped.
}
} finally {
ssc.sc.setLocalProperty(JobScheduler.BATCH_TIME_PROPERTY_KEY, null)
ssc.sc.setLocalProperty(JobScheduler.OUTPUT_OP_ID_PROPERTY_KEY, null)
}
}
}
}
Job的代码片段:
private[streaming]
class Job(val time: Time, func: () => _) {
private var _id: String = _
private var _outputOpId: Int = _
private var isSet = false
private var _result: Try[_] = null
private var _callSite: CallSite = null
private var _startTime: Option[Long] = None
private var _endTime: Option[Long] = None
def run() {
_result = Try(func())
}
本课的Spark源码只是用于描述Spark Streaming应用的主要流程,以后还会深入剖析。