SQL-SELECT-检索数据(二)
6. 创建计算字段
什么是计算字段?
如何创建计算字段?
如何从应用层序中使用别名引用它们?
① 拼接字段
计算字段并不实际存在于数据库表中。计算字段是运行时在SELECT语句内创建的。
字段(field)
基本上与列(column)的意思相同,经常互换使用,不过数据库列一般称为列,而术语字段通常与计算字段一起使用。拼接 (concatenate)
将值联结到一起(将一个值附加到另一个值)构成单个值。
在SQL中的SELECT语句中,可以使用一个特殊的操作符来拼接两个列。根据你所使用的DBMS,此操作符可以用加号(+)或两个竖杠(||)表示。在MySQL和MariaDB中,必须使用特使的函数。
SELECT vend_name + '(' + vend_county + ')' FROM Vendors ORDER BY vend_name;去掉计算字段中的空格,用SQL的 RTRIM( ) 函数来完成。
SELECT RTRIM(vend_name) + '(' + RTIRM(vend_country) + ')' FROM Vendors ORDER BY vend_name;RTRIM( )函数去掉右边的所有空格。通过使用RTRIM( ),各个列都进行了整理。
大多数DBMS都支持 :
RTRIM( ) 去掉字符串右边的空格
LTRIM( ) 去掉字符串左边的空格
TRIM( ) 去掉字符串左右两边的空格
使用别名
别名有时也称导出列(derived column),以便应用程序能引用计算字段。
从前面的输出可以看出,SELECT语句可以很好地拼接地址字段。但是,这个新计算列的名字是什么呢?实际上它没有名字,它只是一个值。如果仅在SQL查询工具中查看一下结果,这样没有什么不好。但是,一个未命名的列不能用于客户端应用中,因为客户端没有办法引用它。
为了解决这个问题,SQL支持列别名。别名(alias)是一个字段或值的替换名。别名用AS关键字赋予。
-- 包含指定计算结果的名为vend_title的计算字段,任何客户端都可以按名称应用这个列,就像它是一个实际的列表一样。
SELECT RTRIM(vend_name) + '(' + RTRIM(vend_country)+ ')' AS vend_title FROM vendors ORDER BY vend_name;在MySQL和MariaDB中使用的语句:
SELECT concat(vend_name, '(', vend_country, ')') AS vend_title FROM vendors ORDER BY vend_name;别名的其他用途:常见的用途包括在实际的列表名包含不合法的字符(如空格)时重新命名它,在原来的名字含混或者容易误解时扩充它。
② 执行算术计算
计算字段的另一个常见的用途是对检索出的数据进行算术计算。
-- 计算字段:对检索出的数据进行算术计算
SELECT prod_id, quantity, item_price FROM orderitems WHERE order_num = 20008;
SELECT prod_id, quantity, item_price, quantity*item_price AS expanded_price FROM orderitems WHERE order_num = 20008;7. 使用数据处理函数
什么是函数?
DBMS支持何种函数?
如何使用这些函数?
为什么SQL函数的使用可能会带来问题?
函数一般是在数据上执行的,为数据的转换和处理提供了方便。
与几乎所有DBMS都等同支持SQL语言不同,每一个DBMS都有特定的函数。事实上,只要少数几个函数被所有主要的DBMS等同的支持。虽然所有类型的函数一般都可以在每一个DBMS中使用,但是各个函数的名称和语法可能极其不同。
① 文本处理函数
RTRIM()函数用于去除列值右边的空格。
UPPER()函数用于将文本转换为大写。
SELECT vend_name, UPPER(vend_name) AS vend_name_upcase FROM vendors ORDER BY vend_name;常用文本处理函数:

注:SOUNDEX( ) 是一个将任何文本串转换为描述其语音表示的字母数字模式的算法。
使用SOUNDEX()函数进行搜索,它匹配所有发音类似于Michael Green的联系名:
SELECT cust_name, cust_contact FROM customers WHERE SOUNDEX(cust_contact) = SOUNDEX('Michael Green');WHERE子句使用SOUNDEX()函数把cust_contact列值和搜索字符串转换为它们的SOUNDEX值。因为Michael Green和Michelle Green发音相似,所以它们的SOUNDEX值匹配,因此WHERE子句正确地过滤出了所需的数据。
② 数值处理函数
在主要DBMS的函数中,数值函数是最一致、最统一的函数。
常用数值处理函数:


虽然这些函数在格式化、处理和过滤数据中非常有用,但它们在各种SQL实现中很不一致。
8. 汇总数据
什么是SQL的聚集函数?
如何利用它们汇总表的数据?
