一起学Netty(五)之 初识ByteBuf和ByteBuf的常用API
网络传输的载体是byte,这是任何框架谁也逃脱不了的一种规定,JAVA的NIO提供了ByteBuffer,用来完成这项任务,当然ByteBuffer也很好的完成了这个任务,Netty也提供了一个名字很相似的载体叫做ByteBuf,相比于ByteBuf而言,它有着更加更多友善的API,也更加易于维护,并且它可以扩容
一般来说,ByteBuf都是维护一个byte数组的,它的内部格式是长成这个样子的
* +-------------------+------------------+------------------+ * | discardable bytes | readable bytes | writable bytes | * | | (CONTENT) | | * +-------------------+------------------+------------------+ * | | | | * 0 <= readerIndex <= writerIndex <= capacity
与原生态的ByteBuffer相比,它维护了两个指针,一个是读指针,一个是写指针,而原生态的ByteBuffer只维护了一个指针,你需要调用flip方法来切换读写的状态,不易用户管理维护
读的时候,可读的区域是下标区间是[readerIndex,writeIndex),可写区间的是[writerIndex,capacity-1],但是discardable这段区间就会变得相对无用,既不能读,也不能写
所以我们可以使用discardReadBytes的方法进行内存空间的回收,回收之后是这样的:
* +------------------+--------------------------------------+ * | readable bytes | writable bytes (got more space) | * +------------------+--------------------------------------+ * | | | * readerIndex (0) <= writerIndex (decreased) <= capacity
discardReadBytes之后,可读段被移到了该内存空间的最左端,可写段从空间容量来说,变大了,变成了回收之前的可写段+discard段内存之和,这样做的唯一问题就是性能问题,因为可读段的字节迁移问题,如果大量调用该方法,会产生很多的复制操作,所以除非能获取discard的很大空间,一般情况下,高并发的情况下,不适合多调用
当然还有clear方法,这个方法简单易懂,调用之前ByteBuf是长成这样的:
* +-------------------+------------------+------------------+ * | discardable bytes | readable bytes | writable bytes | * +-------------------+------------------+------------------+ * | | | | * 0 <= readerIndex <= writerIndex <= capacity调用完之后是长成这样的:
* +---------------------------------------------------------+ * | writable bytes (got more space) | * +---------------------------------------------------------+ * | | * 0 = readerIndex = writerIndex <= capacity
ByteBuf除了discardReadBytes和clear方法之外,还提供了大量的丰富的读写方法,此处就不一一列举了
还有几个比较重要的API,这里也说明一下
1)duplicate方法:复制当前对象,复制后的对象与前对象共享缓冲区,且维护自己的独立索引
2)copy方法:复制一份全新的对象,内容和缓冲区都不是共享的
3)slice方法:获取调用者的子缓冲区,且与原缓冲区共享缓冲区
关于ByteBuf一些比较重要的API的认识就是这些,因为我目前还没有使用的一些心得,希望以后有机会分享
我们再来看看ByteBuf的继承关系图:
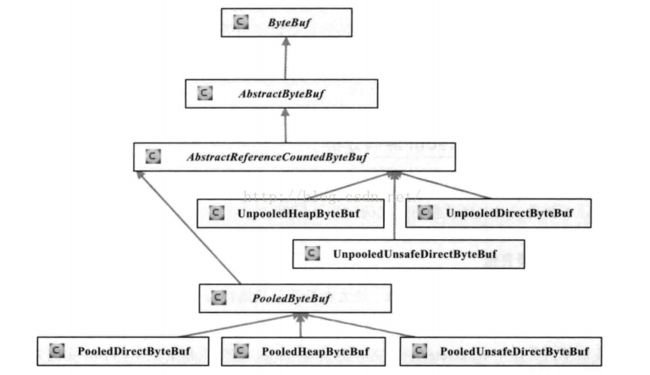


强行盗了三张图,不管是从什么角度来分析,ByteBuf说到底还是维护了一个字节数组
目前为止,Netty提供来的ByteBuf都是堆内内存,大概是因为我们平时写的都是channel,写的是业务逻辑的代码
我们可以看到堆外内存分配的源代码:
DirectByteBuffer(int cap) { // package-private
super(-1, 0, cap, cap);
boolean pa = VM.isDirectMemoryPageAligned();
int ps = Bits.pageSize();
long size = Math.max(1L, (long)cap + (pa ? ps : 0));
Bits.reserveMemory(size, cap);
long base = 0;
try {
base = unsafe.allocateMemory(size);
} catch (OutOfMemoryError x) {
Bits.unreserveMemory(size, cap);
throw x;
}
unsafe.setMemory(base, size, (byte) 0);
if (pa && (base % ps != 0)) {
// Round up to page boundary
address = base + ps - (base & (ps - 1));
} else {
address = base;
}
cleaner = Cleaner.create(this, new Deallocator(base, size, cap));
att = null;
}
并且在我们平时的普通开发中,用的也是Unpool类型的普通ByteBuf,但是在一些高并发的应用中,Pooled化的ByteBuf性能会更加优秀
关于ByteBuf初步的了解就这么多了,先暂时分享一下,希望以后能有其他的使用体会