Spark性能优化:JVM参数调优
关于JVM垃圾回收种类
Minor GC
从年轻代空间(包括 Eden 和 Survivor 区域)回收内存被称为 Minor GC。这一定义既清晰又易于理解。但是,当发生Minor GC事件的时候,有一些有趣的地方需要注意到:
当 JVM 无法为一个新的对象分配空间时会触发 Minor GC,比如当 Eden 区满了。所以分配率越高,越频繁执行 Minor GC。
内存池被填满的时候,其中的内容全部会被复制,指针会从0开始跟踪空闲内存。Eden 和 Survivor 区进行了标记和复制操作,取代了经典的标记、扫描、压缩、清理操作。所以 Eden 和 Survivor 区不存在内存碎片。写指针总是停留在所使用内存池的顶部。
执行 Minor GC 操作时,不会影响到永久代。从永久代到年轻代的引用被当成 GC roots,从年轻代到永久代的引用在标记阶段被直接忽略掉。
质疑常规的认知,所有的 Minor GC 都会触发“全世界的暂停(stop-the-world)”,停止应用程序的线程。对于大部分应用程序,停顿导致的延迟都是可以忽略不计的。其中的真相就 是,大部分 Eden 区中的对象都能被认为是垃圾,永远也不会被复制到 Survivor 区或者老年代空间。如果正好相反,Eden 区大部分新生对象不符合 GC 条件,Minor GC 执行时暂停的时间将会长很多。
所以 Minor GC 的情况就相当清楚了——每次 Minor GC 会清理年轻代的内存。
Major GC vs Full GC
大家应该注意到,目前,这些术语无论是在 JVM 规范还是在垃圾收集研究论文中都没有正式的定义。但是我们一看就知道这些在我们已经知道的基础之上做出的定义是正确的,Minor GC 清理年轻带内存应该被设计得简单:
Major GC 是清理永久代。
Full GC 是清理整个堆空间—包括年轻代和永久代。
很不幸,实际上它还有点复杂且令人困惑。首先,许多 Major GC 是由 Minor GC 触发的,所以很多情况下将这两种 GC 分离是不太可能的。另一方面,许多现代垃圾收集机制会清理部分永久代空间,所以使用“cleaning”一词只是部分正确。
这使得我们不用去关心到底是叫 Major GC 还是 Full GC,大家应该关注当前的 GC 是否停止了所有应用程序的线程,还是能够并发的处理而不用停掉应用程序的线程。
这种混乱甚至内置到 JVM 标准工具。下面一个例子很好的解释了我的意思。让我们比较两个不同的工具 Concurrent Mark 和 Sweep collector (-XX:+UseConcMarkSweepGC)在 JVM 中运行时输出的跟踪记录。
依据对象的存活周期进行分类,短命对象归为新生代,长命对象归为老年代。
根据不同代的特点,选取合适的收集算法
新生代:少量对象存活,适合复制算法
老年代:大量对象存活,适合标记清理或者标记压缩
参数文章:关于JVM常用的GC算法

Young:主要是用来存放新生的对象。
Old:主要存放应用程序中生命周期长的内存对象。
Permanent:是指内存的永久保存区域,主要存放Class和Meta的信息,Class在被 Load的时候被放入PermGen space区域. 它和和存放Instance的Heap区域不同,GC(Garbage Collection)不会在主程序运行期对PermGen space进行清理,所以如果你的APP会LOAD很多CLASS的话,就很可能出现PermGen space错误

上图演示新生代GC过程用到的复制算法,黄色表示死对象,绿色表示剩余空间,红色表示幸存对象
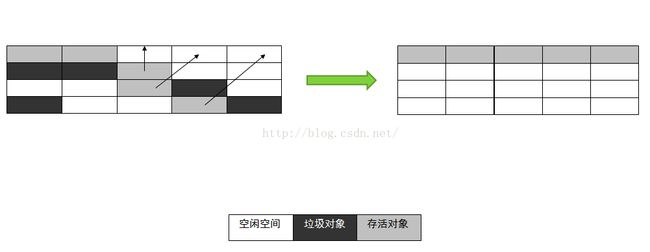
上图演示老年代GC时用到的标记-压缩算法
总结一下,对象一般出生在Eden区,年轻代GC过程中,对象在2个幸存区之间移动,如果对象存活到适当的年龄,会被移动到老年代。当对象在老年代死亡时,就需要更高级别的GC,更重量级的GC算法(复制算法不适用于老年代,因为没有多余的空间用于复制)
Shell提交脚本实例:
#!/bin/bash source /etc/profile nohup /opt/modules/spark/bin/spark-submit \ --master spark://10.130.2.20:7077 \ --conf "spark.executor.extraJavaOptions=-XX:PermSize=8m -XX:SurvivorRatio=4 -XX:NewRatio=4 -XX:+PrintGCDetails -XX:+PrintGCTimeStamps" \ --driver-memory 1g \ --executor-memory 1g \ --total-executor-cores 48 \ --conf "spark.ui.port=8088" \ --jars /opt/bin/sparkJars/kafka_2.10-0.8.2.1.jar,/opt/bin/sparkJars/spark-streaming-kafka_2.10-1.4.1.jar,/opt/bin/sparkJars/metrics-core-2.2.0.jar,/opt/bin/sparkJars /mysql-connector-java-5.1.26-bin.jar,/opt/bin/sparkJars/spark-streaming-kafka_2.10-1.4.1.jar \ --class com.spark.streaming.Top3HotProduct \ SparkApp.jar \ > sparkApp.log 2>&1 & \