SQL 的聚集函数在各种主要SQL实现中得到了相当一致的支持。
聚集函数(aggregate function)对某些行运行的函数,计算并返回一个值。
SQL聚集函数:

① AVG() 函数
通过对表中行数计数并计算其列值之和,求得该列的平均值。AVG() 可用来返回所有列的平均值,也可以用来返回特定列或行的平均值。
AVG()函数忽略列值为NULL的行。
-- products表中所有产品的平均价格
SELECT AVG(prod_price) AS avg_price FROM products;
-- 返回特定供应商所提供产品的平均价格
SELECT AVG(prod_price) AS avg_price FROM products WHERE vend_id = 'DLL01';② COUNT() 函数
计数。确定表中行的数目或符合特定条件的行的数目。
COUNT()函数有两种使用方式:
- 使用COUNT(*)对表中行的数目进行计数,不管表列中包含的是空值(NULL)还是非空值。
- 使用COUNT(column)对特定列中具有值的行进行计数,忽略NULL值。
如果指定列名,则COUNT()函数会忽略指定列的值为空的行,但如果COUNT()函数中用的是星号(*),则不忽略。
-- 返回customers表中顾客的总数: SELECT COUNT(*) AS num_cust
FROM custormers;
-- -------- -- num_cust -- -------- -- 5 -- --------
-- 只对具有电子邮件地址的客户计数 SELECT COUNT(cust_email) AS num_cust
FROM custormers;
-- -------- -- num_cust -- -------- -- 3 -- -------- -- 5个顾客中只有3个顾客有电子邮箱地址③ MAX() 函数
MAX() 返回指定列中的最大值。MAX() 要求指定列名。
MAX()函数忽略列值为NULL的行。在用于文本数据时,MAX()返回按该列排序后的最后一行。
-- MAX()返回表中最贵物品的价格
SELECT MAX(prod_price) AS max_price FROM products;④ MIN() 函数
MIN() 返回指定列的最小值。MIN() 要求指定列名。
MIN()函数忽略列值为NULL的行。在用于文本数据时,MIN()返回该列排序后最前面的行。
-- MIN()返回表中最便宜物品的价格
SELECT MIN(prod_price) AS min_price FROM products;⑤ SUM() 函数
SUM() 用来返回指定列值的和(总计)。
SUM() 函数忽略列值为NULL的行。
-- 检索所订购物品的总数(所有quantity值之和)
SELECT SUM(quantity) AS items_ordered FROM orderItems WHERE order_num = 20005;
-- 某个物品的总订单金额
SELECT SUM(item_price*quantity) AS total_price FROM orderItems WHERE order_num = 20005;利用标准的算术操作符,所有聚集函数都可用来执行多个列上的计算。
聚集不同值
- 对所有行执行操作,指定ALL参数或者不指定参数(因为ALL是默认行为)。
- 只包含不同的值,指定DISTINCT参数。
-- 使用了DISTINCT后,此例子中的avg_price比较高,因为有多个物品具有相同的较低价格。排除它们提升了平均价格
SELECT AVG(DISTINCT prod_price) AS avg_price FROM products WHERE vend_id = 'DLL01';如果指定列名,则DISTINCT只能用于COUNT()。DISTINCT不能用于COUNT(*)。类似地,DISTINCT必须使用列名,不能用于计算或表达式。
组合聚合函数
SELECT 语句可根据需要包含多个聚合函数。
-- 单条SELECT语句执行了4个聚集计算,返回4个值
SELECT COUNT(*) AS num_items, MIN(prod_price) AS price_min, MAX(prod_price) AS price_max, AVG(prod_price) AS price_avg FROM products;
-- ----------------------------------------------------------------
-- num_items price_min price_max p rice_avg
-- ---------- --------------- --------------- ---------
-- 9 3.4900 11.9900 6.823333
-- ----------------------------------------------------------------聚集函数用来汇总数据。SQL支持5个聚集函数,可以用多种方法使用它们,返回所需的结果。这些函数很高效,它们返回结果一般比你在自己的客户端应用程序中计算要快得多。
9. 分组数据
如何分组数据,以便汇总表内容的子集?
利用GROUP BY子句 和 HAVING 子句
① 创建分组
GROUP BY子句
-- 返回供应商DLL01提供的产品数目:
SELECT COUNT(*) AS num_prods FROM products WHERE vend_id = 'DLL01'; -- 返回每个供应商提供的产品数目 SELECT vend_id, COUNT(*) AS num_prods FROM products GROUP BY vend_id;
-- 因为使用了GROUP BY,就不必指定要计算和估计的每个组了。系统会自动完成。GROUP BY子句指示DBMS分组数据,然后对每个组而不是整个结果进行聚集。注意:
1. GROUP BY子句必须出现在WHERE子句之后, ORDER BY 子句之前。
2. 如果分组列中包含具有NULL值的行,则NULL将作为一个分组返回。如果列中有多行NULL值,它们将分为一组。
3. 除了聚集计算语句外,SELECT语句中的每一列都必须在GROUP BY子句中给出。
② 过滤分组
HAVING 子句
WHERE过滤行,而HAVING过滤分组。HAVING支持所有WHERE操作符(包括通配符条件和带多个操作符的子句)。
-- 列出至少有两个订单的所有客户
SELECT cust_id, COUNT(*) AS num_orders FROM Orders GROUP BY cust_id HAVING COUNT(*) >= 2;HAVING和WHERE的差别:WHERE在数据分组前进行过滤,HAVING在分组后进行过滤。这是一个重要的区别,WHERE排除的行不包括在分组中。这可能会改变计算值,从而影响HAVING子句中基于这些值过滤掉的分组。
-- 列出具有两个以上 产品且其大于等于4 的供应商 SELECT vend_id, COUNT(*) AS num_vend
FROM products
WHERE prod_price >= 4
GROUP BY vend_id
HAVING COUNT(*) >= 2
-- ----------------------- -- vend_id num_prods -- ------- ----------- -- BRS01 3 -- FNG01 2 -- -----------------------
-- 若没有WHERE, 则会多检索一行(供应商DLL01,销售4个产品,价格都在4 以下) SELECT vend_id, COUNT(*) AS num_vend
FROM products
GROUP BY vend_id
HAVING COUNT(*) >= 2
-- ----------------------- -- vend_id num_prods -- ------- ----------- -- BRS01 3 -- DLL01 4 -- FNG01 2 -- -----------------------使用HAVING时应该结合GROUP BY子句,而WHERE子句用于标准的行级过滤。
③ 分组和排序
GROUP BY 和 ORDER BY 经常完成相同的工作,但它们非常不同。差别如下表:

一般在使用GROUP BY 子句时,应该也给出ORDER BY子句。这是保证数据正确排序的唯一方法。千万不要仅依赖GROUP BY排序数据。
-- 检索包含三个或更多物品的订单和订购物品数目
SELECT order_num, COUNT(*) AS num FROM OrderItems GROUP BY order_num HAVING COUNT(*) >= 3;
-- 检索包含三个或更多物品的订单和订购物品数目 使用ORDER BY
SELECT order_num, COUNT(*) AS num FROM OrderItems GROUP BY order_num HAVING COUNT(*) >= 3
ORDER BY num, order_num;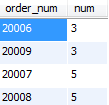
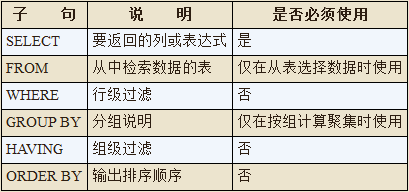
SELECT 子句顺序
10. 使用子查询
什么是子查询?
如何使用它们?
子查询(subquery):嵌套在其他查询中的查询。
子查询常用于WHERE子句的IN操作符中,以及用来填充计算列。
① 利用子查询进行过滤
在SELECT语句中,子查询总是由内向外处理。
列出订购物品RGAN01的所有顾客。
1. 检索出包含物品RGAN01的所有订单的编号。
2. 检索具有前一步骤列出的订单编号的所有顾客的ID。
3. 检索前一步骤返回的所有顾客ID的顾客信息。
SELECT order_num FROM OrderItems WHERE prod_id = 'RGAN01';
SELECT cust_id FROM Orders WHERE order_num IN ('20007','20008');
SELECT cust_name, cust_contact FROM Customers WHERE cust_id IN ('1000000004','1000000005');
--利用子查询
SELECT cust_name, cust_contact FROM Customers WHERE cust_id IN (SELECT cust_id FROM Orders WHERE order_num IN (SELECT order_num FROM OrderItems WHERE prod_id = 'RGAN01'));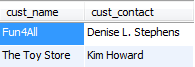
注:
1. 作为子查询的SELECT语句只能查询单个列。企图检索多个列将返回错误。
2. 使用子查询并不是执行这类数据检索最有效的方法。可以使用联结。
② 作为计算字段使用子查询
需要显示Customers表中每个顾客的订单总数。订单与相应的顾客ID存储在Orders表中。
1. 从Customers表中检索顾客列表。
2. 对于检索出的每个顾客,统计其在Orders表中的订单数目。
SELECT COUNT(*) AS orders FROM Orders WHERE cust_id = '1000000001';
-- 使用子查询
SELECT cust_name, cust_address, (SELECT COUNT(*) AS orders FROM Orders WHERE orders.cust_id = Customers.cust_id) AS orders FROM Customers ORDER BY cust_name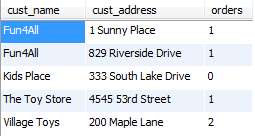
完全限定列名:如果在SELECT语句中操作多个表,就应使用完全限定列名来避免奇异。
不止一种解决方案:可以使用JOIN来解决这样的问题。